Спецификация HTML 4.01
Категоризация ячеек
11.4.2 Категоризация ячеек
Пользователи, просматривающие таблицы с помощью речевого ПА, могут дополнительно пожелать услышать разъяснение о содержимом ячейки. Один из методов получить разъяснение состоит в прослушивании ассоциированной заголовочной информации перед прослушиванием содержимого ячеек данных (см. раздел ассоциирование заголовочной информации с ячейками данных).
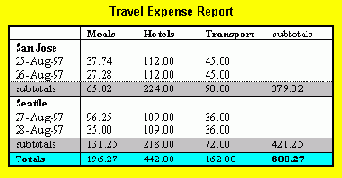
Пользователей может также заинтересовать информация о более чем одной ячейке. В этом случае заголовочная информация, даваемая на уровне ячейки (атрибутами headers, scope и abbr), не может предоставить адекватный контекст. Рассмотрим таблицу, классифицирующую цены на еду, отели и транспорт в двух городах (Сан-Хосе и Сиэтл) за несколько дней:
Пользователю может понадобиться извлечь информацию из таблицы в форме запроса:
- "What did I spend for all my meals?"
- "What did I spend for meals on 25 August?"
- "What did I spend for all expenses in San Jose?"
Каждый запрос вызывает вычисления ПА, в которых могут быть задействованы ноль или более ячеек. Чтобы определить, например, стоимость питания 25 августа, ПА должен знать, какая ячейка ссылается на "Meals" (все) и какая ссылается на "Dates" (конкретно, на 25 августа), и найти пересечение двух наборов (данных).
Чтобы приспособить этот тип запроса, табличная модель HTML 4 позволяет авторам разместить заголовки ячеек и данные по категориям. Например, по таблице цен на проезд автор мог бы сгруппировать заголовочные ячейки "San Jose" и "Seattle" в категорию "Location", заголовки "Meals", "Hotels" и "Transport" - в категорию "Expenses", а 4 дня в категорию "Date". Предыдущие три вопроса получат тогда следующие значения:
- "What did I spend for all my meals?" означает "Каковы все ячейки данных в категории "Expenses=Meals"?
- "What did I spend for meals on 25 August?" означает "Каковы все ячейки данных в категориях "Expenses=Meals" и "Date=Aug-25-1997"?
- "What did I spend for all expenses in San Jose?" означает "Каковы все ячейки данных в категориях "Expenses=Meals, Hotels, Transport" и "Location=San Jose"?
Авторы категоризируют ячейки заголовков или данных установкой атрибута axis для ячейки. К примеру, в таблице затрат на проезд, ячейка, содержащая информацию "San Jose" может быть помещена в категорию "Location" так:
<TH id="a6" axis="location">San Jose</TH>любая ячейка, содержащая информацию со ссылкой на "San Jose", должна ссылаться на эту заголовочную ячейку через атрибуты headers или scope.
Таким образом, затраты на питание 25 августа должны быть помечены так, чтобы ссылаться на атрибут id
(значение которого - "a6") заголовочной ячейки "San Jose":
Каждый атрибут headers предоставляет список ссылок на id. Авторы могут таким образом категоризировать данные ячейки любыми способами.
Ниже мы разметим таблицу затрат на путешествие с распределением информации по категориям:
<TABLE border="1" summary="This table summarizes travel expenses incurred during August trips to San Jose and Seattle"> <CAPTION> Travel Expense Report </CAPTION> <TR> <TH></TH> <TH id="a2" axis="expenses">Meals</TH> <TH id="a3" axis="expenses">Hotels</TH> <TH id="a4" axis="expenses">Transport</TH> <TD>subtotals</TD> </TR> <TR> <TH id="a6" axis="location">San Jose</TH> <TH></TH> <TH></TH> <TH></TH> <TD></TD> </TR> <TR> <TD id="a7" axis="date">25-Aug-97</TD> <TD headers="a6 a7 a2">37.74</TD> <TD headers="a6 a7 a3">112.00</TD> <TD headers="a6 a7 a4">45.00</TD> <TD></TD> </TR> <TR> <TD id="a8" axis="date">26-Aug-97</TD> <TD headers="a6 a8 a2">27.28</TD> <TD headers="a6 a8 a3">112.00</TD> <TD headers="a6 a8 a4">45.00</TD> <TD></TD> </TR> <TR> <TD>subtotals</TD> <TD>65.02</TD> <TD>224.00</TD> <TD>90.00</TD> <TD>379.02</TD> </TR> <TR> <TH id="a10" axis="location">Seattle</TH> <TH></TH> <TH></TH> <TH></TH> <TD></TD> </TR> <TR> <TD id="a11" axis="date">27-Aug-97</TD> <TD headers="a10 a11 a2">96.25</TD> <TD headers="a10 a11 a3">109.00</TD> <TD headers="a10 a11 a4">36.00</TD> <TD></TD> </TR> <TR> <TD id="a12" axis="date">28-Aug-97</TD> <TD headers="a10 a12 a2">35.00</TD> <TD headers="a10 a12 a3">109.00</TD> <TD headers="a10 a12 a4">36.00</TD> <TD></TD> </TR> <TR> <TD>subtotals</TD> <TD>131.25</TD> <TD>218.00</TD> <TD>72.00</TD> <TD>421.25</TD> </TR> <TR> <TH>Totals</TH> <TD>196.27</TD> <TD>442.00</TD> <TD>162.00</TD> <TD>800.27</TD> </TR> </TABLE>Обратите внимание, что такая разметка таблицы позволяет также ПА исключить получение пользователем нежелательной информации. Например, если речевой синтезатор назвал бы все позиции в столбце "Meals" этой таблицы в ответ на запрос "What were all my meal expenses?", пользователь не смог бы отличить ежедневные затраты от общих. Внимательно категоризируя данные в ячейках, авторы позволяют ПА выполнить важное семантическое различение при выводе информации.
Конечно, нет никаких ограничений по категоризации информации таблицы. В таблице затрат на путешествие, например, мы могли бы добавить дополнительные категории "subtotals" и "totals".
Эта спецификация не требует от ПА обрабатывать информацию, предоставленную атрибутом axis, как и не даёт каких-либо рекомендаций, как ПА могут представлять пользователям информацию в axis или как пользователи могут запрашивать ПА об этой информации.
Однако ПА, в особенности речевые синтезаторы, могут выносить за скобки информацию, обычную для некоторых ячеек, которые являются результатом выполнения запроса. Например, если пользователь спрашивает "What did I spend for meals in San Jose?", ПА мог бы сначала определить ячейки для вопроса (25-Aug-1997: 37.74, 26-Aug-1997:27.28), а затем отобразить эту информацию. Речевой ПА смог бы прочитать эту информацию:
Location: San Jose. Date: 25-Aug-1997. Expenses, Meals: 37.74 Location: San Jose. Date: 26-Aug-1997. Expenses, Meals: 27.28или более компактно:
San Jose, 25-Aug-1997, Meals: 37.74 San Jose, 26-Aug-1997, Meals: 27.28И даже более экономно - можно было бы убрать общую информацию и реорганизовать её:
San Jose, Meals, 25-Aug-1997: 37.74 26-Aug-1997: 27.28ПА, поддерживающие такой тип представления, должны иметь способность настраивать представление (напр., с помощью таблиц стилей).