Архитектура памяти Windows
Создание самомодифицирующегося кода требует знания некоторых тонкостей архитектуры Windows, не очень-то хорошо освященных в документации. Точнее, совсем не освященных, но от этого отнюдь не приобретающих статус "недокументированных особенностей", поскольку, во-первых, они одинаково реализованы на всех Windows-платформах, а во-вторых, их активно использует компилятор Visual C++ от Microsoft. Отсюда следует, что никаких изменений даже в отдаленном будущем компания не планирует; в противном случае код, сгенерированный этим компилятором, откажет в работе, а на это Microsoft не пойдет (вернее, не должна пойти, если верить здравому смыслу).
Для адресации четырех гигабайт виртуальной памяти, выделенной в распоряжение процесса, Windows используют два селектора, один из которых загружается в сегментный регистр CS, а другой – в регистры DS, ES и SS. Оба селектора ссылаются на один и тот же базовый адрес памяти, равный нулю, и имеют идентичные лимиты, равные четырем гигабайтам. (Замечание: помимо перечисленных сегментных регистров, Windows еще использует и регистр FS, в который загружает селектор сегмента, содержащего информационный блок потока – TIB).
Фактически существует всего один
сегмент, вмещающий в себя и код, и данные, и стек процесса. Благодаря этому передача управления коду, расположенному в стеке, осуществляется близким (near) вызовом или переходом, и для доступа к содержимому стека использование префикса "SS" совершенно необязательно. Несмотря на то, что значение регистра CS не равно значению регистров DS, ES и SS, команды MOV dest,CS:[src]; MOV dest,DS:[src] и MOV dest,SS:[src]
в действительности обращаются к одной и той же ячейке памяти.
Отличия между регионами кода, стека и данных заключаются в атрибутах принадлежащих им страниц – страницы кода допускают чтение и исполнение, страницы данных – чтение и запись, а стека – чтение, запись и исполнение
одновременно.
Помимо этого каждая страница имеет специальный флаг, определяющий уровень привилегий, необходимых для доступа к этой странице.
Некоторые страницы, например те, что принадлежат операционной системе, требуют наличия прав супервизора, которыми обладает только код нулевого кольца. Прикладные программы, исполняющиеся в кольце 3, таких прав не имеют, и при попытке обращения к защищенной странице порождают исключение.
Манипулировать атрибутами страниц, равно как и ассоциировать страницы с линейными адресами, может только операционная система или код, исполняющийся в нулевом кольце. В защите Windows 95\Windows 98 имеются люки, позволяющие прикладному коду повысить свои привилегии до супервизора, но выгода от их использования сомнительна, поскольку "привязывает" пользователя к этой операционной системе и не дает возможности проделать тот же трюк на Windows NT\Windows 2000.
Замечание: среди начинающих программистов ходит совершенно нелепая байка о том, что, дескать, если обратится к коду программы командой, предваренной префиксом DS, Windows якобы беспрепятственно позволит его изменить. На самом деле это в корне неверно – обратиться-то она позволит, а вот изменить – нет, каким бы способом ни происходило обращение, т.к., защита работает на уровне физических страниц, а не логических адресов.
Чем мы будем заниматься
На протяжении всей книги мы будем заниматься занимательной интеллектуальной игрой – созданием защитных механизмов и исследованием их стойкости. Скажу сразу - ничего общего со взломом коммерческих программ или кражей денег из банка это не занятие не имеет. Автор искренне надеется, что его читатели – граждане в своей массе законопослушные и обладающие высокой нравственностью люди.
Умение нейтрализовать защиты еще не дает права применять это умение в преступных целях. Какие же цели являются преступными, а какие нет – вопрос, относящийся уже не к хакерству, а юриспруденции в которой автор не силен и все, что может он порекомендовать – если имеются какие-то сомнения на счет правомерности совершения некоторых действий, – обратитесь к юристам.
Однако экспериментировать с вашей личной интеллектуальной собственностью – программами, написанными вами самими, – ни один закон не вправе запретить, да ни один закон этого, собственно, и не запрещает.
А раз так, на плечи – рюкзак, охотничий ножик в карман и – в густой таежный лес…
Что нам понадобиться
Выбор рабочего инструментария – дело сугубо личное и интимное. Тут на вкус и цвет товарищей нет. Поэтому, примите все нижесказанное не как догму, а как рекомендацию к действию. Итак, для чтения книги нам понадобиться:
– отладчик
Soft-Ice версии 3.25 или более старший,
– дизассемблер IDA версии 3.7х (рекомендуется 3.8, а еще лучше 4.x),
– HEX-редактор HIEW любой версии,
– пакеты SDK и DDK (последний не обязателен, но очень желателен),
– операционная система – любая из семейства Windows, но настоятельно рекомендуется Windows 2000,
– любой Си\Си++ и Pascal компилятор по вкусу (в книге подробно описываются особенности компиляторов Microsoft Visual C++, Borland C++, WATCOM C, GNU C, FreePascal, а за основу взят Microsoft Visual C++ 6.0).
Теперь обо всем этом подробнее:
::Soft-Ice. Отладчик Soft-Ice – основное оружие хакера. Хотя, с ним конкурируют бесплатные WINDEB от Microsoft и TRW от LiuTaoTao – Soft-Ice много лучше и удобнее всех их вместе взятых. Для наших экспериментов подойдет практически любая версия Айса, например, автор использует давно апробированную и устойчиво работающую 3.26, замечательно уживающуюся с Windows 2000. Новомодная 4.x не очень-то дружит с моим видеоадаптером (Matrox Millennium G450 для справки) и вообще временами "едет крышей". К тому же, из всех новых возможностей четвертой версии полезна лишь поддержка FPO (Frame point omission – см. "Идентификация локальных стековых переменных") – локальных переменных, напрямую адресуемых через регистр ESP, – бесспорно полезная фишка, но без нее можно и обойтись. Найти Soft-Ice можно и на дисках известного происхождения, и у российского дистрибьютора - http://www.quarta.ru/bin/soft/winntutils/softicent.asp?ID=59. Купите, не пожалеете (хакерство это ведь не то же самое, что пиратство и честность еще никто не отменял).
::IDA Pro. Бесспорно самый мощный дизассемблер в мире – это IDA.
Прожить без нее, конечно, можно, но… нужно ли? IDA обеспечивает удобную навигацию по исследуемому тексту, автоматически распознает библиотечные функции и локальные переменные, в том числе и адресуемые через ESP, поддерживает множество процессоров и форматов файлов. Одним словом, хакер без IDA – не хакер. Впрочем, агитации излишни, - единственная проблема: где же эту IDA взять? На пиратских дисках она встречается крайне редко (самая последняя виденная мной версия 3.74, да и то нестабильно работающая), на сайтах в Интернете – еще реже. Фирма-разработчик жестоко пресекает любые попытки несанкционированного распространения своего продукта и единственный надежный путь его приобретения – покупка в самой фирме или у российского дистрибьютора ("GelioSoft Ltd" <gav@geliosoft.mtu-net.ru>). К сожалению, с дизассемблером не распространяется никакой документации (не считая встроенного хелпа – очень короткого и бессистемного), поэтому мне ничего не остается, как порекомендовать собственный трехтомник "Образ мышления – дизассемблер IDA", подробно рассказывающей и о самой IDA, и о дизассемблировании вообще.
::HIEW. "Хьювев" – это не только HEX-редактор, но и дизассемблер, ассемблер и крипт "в одном флаконе". Он не избавит от необходимости приобретения IDA, но с лихвой заменит ее в ряде случаев (IDA очень медленно работает и обидно тратить кучу времени, если все, что нам нужно – посмотреть на препарируемый файл "одним глазком"). Впрочем, основное назначение "хьюева" отнюдь не дизассемблирование, а bit hack – небольшое хирургическое вмешательство в двоичный файл, – обычно вырезание жизненного важного органа защитного механизма, без которого он не может функцилировать.
::SDK (Software Development Kit – комплект прикладного разработчика). Из пакета SDK нам, в первую очередь, понадобится документация по Win32 API и утилита для работы с PE-файлами DUMPBIN. Без документации ни хакерам, ни разработчикам никак не обойтись.
Как минимум, необходимо знать прототипы и назначение основных функций системы. Эту информацию, в принципе, можно почерпнуть и из многочисленных русскоязычных книг по программированию, но ни одна из них не может похвастаться полнотой и глубиной изложения. Поэтому, рано или поздно, вам придется обратиться к SDK. Правда, некоторым перед этим потребуется плотно засесть за английский, поскольку все документация написана именно на английском языке и ждать ее перевода все равно, что караулить у моря погоду (правда, с некоторых времен на сайте Microsoft стало появляться много информации для разработчиков и на русском языке). Где приобрести SDK? Во-первых, SDK входит в состав MSDN, а сам MSDN ежеквартально издается на компакт-дисках и распространяется по подписке (подробнее об условиях его приобретения можно узнать на официальном сайте msdn.Microsoft.com). Во-вторых, MSDN прилагается и к компилятору Microsoft Visual C++ 6.0, правда далеко не в первой свежести. Впрочем, для чтения данной книги его будет вполне достаточно.
::DDK. (Driver Development Kit – комплект разработчика драйверов). Какую пользу может извлечь хакер из пакета DDK? Ну, в первую очередь, он поможет разобраться: как устроены, работают (и ломаются) драйвера. Помимо основополагающей документации и множества примеров, в него входит очень ценный файл NTDDK.h, содержащий определения большинства недокументированных структур и буквально нашпигованный комментариями, раскрывающих некоторые любопытные подробности функционирования системы. Не лишним будет и инструментарий, прилагающийся к DDK. Среди прочего сюда входит и отладчик WINDEB. Весьма неплохой, кстати, отладчик, но все же значительно уступающий Soft-Ice, поэтому и не рассматриваемый в данной книге (но если вы не найдете Айса – сгодится и WINDEB). Не бесполезным окажется ассемблер MASM, на котором собственно и пишутся драйвера, а так же маленькие полезные программки, облегчающие жизнь хакеру. Последнюю версию DKK можно бесплатно скачать с сайта Microsoft, только имейте ввиду, что для NT полный DKK занимает свыше 40 мегабайт в упакованном виде и еще больше места требует на диске.
:: операционная система. Вовсе не собираясь навязывать читателю собственные вкусы и пристрастия, я, тем не менее, настоятельно рекомендую установить именно Windows 2000. Мотивация – это действительно стабильная и устойчиво работающая операционная система, мужественно переносящая все критические ошибки приложений. Специфика работы хакера такова, что хирургические вмешательства в недра программ частенько срывают им "крышу", доводя ломаемое приложение до буйного помешательства с непредсказуемым поведением. ОС Windows 9x, демонстрируя социалистическую солидарность, зачастую очень часто "ложится" рядом с зависшей программой. Порой компьютер приходится перезагружать не один десяток раз за деньпо дню! И хорошо,
если только перезагружать, а не восстанавливать разрушенные сбоем диски (такое,
хотья и редко, но случается). Завесить же Windows 2000 на порядок сложнее, – мне это "удается" не больше пары чаще одного-двух раз за месяц, да и то с недосыпу или по небрежности. Потом, Windows 2000 позволяет загружать Soft-Ice в любой момент без необходимости перезагрузки, что очень удобно! Наконец, весь материал этой книги рассчитан именно на Windows 2000, – а ее отличия от других систем упоминаются далеко не всегда. Все равно, все мы когда-нибудь перейдем на Windows 2000 и забудем о Windows 9x как о страшном сне, так стоит ли хвататься за эту умирающую платформу? К слову сказать, Windows Me это не то же самое, что Windows 2000 и ставить ееMe
на свой компьютер я никому не рекомендую (такое впечатление, что Windows Me вообще не тестировали, а о том, что ее писали садисты – кто ставил, тот поймет – я вообще молчу).
Итак, Худо-бедно разобравшись с инструментарием, поговорим о сером веществе, ибо в его отсутствии весь собранный инструмент бесполезен. Автор предполагаетполагает, что читатель уже знаком с ассемблером и, если не пишет программ на этом языке, то, по крайней мере, представляет себе что такое регистры, сегменты, машинные инструкции и т.д.
В противном случае эта книга рискует показаться через чур сложной и непонятной. Отыщите в магазине любой учебник по ассемблеру (например: В. Юрова "ASSEMBLER – учебник", П.И. Рудакова "Программируем на языке ассемблера IBM PC" или "Assembler – язык неограниченных возможностей" Зубкова С.В) и основательно проштудируйте его.
Помимо значения ассемблера так же потребуется иметь хотя бы общие понятия о функционировании операционной системы. Купите и вдумчиво изучите (если не сделали этого до сих пор) "Windows для профессионалов" Джефри Рихтера {>>>> сноска см "Приложение", "Ошибки Джефри Рихтера"} и (если найдете) "Секреты системного программирования в Windows 95" Мэта Питрека. Хотья,
его книга посвящена Windows 95, частично она справедлива и для Windows 2000. Для знакомства с архитектурой самой же Windows 2000 рекомендуется ознакомиться с шедевром Хелен Кастер "Основы Windows NT" и брошюрой "Недокументированные возможности Windows NT" А.В. Коберниченко.
Касаемо общей теории информатики и алгоритмов – бесспорный авторитет Кнут. Впрочем, на мой вкус монография М. Броя "Информатика" куда лучше, - при том что она намного короче, круг охватываемых ей тем и глубина изложения – намного шире. Зачем хакеру теория информатики? Да куда же без нее! Вот, скажем, встретится ему защита со движком-встроенным эмулятором машины Тьюринга. или Маркова. Слету ее не сломать, - надо как минимум опознать сам алгоритм: что это вообще такое – Тьюринг, Марков, или сеть Петри, а потом затем – отобразить его на язык высокого уровня, дабы в удобочитаемом виде анализировать работу защиты. Куда же тут без теории информатики!
За сим все., Ну, разве что стоит дополнить наш походный рюкзачок паруой
учебников по английскому (они пригодятся, поверьте) и выкачать с сайтов Intel и AMD всю имеющуюся там документацию по процессорам. На худой конец подойдет и ее русский перевод, например, Ровдо А.А. "Микропроцессоры от 8086 до Pentium III Xeon и AMD K6-3".
Ну-с, рюкзачок на плечо и в путь…
Досадные описки и ляпы
1) "Флаг HANDLE_FLAG_PROTECT_FROM_CLOSE [передаваемый функции SetHandleInformation – KK] сообщает системе, что данный описать закрывать нельзя… Если какой-нибудь поток попытается закрыть защищенный описатель, CloseHandle приведет к исключению" стр. 15
Какое – такое – исключение? CloseHandle всего лишь вернет NULL, сигнализируя об ошибке…
2) "DuplicateHandle(GetCurrentProcess, hObjProcessA, hObjProcessB, &hObjProcessB….)" стр. 21
Опечатка – третий аргумент должен быть hProcessB.
3) "Кроме адресного пространства, процессу принадлежат такие ресурсы как файлы…" стр. 23.
Файл – объект ядра и принадлежит ядру, но не процессу.
4) "В Windows 95 функции CreateFileMapping можно передать флаг PAGE_WRITECOPY…" стр. 170
Пропущено слово "только", ибо других флагов Windows 95, увы, не поддерживает!
5) "PAGE + WRITECOPY" стр. 174
Досадная опечатка – конечно же должно быть PAGE_WRITECOPY.
6) "Обычно критические секции представляют собой набор глобальных переменных" стр. 220.
Критические секции – не переменные! Структуры CRITICAL_SECTION, передаваемые им, действительно часто хранятся в глобальных переменных, но это – дурной тон и гораздо лучше размещать их в куче или структуре данных, передаваемой синхронизуемым потокам через lpvThreadParam.
7) "имена файлов и каталогов могут включать буквы разного регистра, но при поиске файлов и каталогов регистр букв не учитывается. Если файл с именем ReadMe.txt уже существует, создание нового файла с именем README.TXT уже не допускается" стр. 416
Тут Рихтер противоречит сам себе – страницей назад от утверждал, что NTFS различает регистр символов, а главой вперед – чтобы заставить ее делать это, достаточно воспользоваться флагом FILE_FLAG_POSIX_SEMANTICS.
8) "…система создает для нового процесса виртуального адресное пространство размером 4 Гб и загружает в него код и данные как для исполняемого файла, так и для любых DLL" стр. 36
Не загружает, а проецирует. Разница принципиальна! Загрузка подразумевает считывание с диска и записи в память, но Windows поступает умнее – исполняемый файл и DLL трактуются как часть виртуальной памяти (о чем позднее сам же Рихтер и рассказывает в главе "Проецируемые в память файлы").
Елей и деготь оптимизирующих компиляторов
Применяя языки высокого уровня для разработки выполняемого в стеке кода, следует учитывать особенности реализаций используемых компиляторов и, прежде чем останавливать свой выбор на каком-то одном из них, - основательно изучить прилагаемую к ним документацию. В большинстве случаев код функции, скопированный в стек, с первой попытки запустить не получится, особенно если включены опции оптимизированной компиляции.
Так происходит потому, что на чистом
языке высокого уровня, таком как Си или Паскаль, скопировать код функции в стек (или куда-то еще) принципиально невозможно, поскольку, стандарты языка не оговаривают, каким именно образом должна осуществляется компиляция. Программист может получить указатель на функцию, но стандарт не оговаривает, как следует ее интерпретировать – с точки зрения программиста она представляет "магическое число" в назначение которого посвящен один лишь компилятор.
К счастью, логика кодогенерации большинства компиляторов более или менее одинакова, и это позволяет прикладной программе сделать некоторые предположения об организации откомпилированного кода.
В частности, программа, приведенная в листинге 2, молчаливо полагает, что указатель на функцию совпадает с точкой входа в эту функцию, а все тело функции расположено непосредственно за точкой входа. Именно такой код (наиболее очевидный с точки зрения здравого смысла) и генерирует подавляющее большинство компиляторов. Большинство, но не все! Тот же Microsoft Visual C++ в режиме отладки вместо функций вставляет "переходники", а сами функции размешает совсем в другом месте. В результате, в стек копируется содержимое "переходника", но не само тело функции! Заставить Microsoft Visual C++ генерировать "правильный" код можно сбросом флажка "Link incrementally". У других компиляторов название этой опции может значительно отличаться, а в худшем случае – вообще отсутствовать. Если это так – придется отказаться либо от самомодифицирующегося кода, либо от данного компилятора.
Философия стойкости
Однажды один из друзей сказал Катону Старшему: "Какое безобразие, что в Риме тебе до сих пор не воздвигли памятника! Я обязательно позабочусь об этом".
"Не надо, - ответил Катон, - я предпочитаю, чтобы люди спрашивали, почему нет памятника Катону, чем почему он есть.
Т. Мессон
Если защита базируется на одном лишь предположении, что ее код не будет изучен и/или изменен – это плохая защита. Отсутствие исходных текстов отнюдь не является непреодолимым препятствием для изучения и модификации приложения. Современные технологии обратного проектирования позволяют автоматически распознавать библиотечные функции, локальные переменные, стековые аргументы, типы данных, ветвления, циклы и т.д. А в недалеком будущем дизассемблеры, вероятно, вообще научатся генерировать листинги близкие по внешнему виду к языкам высокого уровня.
Но даже сегодня трудоемкость анализа двоичного кода не настолько велика, чтобы надолго остановить злоумышленников. Огромное количество постоянно совершаемых взломов – лучшее тому подтверждение. В идеальном случае знание алгоритма работы защиты не должно влиять на ее стойкость, но это достижимо далеко не всегда. Например, если разработчик серверной программы решит установить в демонстрационной версии ограничение на количество одновременно обрабатываемых соединений (как часто и случается), злоумышленнику достаточно найти инструкцию процессора, осуществляющую такую проверку и удалить ее. Модификации программы можно воспрепятствовать постоянной проверкой контрольной суммы, но опять-таки, код, который вычисляет эту контрольную сумму и сверяет ее с эталоном, может быть найден и удален.
Сколько бы уровней защиты ни существовало, один или миллион, программа может
быть взломана! Это только вопрос времени и усилий. Но в отсутствии реально действующих законов защиты интеллектуальной собственности разработчикам приходится больше полагаться на стойкость своей защиты, чем на помощь правоохранительных органов. Бытует мнение, дескать, что если затраты на нейтрализацию защитного механизма,
будут не ниже стоимости легальной копии, ее никто не будет ломать. Это неверно! Материальный стимул – не единственное, что движет хакером. Гораздо более сильной мотивацией оказывается интеллектуальная борьба (кто умнее: я или автор защиты?), спортивный азарт (кто из хакеров сломает больше всего защит?), любопытство (а как это работает?), повышение своего профессионализма (чтобы научится создавать защиты, сначала нужно научиться их снимать), да и просто интересное времяпровождение (если его нечем занять). Многие молодые люди могут неделями корпеть над отладчиком, снимая защиту с программы стоимостью в несколько долларов, а то и вовсе распространяемой бесплатно (пример, файл - менеджер FAR для жителей России и СНГ абсолютно бесплатен, но это не спасает его взлома).
Целесообразность защиты ограничивается конкуренцией – при прочих равных условиях клиент всегда выбирает незащищенный продукт, даже если защита не ущемляет его прав. В настоящее время спрос на программистов значительно превышает предложение, но в отдаленном будущем разработчикам придется либо сговориться, либо полностью отказаться от защит. И специалисты по защитам будут вынуждены искать себе другую работу.
Это не значит, что данная книга бесполезна, напротив, полученные знания следует применить как можно быстрее, пока в защитах еще не отпала необходимость.
Грубые ошибки автора
1) "Объекты ядра защищены, и процесс, прежде чем оперировать с ними, должен запрашивать разрешение на доступ к ним. Процесс – создатель объекта может предотвратить несанкционированный доступ к этому объекту со стороны другого процесса" стр. 12
Насчет защиты Рихтер немного загнул – она есть только под Windows NT, но даже там (за исключением серверных приложений) обычно не используется. Поэтому, кто угодно может получить доступ к объектам ядра чужого процесса (за исключением системного) вызвав DuplicateHandle или обратившись к набору функций TOOLHELP32 – процесс и знать не будет, что дублируют его дескриптор!
И даже под NT, и даже с установленными атрибутами защиты в адресном пространстве процесса можно исполнить свой код, обращаясь к защищенному дескриптору от имени этого процесса. Делов-то!
Правильнее было бы говорить о защите от непреднамеренного
доступа к дескрипторам чужого процесса.
2) "…согласно принципу неопределенности Гейзенберга, чем точнее определяется один квант, тем больше ошибка в измерении другого" стр. 52
Это не программистская, но все-таки грубая ошибка. Принцип Гейзенберга в моем пересказе звучит так - нельзя одновременно определить координаты и импульс одной частицы, поскольку любое измерение чего бы то ни было невозможно без взаимодействия, а любое такое взаимодействие искажает свойства объекта измерений.
3) "…потоки с более высоким приоритетом всегда вытесняют потоки с более низким приоритетом независимо от того, исполняются последние или нет" стр. 65.
Нет, не исполняются. Во всяком случае, на однопроцессорной машине в каждый момент времени исполняется только один поток и до тех пор пока не истечет отведенный ему квант времени прервать ему некому.
Исключение составляют аппаратные прерывания, обрабатываемые системой, но это совсем другой разговор. А на многопроцессорных машинах за каждым процессором закрепляются "свои" потоки и потоки одного процессора никогда не вытесняют потоки другого.
Правильно сказать так: а) потоки исполняются по очереди в согласии с приоритетом; б) при пробуждении потока он изменяет очередь исполнения, отбирая процессорное время у потоков с более низким приоритетом.
4) "Ни одна Win32-функция не возвращает уровень приоритета потока… Такая ситуация создана преднамеренно. Вспомните, что Microsoft может в любой момент изменить алгоритм распределения процессорного времени…" стр. 71
Неверно. Во-первых, явно пропущено слово "абсолютный", т.к. относительный приоритет автор сам только что получал функцией GetThreadPriority.
Во-вторых, абсолютный приоритет потока (далее по книге базовый) получается алгебраическим сложением с приоритетом процесса, возвращаемого функцией GetPriorityClass.
В-третьих, не надо путать незадокументированность "квантов" процессорного времени с классами приоритетов, значения которых задокументированы самой Microsoft.
5) "Резервируя регион в адресном пространстве, система обеспечивает еще четную кратность размера региона размеру страницы. Так называется единица объема памяти, используемая системой при управлении памятью" стр. 86
Брр… не понял. Если проще – размер страницы всегда степень двойки, размер выделяемого региона всегда кратен размеру страниц, но не обязательно должен быть
четен количеству страниц. Т.е. запрос на выделение трех страниц выделит именно три страницы, а не четыре или две.
Небольшое уточнение – страничная организация памяти - прерогатива в первую очередь процессора, а не системы.
6) "AllocationBase – Идентифицирует базовый адрес региона, включающего в себя адрес, указанный в lpAddress" стр. 117
Нет! В AllocationBase возвращается базовый адрес региона, ранее выделенного VirualAlloc или 0, если регион был выделен как-то иначе или вообще не был выделен.
7) "DLL-модулям куча по умолчанию не предоставляется, и поэтому при их компоновке нельзя применять параметр /HEAP" стр. 202
По умолчанию DLL-модулям выделяется 1 Мб кучи и его можно изменить ключом /HEAP.
Соответствующее поле PE- заголовка послушно изменится, но… этой кучей динамической библиотеке воспользоваться так и не удастся, поскольку стандартный загрузчик ОС всегда игнорирует это поле при подключении DLL.
8) "И последняя причина, по которой имеет смысл использовать в программе раздельные кучи, – локальный доступ… Обращаясь в основном к памяти, локализованной в небольшом диапазоне адресов, Вы снизите вероятность перекачки страниц между оперативной памятью и страничным фреймом" стр. 204
Это верно, но только по отношению к физическим
адресам. Логически же удаленные друг от друга адреса могут ютится и в смежных, и в далеко разнесенных страницах, - это уж как ОС заблагорассудится их скомбинировать.
Если данные занимают размер, превышающий размер страницы (обычно 4 Кб), то за счет фрагментации виртуальной памяти они наверняка окажутся в несмежных страницах, а потому ожидаемое ускорение "вылетит в трубу"!
8) "…поскольку, в операционную систему встроена поддержка синхронизующих объектов никогда не применяете этот метод [далее идет описание метода синхронизации с использованием переменной-флага, устанавливаемой в TRUE синхронизуемым потоком по завершению – КК]" стр. 217
Во-первых, ввиду пропуска Рихтером ключевого слова volatile, предложенный им способ действительно никогда не следует использовать – работать он, скорее всего, не будет. Оптимизирующие компиляторы, увидев цикл a la "while (!myvar)" подумают: раз переменная myvar явным образом не изменяется (во всяком случае в рамках одного потока), так заменим ее константой и перепишем цикл как: "while(1)". Ключевое же слово volatile сообщает компилятору, что переменная может модифицироваться в любой момент времени внешним кодом и "оптимизировать" ее не надо. Между прочим, это – камень преткновения очень многих начинающих программистов. Самое противное – прогон кода под отладчиком (отладочная версия обычно компилируется без оптимизации) работает на "ура", но финальная (оптимизированная) версия упорно не работает!
Во-вторых, не стоит совсем уж отказываться от "ручной" синхронизации потоков. Накручивать пустой цикл в ожидании результатов работы конечно глупо, но вот если в это время заняться чем-нибудь другим, попутно периодически контролируя состояние переменной флага… А, собственно, почему это должен быть именно флаг?! Пусть один поток сообщает в этой переменной другому потоку процент выполненной им работы. Например, загружая файл с дискеты, сети или другого медленного носителя, можно немедленно выводить скаченные данные на экран, если только один поток сообщит другому: какое именно количество на данный момент скачено.
9) "Потом создавал буфер в адресном пространстве своего процесса и помещал в него машинный код, который выполнял такие операции… call LoadLibraryA… Все правильно, я сам брал машинные команды соответствующие каждой инструкции языка ассемблера, и заполнял ими буфер" стр. 624
Вот именно – "команды, соответствующие каждой инструкции языка ассемблера", - т.к. каждой инструкции ассемблера соответствует от одной до нескольких команд процессора. Не все они равнозначны, причем, машинный код, сгенерированный всеми известными мне ассемблерами, неперемещаем, поскольку все вызовы в нем относительны, т.е. аргумент инструкции call представляет собой не смещение функции LoadLibraryA, а разницу ее смещения и смещения конца инструкции call. Поскольку, адрес верхушки стека разнится от одной версии ОС к другой, созданный Рихтером код окажется работоспособен только в той ОС для которой он предназначен, да и то лишь в том случае, если перед ассемблированием использовать директиву ORG xxx, где xxx – смещение начала буфера. (Рихтер об этом вообще ничего не говорит!)
Выходов два – либо формировать машинные команды вручную, принудительно выбирая абсолютную адресацию (всякий ли знает, как это делать?), либо использовать регистровые вызовы, т.е. mov reg, offset LoadLibraryA.; call reg. Кстати, адрес LoadLibraryA – у Рихтера константа, определяющаяся на этапе ассемблирования, но ведь она неодинакова в различных ОС!
10) "…потом я изменил структуру CONTEXT… так, чтобы установить указатель стека на участок памяти перед моим машинным кодом, а указатель команд – на первый байт этого кода" стр. 624
Не совсем так – оба указателя должны быть установлены на начало машинного кода, т.к. стек растет в область меньших адресов и не может затереть код, лежащий после него.
11) "Разрабатывая ThreadFunct, я должен постоянно помнить, что после копирования в удаленное адресное пространство функция будет находиться по виртуальному адресу, который почти наверняка не совпадет с ее адресом в локальном адресном пространстве. Это значит, надо написать функцию, не делающую внешних ссылок! Это очень трудно!" стр. 632
"Не делающую внешних ссылок", - не только литературно, но и технически некорректное выражение. Точнее:
а) все машинные команды этой функции для обращения к коду и переменным самой этой функции должны использовать только относительную адресацию;
б) для обращения к коду и переменным, не принадлежащим этой функции – только абсолютную адресацию;
с) следует отказаться от статических или глобальных переменных, т.к. они размешаются компилятором в сегменте данных локального адресного пространства, но если это позарез необходимо вашей функции – поместимте их в динамически выделяемую память (кучу).
Но и это еще не все! Многие компиляторы могут принудительно вставлять в код неперемещаемые вызовы своих собственных функций. Например, Microsoft Visual C++ для контроля сбалансированности стека до и после вызова функции обращается к служебной процедуре __chkesp. Хорошо, если разработчики компилятора предусмотрели ключи, запрещающие подобную "самодеятельность", но так бывает не всегда.
Поэтому, техника создания перемещаемой функции – тема не одного абзаца, а, как минимум, целой главы и рекомендаций Рихтера явно недостаточно для практического осуществления такого замысла.
12) "Флаг FILE_FLAG_POSIX_SEMANTICS сообщает, что при доступе к файлу следует применить правила POSIX.
Файловые системы, использующие POSIX, чувствительны к регистру в именах файлов… В то же время MS-DOSб 16-разрядная Windows и Win32 к регистру букв в именах файлов не чувствительны. Поэтому, будьте крайне осторожны, используя FILE_FLAG_POSIX_SEMANTICS. Файл, при создании которого установлен этот флаг, может оказаться недоступным из приложений MS-DOS, 16-рязрядной Windows и Win32" стр. 472
Во-первых, Win32 тут явно "третий лишний" – если Win32 поддерживает POSIX этим самым флагом – какие могут быть проблемы? Кстати, по поводу POSIX – его не поддерживает FAT, поэтому файл, созданный на FAT-диске, регистр игнорирует – создаваться-то с указанным регистром символов он создается, но вот возможности создания двух файлов с одинаковыми именами, но разными регистрами нет, помимо этого при открытии файла идентичность регистра не проверяется даже если установлен FILE_FLAG_POSIX_SEMANTICS.
Другое отличие POSIX – обратный (ну, в смысле прямой) наклон черты разделителя, т.е. к файлу "TEST\test" доступ теперь осуществляется так: "TEST/test".
Во-вторых, фраза "может оказаться недоступным" слишком витиевата, чтобы быть полезной. Почему бы ни ответить когда именно он оказывается недоступным? А вот когда. Если на NTFS-диске в одной директории содержится два и более файлов с одинаковыми именами, но разными регистрами, то из-под Windows-16 и MS-DOS виден только первый (в порядке создания) из них. Во всех остальных случаях, файл созданный с флагом FILE_FLAG_POSIX_SEMANTICS, доступен отовсюду – можете не волноваться!
Идентификация аргументов функций
То, что пугает зверя, не пугает человека.
Фрэнк Херберт "Ловец душ"
Идентификация аргументов функций – ключевое звено в исследовании дизассемблерных программ, поэтому, приготовьтесь, что эта глава будет длинной и, возможно, скучной, но ничего не поделаешь – хакерство требует жертв!
Существует три способа передачи аргументов функции: через стек, через регистры и комбинированный
(через стек и регистры одновременно). К этому списку вплотную примыкает и неявная передача аргументов через глобальные переменные, описание которой вынесено в отдельную главу "Идентификация глобальных переменных".
Сами же аргументы могут передаваться либо по значению, либо по ссылке. В первом случае функции передается копия
соответствующей переменной, а во втором – указатель
на саму переменную.
::соглашения о передаче параметров. Для успешной совместной работы вызывающая функция должна не только знать прототип вызываемой, но и "договориться" с ней о способе передачи аргументов: по ссылке или значению, через регистры или через стек? Если через регистры – оговорить какой аргумент в какой регистр помещен, а если через стек – определить порядок занесения аргументов и выбрать "ответственного" за очистку стека от аргументов после завершения вызываемой функции.
Неоднозначность механизма передачи аргументов – одна из причин несовместимости различных компиляторов. Казалось, почему бы ни заставить всех производителей компиляторов придерживаться какой-то одной схемы? Увы, это решение принесет больше проблем, чем решит.
Каждый механизм имеет свои достоинства и недостатки и, что еще хуже, тесно связан с самим языком. В частности, "Сишные" вольности в отношении соблюдения прототипов функцией возможны именно потому, что аргументы из стека выталкивает не вызываемая, а вызывающая функция, которая наверняка "помнит", что она передавала. Например, функции main передаются два аргумента – количество ключей командной строки и указатель на содержащий их массив.
Однако если программа не работает с командной строкой (или получает ключ каким-то иным путем), прототип main может быть объявлен и так: main().
На Паскале бы подобная выходка привела бы либо к ошибке компиляции, либо к краху программы, т.к. в нем стек очищает непосредственно вызываемая функция и, если она этого не сделает (или сделает неправильно, вытолкнув не то же самое количество машинных слов, которое ей было передано), стек окажется не сбалансированным и все рухнет. (Точнее, у материнской функции "слетит" вся адресация локальных переменных, а вместо адреса возврата в стеке окажется, что глюк на душу положит).
Минусом "Сишного" решения является незначительное увеличении размера генерируемого кода, ведь после каждого вызова функции приходится вставлять машинную команду (и порой не одну) для выталкивания аргументов из стека, а у Паскаля эта команда внесена непосредственно в саму функцию и потому встречается в программе один единственный раз.
Не найдя "золотой середины", разработчики компиляторов решили использовать все возможные механизмы передачи данных, а, чтобы справится с проблемой совместимости, стандартизировали каждый из механизмов, введя ряд соглашений.
Си-соглашение (обозначаемое __cdecl) предписывает засылать аргументы в стек справа налево в порядке их объявления, а очистку стека возлагает на плечи вызывающей функции. Имена функций, следующих Си-соглашению, предваряются символом прочерка "_", автоматически вставляемого компилятором. Указатель this (в Си++ программах) передается через стек последним по счету аргументом.
Паскаль-соглашение
(обозначаемое PASCAL) { >>> сноска В настоящее время ключевое слово PASCAL считается устаревшим и выходит из употребления, вместо него можно использовать аналогичное соглашение WINAPI} предписывает засылать аргументы в стек слева направо в порядке их объявления, и возлагает очистку стека на саму вызывающую функцию.
Стандартное соглашение (обозначаемое __stdcall) является гибридом Си- и Паскаль- соглашений.
Аргументы засылаются в стек справа налево, но очищает стек сама вызываемая функция. Имена функций, следующих стандартному соглашению, предваряются символом прочерка "_", а заканчиваются суффиксом "@", за которым следует количество байт передаваемых функции. Указатель this (в Си++ программах) передается через стек последним по счету аргументом.
Соглашения быстрого вызова: Предписывает передавать аргументы через регистры. Компиляторы от Microsoft и Borland поддерживают ключевое слово __fastcall, но интерпретируют его по-разному, а WATCOM С++ вообще не понимает ключевого слова __fastcall, но имеет в "арсенале" своего лексикона специальную прагму "aux", позволяющую вручную выбрать регистры для передачи аргументов (подробнее см. "соглашения о быстрых вызовах – fastcall"). Имена функций, следующих соглашению __fastcall, предваряются символом "@", автоматически вставляемым компилятором.
Соглашение по умолчанию: Если явное объявление типа вызова отсутствует, компилятор обычно использует собственные соглашения, выбирая их по своему усмотрению. Наибольшему влиянию подвергается указатель this, - большинство компиляторов при вызове по умолчанию передают его через регистр. У Microsoft это – ECX, у Borland – EAX, у WATCOM – либо EAX, либо EDX, либо и то, и другое разом. Остальные аргументы так же могут передаться через регистры, если оптимизатор посчитает, что так будет лучше. Механизм передачи и логика выборки аргументов у всех разная и наперед непредсказуемая, - разбирайтесь по ситуации.
::цели и задачи.
При исследовании функции перед исследователем стоят следующее задачи: определить, какое соглашение используется для вызова; подсчитать количество аргументов, передаваемых функции (и/или используемых функцией); наконец, выяснить тип и назначение самих аргументов. Начнем?
Тип соглашения грубо идентифицируется по способу вычистки стека. Если его очищает вызываемая функция - мы имеем c cdecl, в противном случае – либо с stdcall, либо с PASCAL.
Такая неопределенность в отождествлении вызвана тем, что подлинный прототип функции неизвестен и, стало быть, порядок занесения аргументов в стек определить невозможно. Единственная зацепка: зная компилятор и предполагая, что программист использовал тип вызовов по умолчанию, можно уточнить тип вызова функции. Однако в программах под Windows широко используются оба типа вызовов: и PASCAL (он же WINAPI) и stdcall, поэтому, неопределенность по-прежнему остается. Впрочем, порядок передачи аргументов ничего не меняет – имея в наличии и вызывающую, и вызываемую функцию между передаваемыми и принимаемыми аргументами всегда можно установить взаимно однозначность. Или, проще говоря, если действительный порядок передачи аргументов известен (а он и будет известен - см. вызывающую функцию), то знать очередность расположения аргументов в прототипе функции уже ни к чему.
Другое дело – библиотечные функции, прототип которых известен. Зная порядок занесения аргументов в стек, по прототипу можно автоматически восстановить тип и назначение аргументов!
::определение количества и типа передачи аргументов. Как уже было сказано выше, аргументы могут передаваться либо через стек, либо через регистры, либо и через стек, и через регистры сразу, а так же – неявно через глобальные переменные.
Если бы стек использовался только для передачи аргументов, подсчитать их количество было относительно легко. Увы, стек активно используется и для временного хранения регистров с данными. Поэтому, встретив инструкцию заталкивания PUSH, не торопитесь идентифицировать ее как аргумент. Узнать количество байт, переданных функции в качестве аргументов, невозможно, но достаточно легко определить количество байт, выталкиваемых из стека после завершения функции!
Если функция следует соглашению stdcall (или PASCAL) она наверняка очищает стек командой RET n, где n и есть искомое значение в байтах. Хуже с cdecl-функциями. В общем случае за их вызовом следует инструкция "ADD ESP,n" – где n искомое значение в байтах, но возможны и вариации – отложенная очистка стека
или выталкивание аргументов в какой-нибудь свободный регистр (подробнее об этом рассказано в главе "Коварства оптимизирующих компиляторов"). Впрочем, отложим головоломки оптимизации на потом, пока ограничившись лишь кругом не оптимизирующих компиляторов.
Логично предположить, что количество занесенных в стек байт равно количеству выталкиваемых – иначе после завершения функции стек окажется несбалансированным, и программа рухнет (о том, что оптимизирующие компиляторы допускают дисбаланс стека на некотором участке, мы помним, но поговорим об этом потом). Отсюда: количество аргументов равно количеству переданных байт, деленному на размер машинного слова { >>> сноска Под машинным словом понимается не только два байта, но и размер операндов по умолчанию, в 32-разрядном режиме машинное слово равно четырем байтам} Верно ли это? Нет! Далеко не всякий аргумент занимает ровно один элемент стека. Взять тот же тип double, отъедающий восемь байт, или символьную строку, переданную не по ссылке, а по непосредственному значению, - она "скушает" столько байт, сколько захочет… К тому же засылаться в стек строка (как и структура данных, массив, объект) может не командой PUSH, а с помощью MOVS! (Кстати, наличие MOVS – явное свидетельство передачи аргумента по значению)
Если я не успел окончательно вас запутать, то попробуем разложить по полочкам тот кавардак, что образовался в нашей голове. Итак, анализом кода вызывающей функции установить количество переданных через стек аргументов невозможно. Даже количество переданных байт определяется весьма неуверенно. С типом передачи полный мрак. Позже (см. "Идентификация констант и смещений") мы к этому еще вернемся, а пока вот пример: PUSH 0x40404040/CALL MyFuct: 0x404040
– что это: аргумент передаваемый по значению (т.е. константа 0x404040) или указатель на нечто, расположенное по смещению 0x404040
(и тогда, стало быть, передача происходит по ссылке)? Определить невозможно, не правда ли?
Но не волнуйтесь, нам не пришли кранты – мы еще повоюем! Большую часть проблем решает анализ вызываемой функции.
Выяснив, как она манипулирует переданными ей аргументами, мы установим и их тип и количество! Для этого нам придется познакомиться с адресацией аргументов в стеке, но прежде чем приступить к работе, рассмотрим в качестве небольшой разминки следующий пример:
#include <stdio.h>
#include <string.h>
struct XT{
char s0[20];
int x;
};
void MyFunc(double a, struct XT xt)
{
printf("%f,%x,%s\n",a,xt.x,&xt.s0[0]);
}
main()
{
struct XT xt;
strcpy(&xt.s0[0],"Hello,World!");
xt.x=0x777;
MyFunc(6.66,xt);
}
Листинг 56 Демонстрация механизма передачи аргументов
Результат его компиляции компилятором Microsoft Visual C++ с настройками по умолчанию выглядит так:
main proc near ; CODE XREF: start+AFp
var_18 = byte ptr -18h
var_4 = dword ptr -4
push ebp
mov ebp, esp
sub esp, 18h
; Первый PUSH явно относится к прологу функции, а не к передаваемым аргументам
push esi
push edi
; Отсутствие явной инициализации регистров говорит о том, что, скорее всего,
; они просто сохраняются в стеке, а не передаются как аргументы,
; однако если данной функции аргументы передавались не только через стек,
; но и через регистры ESI и EDI, то их засылка в стек вполне может
; преследовать цель передачи аргументов следующей функции
push offset aHelloWorld ; "Hello,World!"
; Ага, а вот здесь явно имеет место передача аргумента – указателя на строку
; (строго говоря, предположительно
имеет место, - см. "Идентификация констант")
; Хотя теоретически возможно временное сохранение константы в стеке для ее
; последующего выталкивания в какой-нибудь регистр, или же непосредственному
; обращению к стеку, ни один из известных мне компиляторов не способен на такие
; хитрости и засылка константы в стек всегда является передаваемым аргументом
lea eax, [ebp+var_18]
; в EAX заносится указатель на локальный буфер
push eax
; EAX
( указатель на локальный буфер) сохраняется в стеке.
; Поскольку, ряд аргументов непрерывен, то после распознания первого аргумента
; можно не сомневаться, что все последующие заносы чего бы то ни было в стек –
; так же аргументы
call strcpy
; Прототип функции strcpy(char
*, char
*) не позволяет определить порядок
; занесения аргументов, однако, поскольку все библиотечные Си-функции
; следует соглашению cdecl, то аргументы заносятся справа налево
; и исходный код выглядел так: strcpy(&buff[0],"Hello,World!")
; Но, может быть, программист использовал преобразование, скажем, в stdcall?
; Крайне маловероятно, – для этого пришлось бы перекомпилировать и саму
; strcpy
– иначе откуда она бы узнала, что порядок занесения аргументов
; изменился? Хотя обычно стандартные библиотеки поставляются с исходными
; текстами их перекомпиляцией практически никто и никогда не занимается
add esp, 8
; Выталкиваем 8 байт из стека. Из этого мы заключаем, что функции передавалось
; два машинных слова аргументов и, следовательно, PUSH ESI
и PUSH EDI
не были
; аргументами функции!
mov [ebp+var_4], 777h
; Заносим в локальную переменную константу 0x777. Это явно константа, а не
; указатель, т.к. у Windows в этой области памяти не могут храниться никакие
; пользовательские данные
sub esp, 18h
; Резервирование памяти для временной переменной. Временные переменные
; в частности создаются при передаче аргументов по значению, поэтому,
; будем готовы к тому, что следующий "товарищ" – аргумент
; (см. "Идентификация регистровых и временных переменных")
mov ecx, 6
; Заносим в ECX константу 0х6. Пока еще не известно зачем.
lea esi, [ebp+var_18]
; Загружаем в ESI указатель на локальный буффер, содержащий скопированную
; строку "Hello, World!"
mov edi, esp
; Копируем в EDI указатель на вершину стека
repe movsd
; вот она – передача строки по значению.
Строка целиком копируется в стек,
; отъедая от него 6*4 байт.
; (6 – значение счетчика ECX, а 4 – размер двойного слова – movsD)
; следовательно, этот аргумент занимает 20 (0x14) байт стекового пространства –
; эта цифра нам пригодится при определении количества аргументов по количеству
; выталкиваемых байт.
; В стек копируются данные с [ebp+var_18], до [ebp+var_18-0x14], т.е.
; с var_18 до var_4. Но ведь в var_4 содержится константа 0x777!
; следовательно, она будет передана функции вместе со строкой.
; Это позволяет нам воссоздать исходную структуру:
; struct x{
; char s0[20]
; int x
; }
; да, функции, выходит, передается структура, а не одна строка!
push 401AA3D7h
push 0A3D70A4h
; Заносим в стек еще два аргумента. Впрочем, почему именно два?
; Это вполне может быть и один аргумент типа int64 или double
; Определить – какой именно по коду вызывающей функции не представляется
; возможным
call MyFunc
; Вызов MyFunc. Прототип функции установить, увы, не удается... Ясно только,
; что первый (слева? справа?) аргумент – структура, а за ним идут либо два int
; либо один int64 или double
; Уточнить ситуацию позволяет анализ вызываемой функции, но мы это отложим
; на потом, - до того как изучим адресацию аргументов в стеке
; Пока же придется прибывать в полной неопределенности
add esp, 20h
; выталкиваем 0x20 байт. Поскольку, 20 байт (0x14) приходится на структуру
; и 8 байт – на два следующих аргумента, получаем 0x14+0x8=0x20, что
; и требовалось доказать.
pop edi
pop esi
mov esp, ebp
pop ebp
retn
sub_401022 endp
aHelloWorld db 'Hello,World!',0 ; DATA XREF: sub_401022+8o
align 4
Листинг 57
Результат компиляции компилятором Borland C++ будет несколько иным и довольно поучительным. Рассмотрим и его:
_main proc near ; DATA XREF: DATA:00407044o
var_18 = byte ptr -18h
var_4 = dword ptr -4
push ebp
mov ebp, esp
add esp, 0FFFFFFE8h
; Ага! Это сложение со знаком минус. Жмем в IDA
<-> и получаем ADD ESP,-18h
push esi
push edi
; Пока все идет как в предыдущем случае
mov esi, offset aHelloWorld ; "Hello,World!"
; А вот тут начинаются различия! Вызов strcpy
как корова языком слизала –
; нету его и все! Причем, компилятор даже не развернул функцию,
; подставляя ее на место вызова, а просто исключил сам вызов!
lea edi, [ebp+var_18]
; Заносим в EDI указатель на локальный буфер
mov eax, edi
; Заносим тот же самый указатель в EAX
mov ecx, 3
repe movsd
movsb
; Обратите внимание: копируется 4*3+1=13 байт. Тринадцать, а вовсе не
; двадцать, как следует из объявления структуры. Это компилятор так
; оптимизировал код, копируя в буфер лишь саму строку, и игнорируя ее
; не инициализированный "хвост"
mov [ebp+var_4], 777h
; Заносим в локальную переменную константу 0x777
push 401AA3D7h
push 0A3D70A4h
; Аналогично. Мы не может определить: чем являются эти два числа –
; одним или двумя аргументами.
lea ecx, [ebp+var_18]
; Заносим в ECX указатель на начало строки
mov edx, 5
; Заносим в EDX константу 5 (пока не понятно зачем)
loc_4010D3: ; CODE XREF: _main+37j
push dword ptr [ecx+edx*4]
; Ой, что это за кошмарный код? Давайте подумаем, начав раскручивать его
; с самого конца. Прежде всего – чему равно ECX+EDX*4? ECX – указатель на
; буфер и с этим все ясно, а вот EDX*4 == 5*4 == 20.
; Ага, значит, мы получаем указатель не на начало строки, а на конец, вернее
; даже не на конец, а на переменную ebp+var_4 (0x18-0x14=0x4).
; Подумаем – если это указатель на саму var_4, то зачем его вычислять таким
; закрученным макаром? Вероятнее всего мы имеем дело со структурой...
; Далее – смотрите, команда push засылает в стек двойное слово,
; хранящееся по этому указателю
dec edx
; Уменьшаем EDX... Вы уже почувствовали, что мы имеем дело с циклом?
jns short loc_4010D3
; вот – этот переход, срабатывающий пока EDX
не отрицательное число,
; подтверждает наше предположение о цикле.
; Да, такой вот извращенной конструкций Borland
передает аргумент - структуру
; функции по значению!
call MyFunc
; Вызов функции... смотрите – нет очистки стека! Да, это последняя вызываемая
; функция и очистки стека не требуется – Borland
ее и не выполняет...
xor eax, eax
; Обнуление результата, возращенного функцией. Borland
так поступает с void
; функциями – они у него всегда возвращают ноль,
; точнее: не они возвращают, а помещенный за их вызовом код, обнуления EAX
pop edi
pop esi
; Восстанавливаем ранее сохраненные регистры EDI
и ESI
mov esp, ebp
; восстанавливаем ESI, - вот почему стек не очищался после вызова последней
; функции!
pop ebp
retn
_main endp
Листинг 58
Обратите внимание – по умолчанию Microsoft C++ передает аргументы справа налево, а Borland C++ - слева направо! Среди стандартных типов вызов нет такого, который, передавая аргументы слева направо, поручал бы очистку стека вызывающей функции! Выходит, что Borland C++ использует свой собственный, ни с чем не совместимый тип вызова!
::адресация аргументов в стеке. Базовая концепция стека включает лишь две операции – занесение элемента в стек и снятие последнего занесенного элемента со стека. Доступ к произвольному элементу – это что-то новенькое! Однако такое отступление от канонов существенно увеличивает скорость работы – если нужен, скажем, третий по счету элемент, почему бы ни вытащить из стека напрямую, не снимая первые два? Стек это не только "стопка", как учат популярные учебники по программированию, но еще и массив. А раз так, то, зная положение указателя вершины стека (а не знать его мы не можем, иначе куда прикажите класть очередной элемент?), и размер элементов, мы сможем вычислить смещению любого из элементов, после чего не составит никакого труда его прочитать.
Попутно отметим один из недостатков стека – как и любой другой гомогенный массив, стек может хранить данные лишь одного типа, например, двойные слова. Если же требуется занести один байт (скажем, аргумент типа char), то приходится расширять его до двойного слова и заносить его целиком. Аналогично, если аргумент занимает четыре слова (double, int64) на его передачу расходуется два стековых элемента!
Помимо передачи аргументов стек используется и для сохранения адреса возврата из функции, что требует в зависимости от типа вызова функции (ближнего или дальнего) от одного до двух элементов. Ближний (near) вызов действует в рамках одного сегмента, - в этом случае достаточно сохранить лишь смещение команды, следующей за инструкций CALL. Если же вызывающая функция находится в одном сегменте, а вызываемая в другом, то помимо смещения приходится запоминать и сам сегмент, чтобы знать в какое место вернуться. Поскольку адрес возврата заносится после аргументов, то относительно вершины стека аргументы оказываются "за" ним и их смещение варьируется в зависимости от того: один элемент занимает адрес возврата или два. К счастью, плоская модель памяти Windows NT\9x позволяет забыть о моделях памяти как о страшном сне и всюду использовать только ближние вызовы.
Не оптимизирующие компиляторы используют для адресации аргументов специальный регистр (как правило, EBP), копируя в него значение регистра-указателя вершины стека в самом начале функции. Поскольку стек растет снизу вверх, т.е. от старших адресов к младшим, смещение всех аргументов (включая адрес возврата) положительны, а смещение N-ого по счету аргумента вычисляется по следующей формуле:
arg_offset = N*size_element+size_return_address
где N
– номер аргумента, считая от вершины стека, начиная с нуля, size_element – размер одного элемента стека, в общем случае равный разрядности сегмента (под Windows NT\9x – четыре байта), size_return_address – размер в байтах, занимаемый адресом возврата (под Windows NT\9x – обычно четыре байта).
Часто приходится решать и обратную задачу: зная смещение элемента, определять к какому по счету аргументу происходит обращение. В этом нам поможет следующая формула, элементарно выводящаяся из предыдущей:
Поскольку, перед копированием в EBP текущего значения ESP, старое значение EBP приходится сохранять в том же самом стеке, в приведенную формулу приходится вносить поправку, добавляя к размеру адреса возврата еще и размер регистра EBP (BP в 16-разрядном режиме, который все еще жив на сегодняшний день).
С точки зрения хакера главное достоинства такой адресации аргументов в том, что, увидев где-то в середине кода инструкцию типа "MOV EAX,[EBP+0x10]", можно мгновенно вычислить к какому именно аргументу происходит обращение. Однако оптимизирующие компиляторы для экономии регистра EBP адресуют аргументы непосредственно через ESP. Разница принципиальна! Значение ESP не остается постоянным на протяжении выполнения функции и изменяется всякий раз при занесении и снятии данных из стека, следовательно, не остается постоянным и смещение аргументов относительно ESP. Теперь, чтобы определить к какому именно аргументу происходит обращение, необходимо знать: чему равен ESP в данной точке программы, а для выяснения этого все его изменения приходится отслеживать от самого начала функции! Подробнее о такой "хитрой" адресации мы поговорим потом (см. "Идентификация локальных стековых переменных"), а для начала вернемся к предыдущему примеру (надо ж его "добить") и разберем вызываемую функцию:
MyFunc proc near ; CODE XREF: main+39p
arg_0 = dword ptr 8
arg_4 = dword ptr 0Ch
arg_8 = byte ptr 10h
arg_1C = dword ptr 24h
; IDA
распознала четыре аргумента, передаваемых функции. Однако,
; не стоит безоговорочно этому доверять, – если один аргумент (например, int64)
; передается в нескольких машинных словах, то IDA
ошибочно примет его не за один,
; а за несколько аргументов!
; Поэтому, результат, полученный IDA, надо трактовать так: функции передается не менее
; четырех аргументов. Впрочем, и здесь не все гладко! Ведь никто не мешает вызываемой
; функции залезать в стек материнской так далеко, как она захочет! Может быть,
; нам не передавали никаких аргументов вовсе, а мы самовольно полезли в стек и
; стянули что-то оттуда. Хотя это случается в основном вследствие программистских
; ошибок из-за путаницы с прототипами, считаться с такой возможностью необходимо.
; (Когда ни будь вы все равно с этим встретитесь, так что будьте готовы)
; Число, стоящее после 'arg', выражает смещение аргумента относительно начала
; кадра стека.
; Обратите внимание: сам кадр стека смещен на восемь байт относительно EBP
-
; четыре байта занимает сохраненный адрес возврата, и еще четыре уходят на сохранение
; регистра EBP.
push ebp
mov ebp, esp
lea eax, [ebp+arg_8]
; получение указателя на аргумент.
; Внимание: именно указателя на аргумент, а не изволение аргумента-указателя!
; Теперь разберемся – на какой именно аргумент мы получаем указатель.
; IDA
уже вычислила, что этот аргумент смещен на восемь байт относительно
; начала кадра стека. В оригинале выражение, заключенное в скобках выглядело
; как ebp+0x10 – так его и отображает большинство дизассемблеров. Не будь IDA
; такой умной, нам бы пришлось постоянно вручную отнимать по восемь байт от
; каждого такого адресного выражения (впрочем, с этим мы еще поупражняемся)
;
; Логично: на вершине то, что мы клали в стек в последнею очередь.
; Смотрим вызывающую функцию – что ж мы клали-то?
; (см. вариант, откомпилированный Microsoft Visual C++)
; Ага, последними были те два непонятные аргумента, а перед ними в стек
; засылалась структура, состоящая из строки и переменной типа int
; Таким образом, EBP+ARG_8 указывает на строку
push eax
; Засылаем в стек полученный указатель.
; Похоже, что он передается очередной функции.
mov ecx, [ebp+arg_1C]
; Заносим в ECX содержимое аргумента EBP+ARG_1C.
На что он указывает?
; Вспомним, что тип int находится в структуре по смещению 0x14 байт от начала,
; а ARG_8 – и есть ее начало. Тогда, 0x8+0x14 == 0x1C.
; Т.е. в ECX заносится значение переменной типа int, члена структуры
push ecx
; Заносим полученную переменную в стек, передавая ее по значению
; (по значению – потому что ECX хранит значение, а не указатель)
mov edx, [ebp+arg_4]
; Берем один их тех двух непонятных аргументов, занесенных последними в стек
push edx
; ...и, вновь заталкиваем в стек, передавая его очередной функции.
mov eax, [ebp+arg_0]
push eax
; Берем второй непонятный аргумент и пихаем его в стек.
push offset aFXS ; "%f,%x,%s\n"
call _printf
; Опа! Вызов printf с передачей строкой спецификаторов! Функция, printf,
; как известно, имеет переменное число аргументов, тип и количество которых
; как раз и задают спецификаторы.
; Вспомним, – сперва в стек мы заносили указатель на строку, и действительно,
; крайний правый спецификатор "%s" обозначает вывод строки.
; Затем в стек заносилась переменная типа int
и второй справа спецификатор
; есть %x – вывод целого в шестнадцатеричной форме.
; А вот затем... затем идет последний спецификатор %f, в то время как в стек
; заносились два аргумента.
; Заглянув в руководство программиста по Microsoft Visual C++, мы прочтем,
; что спецификатор %f выводит вещественное значение, которое в зависимости от
; типа может занимать и четыре байта (float), и восемь (double).
; В нашем случае оно явно занимает восемь байт, следовательно, это double
; Таким образом, мы восстановили прототип нашей функции, вот он:
; cdecl MyFunc(double a, struct B b)
; Тип вызова cdecl – т.е. стек вычищала вызывающая функция. Вот только, увы,
; подлинный порядок передачи аргументов восстановить невозможно. Вспомним,
; Borland C++ так же вычищал стек вызывающей функцией, но самвовольно изменил
; порядок передачи параметров.
; Кажется, если программа компилилась Borland C++, то мы просто изменяем
; порядк арументов на обратный – вот и все. Увы, это не так просто. Если имело
; место явное преобразование типа функции в cdecl, то Borland C++ без лишней
; самодеятельности поступил бы так, как ему велели и тогда бы обращение
; порядка аргументов дало бы неверный резлуьтат!
; Впрочем, подлинный порядок следования аргументов в прототипе функции
; не играет никакой роли. Важно лишь связать передаваемые и принимаемые
; аргументы, что мы и сделали.
; Обратите внимание: это стало возможно лишь при совместом анализе и вызываемой
; и вызывающей функуий! Анализ лишь одной из них ничего бы не дал!
; Примечание: никогда не следует безоговорочно полагаться на достоверность
; строки спецификаторов. Посколкьу, спецификаторы формируются вручную самим
; программистом, тут возможны ошибки, под час весьма трудноуловимые и дающие
; после компиляции чрезвычайно загадочный код!
; Подробнее об этом рассказывается в статье
; "неизвестная уявзимость ошибка printf", помещенный в главу "Приложения"
add esp, 14h
pop ebp
retn
MyFunc endp
Листинг 59
Так, кое-какие продвижения уже есть – мы уверенно восстановили прототип нашей первой функции. Но это только начало… Еще много миль предстоит пройти, прежде чем будет достигнут конец главы. Если вы устали – передохните. Тяпните пивка (колы), позвоните своей любимой девушке (а, что, у хакеров и любимые девушки есть?), словом, как хотите, но обеспечьте свежую голову. Мы приступаем к еще одной нудной, но важной теме – сравнительному анализу различных типов вызовов функций и их реализации в популярных компиляторах.
Начнем с изучения стандартного соглашения о вызове – stdcall. Рассмотрим следующий пример:
#include <stdio.h>
#include <string.h>
__stdcall MyFunc(int a, int b, char *c)
{
return a+b+strlen(c);
}
main()
{
printf("%x\n",MyFunc(0x666,0x777,"Hello,World!"));
}
Листинг 60 Демонстрация stdcall
Результат его компиляции Microsoft Visual C++ с настройками по умолчанию должен выглядеть так:
main proc near ; CODE XREF: start+AFp
push ebp
mov ebp, esp
push offset aHelloWorld ; const char *
; Заносим в стек указатель на строку aHelloWorld.
; Заглянув в исходные тексты (благо они у нас есть), мы обнаружим, что
; это – самый правый аргумент, передаваемый функции. Следовательно,
; перед нами вызов типа stdcall или cdecl, но не PASCAL.
; Обратите внимание – строка передается по ссылке, но не по знаниючению.
push 777h ; int
; Заносим в стек еще один аргумент - константу типа int.
; (IDA начиная с версии 4.17 автоматически определяет ее тип).
push 666h ; int
; Передаем функции последний, самый левый аргумент, – константу типа int
call MyFunc
; Обратите внимание – после вызова функции отсутствуют команды очистки стека
; от занесенных в него аргументов. Если компилятор не схитрил и не прибегнул
; к отложенной очистке, то скорее всего, стек очищает сама вызываемая функция,
; значит, тип вызова – stdcall (что, собственно, и требовалось доказать)
push eax
; Передаем возвращенное функцией значение следующей функции как аргумент
push offset asc_406040 ; "%x\n"
call _printf
; ОК, эта следующая функция printf, и строка спецификаторов показывает,
; что переданный аргумент имеет тип int
add esp, 8
; Выталкивание восьми байт из стека – четыре приходятся на аргумент типа int
; остальные четыре – на указатель на строку спецификаторов
pop ebp
retn
main endp
; int __cdecl MyFunc(int,int,const char *)
MyFunc proc near ; CODE XREF: sub_40101D+12p
; С версии 4.17 IDA автоматически восстанавливает прототипы функций, но делает это
; не всегда правильно. В данном случае она допустила грубую ошибку – тип вызова
; никак не может иметь тип cdecl, т.к. стек вычищает вызываемая функция! Сдается, что
; вообще не предпринимает никаких попыток анализа типа вызова, а берет его из настроек
; распознанного компилятора по умолчанию.
; В общем, как бы там ни было, но с результатами работы IDA
следует обращаться
; очень осторожно.
arg_0 = dword ptr 8
arg_4 = dword ptr 0Ch
arg_8 = dword ptr 10h
push ebp
mov ebp, esp
push esi
; Это, как видно, сохранение регистра в стеке, а не передача его функции, т.к.
; регистр явным образом не инициализировался ни вызывающей, ни вызываемой
; функцией.
mov esi, [ebp+arg_0]
; Заносим в регистр ESI последней занесенный в стек аргумент
add esi, [ebp+arg_4]
; Складываем содержимое ESI с предпоследним занесенным в стек аргументом
mov eax, [ebp+arg_8]
; Заносим в в EAX пред- предпоследний аргумент и…
push eax ; const char *
; …засылаем его в стек.
call _strlen
; Поскольку strlen ожидает указателя на строку, можно с уверенностью
; заключить, что пред- предпоследний аргумент – строка, переданная по ссылке.
add esp, 4
; Вычистка последнего аргумента из стека
add eax, esi
; Как мы помним, в ESI хранится сумма двух первых аргументов,
; а в EAX – возвращенная длина строки. Таким образом, функция суммирует
; два своих аргумента с длиной строки.
pop esi
pop ebp
retn 0Ch
; Стек чистит вызываемая функция, следовательно, тип вызова stdcall
или PASCAL.
; Будем считать, что это stdcall, тогда прототип функции выглядит так:
; int MyFunc(int a, int b, char *c)
;
; Порядок аргументов вытекает из того, что на вершине стека были две
; переменные типа int, а под ними строка. Поскольку на верху стека лежит
; всегда то, что заносилось в него в последнюю очередь, а по stdcall
; аргументы заносятся справа налево, мы получаем именно такой порядок
; следования аргументов
MyFunc endp
Листинг 61
А теперь рассмотрим, как происходит вызов cdecl функции. Изменим в предыдущем примере ключевое слово stdcall на cdecl:
#include <stdio.h>
#include <string.h>
__cdecl MyFunc(int a, int b, char *c)
{
return a+b+strlen(c);
}
main()
{
printf("%x\n",MyFunc(0x666,0x777,"Hello,World!"));
}
Листинг 62 Демонстрация cdecl
Результат компиляции должен выглядеть так:
main proc near ; CODE XREF: start+AFp
push ebp
mov ebp, esp
push offset aHelloWorld ; const char *
push 777h ; int
push 666h ; int
; Передаем функции аргументы через стек
call MyFunc
add esp, 0Ch
; Смотрите: стек вычищает вызывающая функция. Значит, тип вызова cdecl,
; поскольку, все остальные предписывают вычищать стек вызываемой функции.
push eax
push offset asc_406040 ; "%x\n"
call _printf
add esp, 8
pop ebp
retn
main endp
; int __cdecl MyFunc(int,int,const char *)
; А вот сейчас IDA правильно определила тип вызова. Однако, как уже показывалось выше,
; она могла и ошибиться, поэтому полагаться на нее не стоит.
MyFunc proc near ; CODE XREF: main+12p
arg_0 = dword ptr 8
arg_4 = dword ptr 0Ch
arg_8 = dword ptr 10h
; Поскольку, как мы уже выяснили, функция имеет тип cdecl, аргументы передаются
; справа налево и ее прототип выглядит так: MyFunc(int arg_0, int arg_4, char *arg_8)
push ebp
mov ebp, esp
push esi
; Сохраняем ESI в стеке
mov esi, [ebp+arg_0]
; Заносим в ESI аргумент arg_0 типа int
add esi, [ebp+arg_4]
; Складываем его с arg_4
mov eax, [ebp+arg_8]
; Заносим в EAX указатель на строку
push eax ; const char *
; Передаем его функции strlen через стек
call _strlen
add esp, 4
add eax, esi
; Добавляем к сумме arg_0 и arg_4 длину строки arg_8
pop esi
pop ebp
retn
MyFunc endp
Листинг 63
Прежде, чем перейти к вещам по настоящему серьезным, рассмотрим на закуску последний стандартный тип – PASCAL:
#include <stdio.h>
#include <string.h>
// Внимание! Microsoft Visual C++ уже не поддерживает тип вызова PASCAL
// вместо этого используйте аналогичный ему тип вызова WINAPI, определенный в файле
// <windows.h>.
#if defined(_MSC_VER)
#include <windows.h>
// включать windows.h только если мы компилируется Microsoft Visual C++
// для остальных компиляторов более эффективное решение – использование ключевого
// слова PASACAL, если они, конечно, его поддерживают. (Borland
поддерживает)
#endif
// Подобный примем программирования может и делает листинг менее читабельным,
// но зато позволяет компилировать его не только одним компилятором!
#if defined(_MSC_VER)
WINAPI
#else
__pascal
#endif
MyFunc(int a, int b, char *c)
{
return a+b+strlen(c);
}
main()
{
printf("%x\n",MyFunc(0x666,0x777,"Hello,World!"));
}
Листинг 64 Демонстрация вызова PASCAL
Результат компиляции Borland C++ должен выглядеть так:
; int __cdecl main(int argc,const char **argv,const char *envp)
_main proc near ; DATA XREF: DATA:00407044o
push ebp
mov ebp, esp
push 666h ; int
push 777h ; int
push offset aHelloWorld ; s
; Передаем функции аргументы. Заглянув в исходный текст, мы заметим, что
; аргументы передаются слева направо. Однако если исходных текстов нет,
; установить этот факт невозможно! К счастью, подлинный прототип функции
; не важен.
call MyFunc
; Функция не вычищает за собой стек! Если это не результат оптимизации –
; ее тип вызова либо PASCAL, либо stdcall. Ввиду того, что PASACAL уже вышел
; из употребления, будем считать, что имеем дело с stdcall
push eax
push offset unk_407074 ; format
call _printf
add esp, 8
xor eax, eax
pop ebp
retn
_main endp
; int __cdecl MyFunc(const char *s,int,int)
; Ага! IDA вновь дала неправильный результат! Тип вызова явно не cdecl!
; Однако, в остальном прототип функции верен, вернее, не то что бы он верен
; (на самом деле порядок аргументов обратный), но для использования – пригоден
MyFunc proc near ; CODE XREF: _main+12p
s = dword ptr 8
arg_4 = dword ptr 0Ch
arg_8 = dword ptr 10h
push ebp
mov ebp, esp
; Открываем кадр стека
mov eax, [ebp+s]
; Заносим в EAX указатель на строку
push eax ; s
call _strlen
; Передаем его функции strlen
pop ecx
; Очищаем стек от одного аргумента, выталкивая его в неиспользуемый регистр
mov edx, [ebp+arg_8]
; Заносим в EDX аргумент arg_8 типа int
add edx, [ebp+arg_4]
; Складываем его с аргументом arg_4
add eax, edx
; Складываем сумму arg_8 и arg_4 с длиной строки
pop ebp
retn 0Ch
; Стек чистит вызываемая функция. Значит, ее тип PASCAL
или stdcall
MyFunc endp
Листинг 65
Как мы видим, идентификация базовых типов вызов и восстановление прототипов функции – занятие несложное. Единственное, что портит настроение – путаница с PASCAL и stdcall, но порядок занесения аргументов в стек не имеет никакого значения, разве что в особых случаях, один из которых перед вами:
#include <stdio.h>
#include <windows.h>
#include <winuser.h>
// CALLBACK процедура для приема сообщений от таймера
VOID CALLBACK TimerProc(
HWND hwnd, // handle of window for timer messages
UINT uMsg, // WM_TIMER message
UINT idEvent, // timer identifier
DWORD dwTime // current system time
)
{
// Бибикаем всеми пиками на все голоса
MessageBeep((dwTime % 5)*0x10);
// Выводим время в секундах, прошедшее с момента пуска системы
printf("\r:=%d",dwTime / 1000);
}
main()
// Да, это консольное приложение, но оно так же может иметь цикл выборки сообщений
// и устанавливать таймер!
{
int a;
MSG msg;
// Устанавливаем таймер, передавая ему адрес процедуры TimerProc
SetTimer(0,0,1000,TimerProc);
// Цикл выборки сообщений. Когда надоест – жмем Ctrl-Break и прерываем его
while (GetMessage(&msg, (HWND) NULL, 0, 0))
{
TranslateMessage(&msg);
DispatchMessage(&msg);
}
}
Листинг 66 Пример, демонстрирующий тот случай, когда требуется точно отличать PASCAL от stdcall
Откомпилируем этот пример так: "cl pascal.callback.c USER32.lib" и посмотрим, что из этого получилось:
main proc near ; CODE XREF: start+AFp
; На сей раз IDA не определила прототип функции. Ну и ладно...
Msg = MSG ptr -20h
; IDA
распознала одну локальную переменную и даже восстановила ее тип, что радует
push ebp
mov ebp, esp
sub esp, 20h
push offset TimerProc ; lpTimerFunc
; Передаем указатель на функцию TimerProc
push 1000 ; uElapse
; Передаем время задержки таймера
push 0 ; nIDEvent
; В консольных приложениях аргумент nIDEvent
всегда игнорируется
push 0 ; hWnd
; Окон нет, передаем NULL
call ds:SetTimer
; Win32 API
функции вызываются по соглашению stdcall
– это дает возможность,
; зная их прототип,(а он описан в SDK) восстановить тип и назначение аргументов
; в данном случае исходный текст выглядел так:
; SetTimer(NULL, BULL, 1000, TimerProc);
loc_401051: ; CODE XREF: main+42j
push 0 ; wMsgFilterMax
; NULL – нет
фильтра
push 0 ; wMsgFilterMin
; NULL – нет
фильтра
push 0 ; hWnd
; NULL
– нет окон в консольном приложении
lea eax, [ebp+Msg]
; Получаем указатель на локальную переменную msg
-
; тип этой переменной определяется, кстати, только на основе прототипа
; функции GetMessageA
push eax ; lpMsg
; Передаем указатель на msg
call ds:GetMessageA
; Вызываем
функцию GetMessageA(&msg, NULL, NULL, NULL);
test eax, eax
jz short loc_40107B
; Проверка на получение WM_QUIT
lea ecx, [ebp+Msg]
; В ECX – указатель на заполненную структуру MSG…
push ecx ; lpMsg
; …передаем
его функции TranslateMessage
call ds:TranslateMessage
; Вызываем
функцию TranslateMessage(&msg);
lea edx, [ebp+Msg]
; В EDX – указатель на msg…
push edx ; lpMsg
; …передаем его функции DispatchMessageA
call ds:DispatchMessageA
; Вызов
функции DispatchMessageA
jmp short loc_401051
; Цикл
выборки сообщений
loc_40107B: ; CODE XREF: main+2Cj
; Выход
mov esp, ebp
pop ebp
retn
main endp
TimerProc proc near ; DATA XREF: main+6o
; Прототип TimerProc в следствие ее неявного вызова операционной системой
; не был автоматически восстановлен IDA, - этим придется заниматься нам
; Мы знаем, что TimerProc передается функции SetTimer.
; Заглянув в описание SetTimer (SDK
всегда должен быть под рукой!) мы найдем
; ее
прототип:
;
;VOID CALLBACK TimerProc(
; HWND hwnd, // handle of window for timer messages
; UINT uMsg, // WM_TIMER message
; UINT idEvent, // timer identifier
; DWORD dwTime // current system time
;)
;
; Остается разобраться с типом вызова. На сей раз он приниципиален, т.к. не имеея
; кода вызывающей функции (он расположен глубоко в недрах операционной системы),
; мы разберемся с типами аргументов только в том случае, если будет знать их
; порядок передачи.
; Выше уже говорилось, что все CALLBACK
функции следуют соглашению PASCAL.
; Не путайте CALLBACK-функции с Win32 API-функциями! Первые вызывает сама
; операционная система, а вторые – прикладная программа.
;
; ОК, тип вызова этой функции – PASCAL. Значит, аргументы заносятся слевно направо,
; а стек чистит вызываемая функция (убедитесь, что это действительно так).
arg_C = dword ptr 14h
; IDA
обнаружила только один аргумент, хотя, судя по прототипу, их передается четыре.
; Почему? Очень просто – функция использовала всего один аргумент, а к остальным и
; не обращалась. Вот IDA и не смогла их восстановить!
; Кстати, что это за аргумент? Смотрим: его смещение равно 0xC. А на вершине стека то,
; что в него заталкивалось в последнюю очередь. Внизу, соответственно, наоборот.
; Постой, постой, что за чертовщина?! Выходит, dwTime
был занесен в стек в первую
; очередь?! (Мы-то, имея исходный текст, знаем, что arg_C – наверняка dwTime).
; Но ведь соглашение PASCAL диктует противоположный порядок занесения аргументов!
; Что-то здесь не так... но ведь программа работает (запустите ее, чтобы проверить)
; А в SDK написано, что CALLBACK – аналог FAR PASACAL. С FAR-ом понятно, в Win9x\NT
; все вызовы ближние, но вот как объяснить инверсию засылки аргументов?!
; Сдаетесь?(Нет, не сдавайтесь, попытайтесь найти решение сами – иначе какой интерес?)
; Тогда загляните в <windef.h> и посмотрите, как там определен тип PASCAL
;
; #elif (_MSC_VER >= 800) || defined(_STDCALL_SUPPORTED)
; #define CALLBACK __stdcall
; #define WINAPI __stdcall
; #define WINAPIV __cdecl
; #define APIENTRY WINAPI
; #define APIPRIVATE __stdcall
; #define PASCAL __stdcall
;
; Нет, ну кто бы мог подумать!!! Вызов, объявленный как PASCAL, на самом деле
; представляет собой stdcall! И CALLBACK – так же определен, как stdcall.
; Наконец-то все объяснилось! Теперь, если вам скажут, что CALLBACK
– это PASCAL
; вы можете усмехнуться и сказать, что еж тоже птица, правда гордая – пока не пнешь
; не полетит! (Оказывается, копания в дебрях include-файлов могут приносить пользу)
; Кстати, это извращения с перекрытием типов создают большую проблему при подключении
; к Си-проекту модулей, написанных в среде, поддерживающей PASACAL-соглашения о вызове
; функций. Поскольку в Windows PASCAL никакой не PASCAL, а stdcall – ничего работать
; соответственно не будет! Правда, есть еще ключевое слово __pascal, которое не
; перекрывается, но и не поддерживается последними версиями Microsoft Visual C++.
; Выход состоит в использовании ассемблерных вставок или переходе на Borland C++
; он, как и многие другие компиляторы, соглашение PASACAL
до сих пор исправно
; поддерживает.
;
; Итак, мы выяснили, что аргументы CALLBACL-функциям передаются справа налево, но
; стек вычищает сама вызываемая функция, как и положено по stdcall
соглашению.
push ebp
mov ebp, esp
mov eax, [ebp+arg_C]
; заносим в EAX аргумент dwTime.
; Как мы получили его? Смотрим – перед ним в стеке лежат три аргумента
; каждый из которых размеров в 4 байта, тогда 4*3=0xC
xor edx, edx
; Обнуляем EDX
mov ecx, 5
; Присваиваем ECX значение 5
div ecx
; Делим dwTime (он в EAX) на 5
shl edx, 4
; В EDX – остаток от деления, циклическим сдвигом умножаем его на 0x10
; точнее, умножаем его на 24
push edx ; uType
; Передаем полученный результат функции MessageBeep.
; Заглянув в SDK, мы найдем, что MessageBeep принимает одну из констант:
; NB_OK, MB_ICONASTERISK, MB_ICONHAND и т.д., но там ничего не сказано о том,
; какое непосредственное значение каждое из них принимает.
; Зато сообщается, что MessageBeep описана в файле <WINUSER.h>
; Открываем его и ищем контекстным поиском MB_OK:
;
; #define MB_OK 0x00000000L
; #define MB_OKCANCEL 0x00000001L
; #define MB_ABORTRETRYIGNORE 0x00000002L
; #define MB_YESNOCANCEL 0x00000003L
; #define MB_YESNO 0x00000004L
; #define MB_RETRYCANCEL 0x00000005L
;
; #define MB_ICONHAND 0x00000010L
; #define MB_ICONQUESTION 0x00000020L
; #define MB_ICONEXCLAMATION 0x00000030L
; #define MB_ICONASTERISK 0x00000040L
;
; Есть хвост у Тигры! Смотрите: все, интересующее нас константы, равны:
; 0x0, 0x10, 0x20, 0x30, 0x40. Теперь становится понятным смысл программы
; Взяв остаток, полученный делением количества миллисекунд, прошедших с минуты
; включения системы на 5, мы получаем число в интервале от 0 до 4. Умножая его
; на 0x10, - 0x0, 0x0x10 – 0x40.
call ds:MessageBeep
; Бибикаем на все лады
mov eax, [ebp+arg_C]
; Заносим в EAX dwTime
xor edx, edx
; Обнуляем EDX
mov ecx, 3E8h
; В десятичном 0x3E8 равно 1000
div ecx
; Делим dwTime на 1000 – т.е. переводим миллисекунды в секунды и…
push eax
; …передаем его функции printf
push offset aD ; "\r:=%d"
call _printf
add esp, 8
; printf("\r:=%d")
pop ebp
retn 10h
; Выходя – гасите свет, т.е. чистите за собой стек!
TimerProc endp
Листинг 67
Важное замечание о типах, определенных в <WINDOWS.H>! Хотя об этом уже говорилось в комментариях к предыдущему листингу, повторение не будет лишним, хотя бы уже потому, что не все читатели вчитываются в разборы дизассемблерных текстов.
Итак, CALLBACK и WINAPI функции следуют соглашению о вызовах PASCAL, но сам PASACAL определен в <WINDEF.H> как stdcall (а на некоторых платформах и как cdecl). Таким образом, на платформе INTEL все Windows-функции следуют соглашению: аргументы заносятся справа налево, а стек вычищает вызываемая функция.
Давайте для знакомства в PASCAL-соглашением создадим простенькую PASCAL программу и дизассемблируем ее (это, не обозначает, что PASCAL-вызовы встречаются только в PASCAL-программах, но так будет справедливо):
USES WINCRT;
Procedure MyProc(a:Word; b:Byte; c:String);
begin
WriteLn(a+b,' ',c);
end;
BEGIN
MyProc($666,$77,'Hello,Sailor!');
END.
Листинг 68 Демонстрация PASCAL-вызова
Результат компиляции компилятором "Turbo Pascal for Windows" должен выглядеть так:
PROGRAM proc near
call INITTASK
; Вызов INITTASK из KRNL386.EXE для инициализации 16-разрядной задачи
call @__SystemInit$qv ; __SystemInit(void)
; Инициализация модуля SYSTEM
call @__WINCRTInit$qv
; __WINCRTInit(void)
; Инициализация модуля WinCRT
push bp
mov bp, sp
; Пролог функции в середине функции!
; Вот такой он, Turbo-PASCAL!
xor ax, ax
call @__StackCheck$q4Word ; Stack overflow check (AX)
; Проверка стека на переполнение
push 666h
; Обратите внимание – передача аргументов идет слева направо
push 77h ; 'w'
mov di, offset aHelloSailor ; "Hello,Sailor!"
; В DI – указатель на строку "Hello, Sailor"
push ds
push di
; Смотрите: передается не ближний (NEAR), а дальний (FAR) указатель –
; т.е. и сегмент, и смещение строки.
call MyProc
; Стек чистит вызываемая функция.
leave
; Эпилог функции – закрытие кадра стека.
xor ax, ax
call @Halt$q4Word ; Halt(Word)
; Конец программы!
PROGRAM endp
MyProc proc near ; CODE XREF: PROGRAM+23p
; IDA
не определила прототип функции. Что ж, сделаем это сами!
var_100 = byte ptr -100h
; Локальная переменная. Судя по тому, что она находится на 0x100 байт выше кадра
; стека, сдается, что это массив их 0x100 байт. Поскольку, максимальная длина строки
; в PASACAL как раз и равна 0xFF байтам. Похоже, это буфер, зарезервированный под
; строку.
arg_0 = dword ptr 4
arg_4 = byte ptr 8
arg_6 = word ptr 0Ah
; Функция принимает три аргумента
push bp
mov bp, sp
; Открываем кадр стека
mov ax, 100h
call @__StackCheck$q4Word ; Stack overflow check (AX)
; Проверяем – если ли в стеке необходимые нам 100 байт для локальных переменных
sub sp, 100h
; Резервируем пространство под локальные переменные
les di, [bp+arg_0]
; получаем указатель на самый правый аргумент
push es
push di
; Смотрите – передаем дальний указатель на аргумент arg_0, причем его
; сегмент из стека даже не извлекался!
lea di, [bp+var_100]
; Получаем указатель на локальный буфер
push ss
; Заносим его сегмент в стек
push di
; Заносим смещение буфера в стек
push 0FFh
; Заносим макс. длину строки
call @$basg$qm6Stringt14Byte ; Store string
; Копируем строку в локальный буфер (значит, arg_0 – это строка).
; Правда, совершенно непонятно зачем. Неужто нельзя пользоваться ссылкой?
; Дурной-дурной этот Turbo-Pascal!
; Да что делать – в самом Паскале строки передаются по значению :-(
mov di, offset unk_1E18
; Получаем указатель на буфер вывода
; Тут надобно познакомимся с системой вывода Паскаля – она весьма разительно
; отличается от Си.
; Во-первых, левосторонний порядок засылки аргументов в стек не позволяет
; организовать поддержку процедур с переменным числом аргументов
; (во всяком случае, без дополнительных ухищрений)
; Но ведь WriteLn и есть процедура с переменным числом параметров. Разве нет?!
; Вот именно, что нет!!! Никакая это не процедура, а оператор!
; Компилятор еще на стадии компиляции разбивает ее на множество вызовов
; процедур для вывода каждого аргумента по отдельности. Поэтому,
; в откомпилированном коде каждая процедура примет фиксированное количество
; аргументов. В нашем случае их будет три: первая для вывода суммы двух
; чисел – этим занимается процедура WriteLongint, вторая – для вывода символа
; пробела в символьной форме – этим занимается WriteChar
и, наконец, последняя
; для вывода строки – WriteSting
; Размышляем далее – под Windows непосредственно вывести строку в окно и тут же
; забыть о ней нельзя, т.к. окно в любой момент может потребовать перерисовки –
; операционная система не сохраняет его содержимого – в графической среде
; при высоком разрешении это привело бы к большим затратам памяти.
; Код, выводящий строку, должен уметь повторять свой вывод по запросу.
; Каждый, кто хоть раз программировал под Windows, наверняка помнит, что весь
; вывод приходилось помещать в обработчик сообщения WM_PAINT.
; Turbo Pascal
же позволяет обращаться к Windows-окном точно так,
; как с консолью. А раз так – он должен где-то хранить все, ранее выведенное
; на экран. Поскольку, локальный переменные умирают вместе с завершением
; их процедуры, то для хранения буфера они не годятся. Остается либо куча, либо
; сегмент данных. Pascal использует последнее – указатель на такой буфер мы
; только что получили.
; Далее, для повышения производительности вывода Turbo-Pascal реализует
; простейший
кэш. Функции WriteLingint, WriteChar, WriteString сливают
; результат своей деятельности в символьном виде в этом самый буфер, а в конце
; следует вызов WriteLn, выводящий содержимое буфера в окно.
; Run-time systems следит за его перерисовками и при необходимости повторяет
; вывод уже без участия программиста.
push ds
push di
; Заносим адрес буфера в стек
mov al, [bp+arg_4]
; Тип аргумента arg_4 - Byte
xor ah, ah
; Обнуляем старший байт регистра ah
add ax, [bp+arg_6]
; Складываем arg_4 с arg_6. Поскольку, al было предварительно расширено до AX
; то arg_6 имеет тип Word, т.к. при сложении двух чисел разного типа PASCAL
; расширяет их до большего из них.
; Кроме того, вызывающая процедура передает с этим аргументом значение 0x666,
; что явно не влезло бы в Byte.
xor dx, dx
; Обнуляем DX…
push dx
; …и заносим его в стек.
push ax
; Заносим в стек сумму двух левых аргументов
push 0
; Еще один ноль!
call @Write$qm4Text7Longint4Word ; Write(var f; v: Longint; width: Word)
; Функция WriteLongint имеет следующий прототип
; WriteLongint(Text far &, a: Longint, count:Word); где -
; Text far & - указатель на буфер вывода
; a - выводимое длинное целое
; count - сколько переменных выводить (ноль – одна переменная)
;
; Значит, в нашем случае мы выводим одну переменную – сумму двух аргументов.
; Маленькое дополнение – функция WriteLongint
не следует соглашению PASCAL
; т.к. не до конца чистит за собой стек, оставляя указать на буфер в стеке.
; На этот шаг разработчики компилятора пошли для увеличения производительности:
; раз указатель на буфер будет нужен и другим функциям
;(по крайней мере одной из них – WriteLn), зачем его то стягивать, то опять
; лихорадочно запихивать?
; Если вы загляните в конец функции WriteLongint, вы обнаружите там RET
6,
; т.е. функция выпихивает два аргумента – два машинных слова на Longint
и один
; Word на count.
; Вот такая милая маленькая техническая деталь. Маленькая-то она, маленькая,
; но как сбивает с толку!
; (особенно, если исследователь не знаком с системой ввода-вывода Паскаля)
push 20h ; ' '
; Заносим в стек следующий аргумент, передаваемый функции WriteLn
; (указатель на буфер все еще находится в стеке).
push 0
; Нам надо вывести только одни символ
call @Write$qm4Text4Char4Word ; Write(var f;c: Char; width:Word)
lea di, [bp+var_100]
; Получаем указатель на локальную копию переданной функции строки
push ss
push di
; Заносим ее адрес в стек
push 0
; Выводить только одну строку!
call @Write$qm4Textm6String4Word ; Write(var f; s: String; width: Word)
call @WriteLn$qm4Text ; WriteLn(var f: Text)
; Кажется, функции не передаются никакие параметры, но на самом деле на вершине
; стека лежит указатель на буфер и ждет своего "звездного часа"
; после завершения WriteLn он будет снят со стека
call @__IOCheck$qv ; Exit if error
; Проверка операции вывода на успешность
leave
; Закрываем кадр стека
retn 8
; Выталкиваем восемь байт со стека. ОК, теперь мы знаем все необходимое для
; восстановления прототипа нашей процедуры. Он выглядит так:
; MyProc(a:Byte, b:Word, c:String);
MyProc endp
Листинг 69
Да, хитрым оказался Turbo-PASCAL! Анализ откомпилированной с его помощью программы преподнес нам один очень важный урок – никогда нельзя быть уверенным, что функция выталкивает все переданные ей аргументы из стека, и уж тем более нельзя определять количество аргументов по числу снимаемых из стека машинных слов!
::соглашения о быстрых вызовах – fastcall. Какой бы непроизводительной передача аргументов через стек ни была, а типы вызовы stdcall и cdecl стандартизированы и хочешь – не хочешь, а их надо соблюдать. Иначе, модули, скомпилированные один компилятором (например, библиотеки), окажутся не совместимы с модулями, скомпилированными другими компиляторами. Впрочем, если вызываемая функция компилируется тем же самым компилятором, что и вызывающая, - придерживаться типовых соглашений ни к чему и можно воспользоваться более эффективной передачей аргументов через регистры.
Многие начинающие программисты удивляются: а почему передача аргументов через регистры до сих пор не стандартизирована и вряд ли когда будет стандартизирована вообще? Ответ: кем бы она могла быть стандартизирована? Комитетами по стандартизации Си и Си++? Нет, конечно! – все платформенно – зависимые решения оставляются на откуп разработчикам компиляторов – каждый из них волен реализовывать их по-своему или не реализовывать вообще. "Хорошо, уговорили", - не согласится иной читатель, "но что мешает разработчикам компиляторов одной конкретной платформы договориться об общих соглашениях. Ведь договорились же они передавать возвращенное функцией значение через [E]AX:[[E]DX], хотя стандарт о конкретных регистрах вообще никакого понятия не имеет".
Ну, отчасти разработчики и договорись: большинство 16-разрядных компиляторов придерживалось общих соглашений (хотя об этом не сильно трубилось вслух), но без претензий на совместимость друг с другом. Быстрый вызов – он на то и называется быстрым, чтобы обеспечить максимальную производительность. Техника же оптимизации не стоит на месте и вводить стандарт – это все равно, что привязывать гирю к ноге. С другой стороны, средний выигрыш от передачи аргументов через регистры составляет единичные проценты, – вот многие разработчики компиляторов отказываются от быстроты в пользу простоты (реализации). К тому же, если так критична производительность – используйте встраиваемые функции.
Впрочем, все эти рассуждения интересны в первую очередь программистам, исследователей же программ волнует не эффективность, а восстановление прототипов функций. Можно ли узнать какие аргументы принимает fastcall - функция, не анализируя ее код (т.е. смотря только на вызывающую функцию). Чрезвычайно популярный ответ "Нет, это невозможно, поскольку компилятор передает аргументы в наиболее "удобных" регистрах" неправилен, и говорящий наглядно демонстрирует свое полное незнание техники компиляции.
Существует такой термин как "единица трансляции", - в зависимости от реализации компилятор может либо транслировать весь текст программы целиком (что весьма накладно, т.к. придется хранить в памяти все дерево синтаксического разбора), либо транслировать каждую функцию по отдельности, сохраняя в памяти лишь ее имя и ссылку на сгенерированный для нее код. Компиляторы первого типа крайне редки, во всяком случае для ОС Windows я не встречал ни одного такого Си\Cи++ компилятора (хотя и слышал о таких). Компиляторы второго типа более производительны, требуют меньше памяти, проще в реализации, словом, всем хороши, за исключением органической неспособности к "сквозной" оптимизации, - каждая функция оптимизируется "персонально" и независимо от другой. Поэтому, подобрать оптимальные регистры для передачи аргументов компилятор не может, поскольку он не знает, как с ними манипулирует вызываемая функция. Поскольку, функции транслируются независимо, им приходится придерживаться общих соглашений, даже если это и невыгодно.
Таким образом, зная "почерк" конкретного компилятора, восстановить прототип функции можно без труда.
::Borland C++ 3.x – передача аргументов осуществляется через регистры: AX (AL), DX (DL), BX (BL), а, когда регистры кончаются, аргументы начинают засылаться в стек, заносясь в него слева направо и выталкиваясь самой вызываемой функцией (a la stdcall).
Схема передачи аргументов довольно интересна – компилятор не закрепляет за каждым аргументом "своих" регистров, вместо этого он предоставляет свободный доступ каждому из них к "стопке" кандидатов, уложенных в порядке предпочтения.
Каждый аргумент снимает со стопки столько регистров, сколько ему нужно, а когда стопка исчерпается – тогда придется отправляться в стек. Исключение составляет тип long int, всегда передаваемый через DX:AX (причем, в DX передается старшее слово), а если это невозможно – то через стек.
Если каждый аргумент занимает не более 16-ти бит (как обычно и происходит), то первый слева аргумент помещается в AX (AL), второй – в DX (DL), третий – в BX (BL). Если же первый слева аргумент представляет тип long int, он снимает со стопки сразу два регистра – DX:AX, тогда второму аргументу остается регистр BX (BL), а третьему – и вовсе ничего (и тогда он передается через стек). Когда же long int передается вторым аргументом, он отправляется в стек, т.к. необходимый ему регистр AX уже занят первым аргументом, третий же аргумент передается через DX. Наконец, будучи третьим слева аргументом, long int идет в стек, а первые два аргумента передаются через AX (AL) и DX (DL) соответственно.
Передача дальних указателей и вещественных значений всегда осуществляется через основной стек (а не стек сопроцессора, как иногда приходится слышать, и как подсказывает здравый смысл).
|
тип |
предпочтения |
||
|
1й |
2й |
3й |
|
|
char |
AL |
DL |
BL |
|
int |
AX |
DX |
BX |
|
long int |
DX:AX |
||
|
ближний указатель |
AX |
DX |
BX |
|
дальний указатель |
stack |
||
|
float |
stack |
||
|
double |
stack |
::Microsoft C++ 6.0 – ведет себя аналогично компилятору Borland C++ 3.x за исключением того, что изменяет порядок предпочтений кандидатов для передачи указателей, выдвигая на первое место BX. И это – правильно, ибо ранние микропроцессоры 80x86 не поддерживали косвенную адресацию ни через AX, ни через DX и переданное функции значение все равно приходилось перепихивать либо в BX, либо в SI или DI.
|
тип |
предпочтения |
||
|
1й |
2й |
3й |
|
|
char |
AL |
DL |
BL |
|
int |
AX |
DX |
BX |
|
long int |
DX:AX |
||
|
ближний указатель |
BX |
AX |
DX |
|
дальний указатель |
stack |
||
|
float |
stack |
||
|
double |
stack |
::Borland C++ 5.x – очень похож на своего предшественника – компилятор Borland C++ 3.x, за исключением того, что вместо регистра BX отдает предпочтение регистру CX, и аргументы типа int и long int помещает в любой из подходящих 32-разрядных регистров, а не DX:AX. Как, впрочем, и следовало ожидать при переводе компилятора с 16- на 32-разрядный режим.
|
тип |
предпочтения |
||
|
1й |
2й |
3й |
|
|
char |
AL |
DL |
CL |
|
int |
EAX |
EDX |
ECX |
|
long int |
EAX |
EDX |
ECX |
|
ближний указатель |
EAX |
EDX |
ECX |
|
дальний указатель |
stack |
||
|
float |
stack |
||
|
double |
stack |
::Microsoft Visual C++ 4.x – 6.x: при возможности передает первый слева аргумент в регистре ECX, второй – в регистре EDX, а все остальные через стек. Вещественные значения и дальние указатели всегда передаются через стек. Аргумент типа __int64 (нестандартный тип, 64-разрядное целое, введенный Microsoft) всегда передается через стек.
Если __int64 – первый слева аргумент, то второй аргумент передается через ECX, а третий – через EDX. Соответственно, если __int64 – второй аргумент, то первый передается через ECX, а третий – через EDX.
|
тип |
предпочтения |
||
|
1й |
2й |
3й |
|
|
char |
CL |
DL |
-- |
|
int |
ECX |
EDX |
-- |
|
__int64 |
stack |
||
|
long int |
ECX |
-- |
|
|
ближний указатель |
ECX |
EDX |
-- |
|
дальний указатель |
stack |
-- |
|
|
float |
stack |
-- |
|
|
double |
stack |
-- |
Таблица 5 Порядок предпочтений Microsoft Visual C++ 4.x – 6.x при передаче аргументов по соглашению fastcall
::WATCOM C. Компилятор от WATCOM сильно отличается от компиляторов от Borland и Microsoft. В частности, он не поддерживает ключевого слова fastcall (что, кстати, приводит к серьезным проблемам совместимости), но по умолчанию всегда стремиться передавать аргументы через регистры. Вместо общепринятой "стопки предпочтений" WATCOM жестко закрепляет за каждым аргументом свой регистр: за первым - EAX, за вторым - EDX, за третьим -EBX, за четвертым – ECX, причем, если какой-то аргумент в указанный регистр поместить не удается, он и все остальные аргументы, находящиеся правее него, помещаются в стек! В частности, типы float и double по умолчанию помещаются в стек основного процессора, что "портит всю малину"!
|
тип |
аргумент |
|||
|
1й |
2й |
3й |
4й |
|
|
char |
AL |
DL |
BL |
CL |
|
int |
EAX |
EDX |
EBX |
ECX |
|
long int |
EAX |
EDX |
EBX |
ECX |
|
ближний указатель |
ECX |
EDX |
EBX |
ECX |
|
дальний указатель |
stack |
stack |
stack |
stack |
|
float |
stack CPU |
stack CPU |
stack CPU |
stack CPU |
|
stack FPU |
stack FPU |
stack FPU |
stack FPU |
|
|
double |
stack CPU |
stack CPU |
stack CPU |
stack CPU |
|
stack FPU |
stack FPU |
stack FPU |
stack FPU |
При желании программист может "вручную" задать собственный порядок передачи аргументом, прибегнув к прагме aux, имеющий следующий формат: "#pragma aux имя функции parm [перечь регистров]". Список допустимых регистров для каждого типа аргументов приведен в следующей таблице:
|
тип |
допустимые регистры |
|||||
|
char |
EAX |
EBX |
ECX |
EDX |
ESI |
EDI |
|
int |
EAX |
EBX |
ECX |
EDX |
ESI |
EDI |
|
long int |
EAX |
EBX |
ECX |
EDX |
ESI |
EDI |
|
ближний указатель |
EAX |
EBX |
ECX |
EDX |
ESI |
EDI |
|
дальний указатель |
DX:EAX |
CX:EBX |
CX:EAX |
CX:ESI |
DX:EBX |
DI:EAX |
|
CX:EDI |
DX:ESI |
DI:EBX |
SI:EAX |
CX:EDX |
DX:EDI |
|
|
DI:ESI |
SI:EBX |
BX:EAX |
FS:ECX |
FS:EDX |
FS:EDI |
|
|
FS:ESI |
FS:EBX |
FS:EAX |
GS:ECX |
GS:EDX |
GS:EDI |
|
|
GS:ESI |
GS:EBX |
GS:EAX |
DS:ECX |
DS:EDX |
DS:EDI |
|
|
DS:ESI |
DS:EBX |
DS:EAX |
ES:ECX |
ES:EDX |
ES:EDI |
|
|
ES:ESI |
ES:EBX |
ES:EAX |
||||
|
float |
8087 |
??? |
??? |
??? |
??? |
??? |
|
double |
8087 |
EDX:EAX |
ECX:EBX |
ECX:EAX |
ECX:ESI |
EDX:EBX |
|
EDI:EAX |
ECX:EDI |
EDX:ESI |
EDI:EBX |
ESI:EAX |
ECX:EDX |
|
|
EDX:EDI |
EDI:ESI |
ESI:EBX |
EBX:EAX |
Таблица 7 Допустимые регистры для передачи различных типов аргументов в WATCOM C
Несколько пояснений – во-первых, аргументы типа char передаются не в 8-, а в 32- разрядных регистрах, во-вторых, бросается в глаза неожиданно больше число возможных пар регистров для передачи дальнего указателя, причем сегмент может передаваться не только в сегментных регистрах, но и 16-разрядных регистрах общего назначения.
Вещественные аргументы могут передаваться через стек сопроцессора – для этого достаточно лишь указать '8087' вместо названия регистра и обязательно скомпилировать программу с ключом –7 (или –fpi, -fpu87), показывая компилятору, что инструкции сопроцессора разрешены. В документации по WATCOM сообщается, что аргументы типа double могут так же передаваться и через пары 32-разрядных регистров общего назначения, но мне, увы, не удалось заставить компилятор генерировать такой код. Может быть, я плохо знаю WATCOM или глюк какой. Так же, мне не встречалось ни одной программы, в которой вещественные значения передавались бы через регистры общего назначения. Впрочем, это уже никому не нужные тонкости. (Подробнее о передаче вещественных аргументов рассказывается в одноименном разделе данной главы).
Таким образом, при исследовании программ, откомпилированных компилятором WATCOM, необходимо быть готовыми к тому, что аргументы могут передаваться практически в любых регистрах, какие заблагорассудится программисту.
::идентификация передачи и приема регистров. Поскольку, вызываемая и вызывающая функция вынуждены придерживаться общих соглашений при передаче аргументов через регистры, компилятору приходится помещать аргументы в те регистры, в каких их ожидает вызываемая функция, а не в какие ему "удобно". В результате, перед каждой функций, следующей соглашению fastcall, появляется код, "тасующий" содержимое регистров строго определенным образом. Каким – это уже зависит от конкретного компилятора. Наиболее популярные схемы передачи аргументов уже были рассмотрены выше, не будем здесь возвращаться к этому вопросу.
Если же "ваш" компилятор отсутствует в списке (что вполне вероятно, - компиляторы сейчас растут как грибы после дождя), попробуйте установить его "характер" экспериментальным путем самостоятельно или загляните в документацию. Вообще-то разработчики за редкими исключениями не раскрывают подобных тонкостей (причем даже не из-за желания утаить это в тайне, просто если документировать каждый байт компилятора, полный комплект документации не поместится и на поезд), но быть может вам повезет. Если же нет, - не беда! (см. "Техника исследования характера передачи аргументов компилятором")
Анализом кода вызывающей функции не всегда можно распознать передачу аргументов через регистры (ну, разве что их инициализация будет слишком наглядна), поэтому, приходится обращаться непосредственно к вызываемой функции. Регистры, сохраняемые в стеке сразу после получения управления функцией, в подавляющем большинстве случаев не являются регистрами, передающими аргументы и из списка "кандидатов" их можно вычеркнуть. Среди оставшихся смотрим – есть ли такие, содержимое которых используется без явной инициализации. В первом приближении через эти регистры функция и принимает аргументы. При детальном же рассмотрении проблемы всплывает несколько оговорок. Во-первых, через регистры могут передаваться (и очень часто передаются) неявные аргументы функции – указатель this, указатели на виртуальные таблицы объекта и т.д. Во-вторых, если криворукий программист, надеясь, что значение переменной после объявления должно быть равно нулю, забывает об инициализации, а компилятор помещает ее в регистр, то при анализе программы она может быть принята за аргумент функции, передаваемый через регистр. Самое интересное: что этот регистр может по случайному стечению обстоятельств явно инициализироваться вызывающей функций. Пусть, например, программист перед этим вызывал некоторую функцию, возвращаемого значения которой (помещаемого компилятором в EAX) не использовал, а компилятор поместил неинициализированную переменную в EAX.
Причем, если функция при своем нормальном завершении возвращает ноль (как часто и бывает) все может работать… Чтобы вывить такого жука, исследователю придется проанализировать алгоритм – действительно ли в EAX помещается код успешности завершения функции или же имеет место "наложение" переменных?
Впрочем, если откинуть "клинические" случаи, в передаче аргументов через регистры не сильно усложняет анализ, в чем мы сейчас и убедимся.
::практическое исследование механизма передачи аргументов через регистры. Для закрепления всего вышесказанного, давайте рассмотрим следующий пример. Обратите внимание на директивы условной компиляции, вставленные для совместимости с различными компиляторами:
#include <stdio.h>
#include <string>
#if defined(__BORLANDC__) || defined (_MSC_VER)
// Эта ветка компилируется только компиляторами Borland C++ и Microsoft C++,
// поддерживающими ключевое слово fastcall
__fastcall
#endif
// Функция MyFunc с различными типами аргументов для демонстрации механизма
// их
передачи
MyFunc(char a, int b, long int c, int d)
{
#if defined(__WATCOMC__)
// А эта ветка специально предназначена для WATCOM C.
// прагма aux принудительно задает порядок передачи аргументов через
// следующие регистры: EAX ESI EDI EBX
#pragma aux MyFunc parm [EAX] [ESI] [EDI] [EBX];
#endif
return a+b+c+d;
}
main()
{
printf("%x\n",MyFunc(0x1,0x2,0x3,0x4));
return 0;
}
Листинг 70
Результат компиляции этого примера компилятором Microsoft Visual C++ 6.0 должен выглядеть так:
main proc near ; CODE XREF: start+AFp
push ebp
mov ebp, esp
push 4
push 3
; аргументы, которым не хватило регистров, передаются через стек, заносясь
; туда справа налево и вычищает их оттуда вызываемая функция
; (т.е. все происходит как по stdcall
соглашению)
mov edx, 2
; Через EDX передается второй слева аргумент.
; Легко определить его тип – это int.
; Т.е. это явно не char, но и не указатель (2-странное значение для указателя)
mov cl, 1
; Через cl передается первый слева аргумент типа char
;(лишь у переменных типа char размер 8 бит)
;
call MyFunc
; Уже можно восстановить прототип функции MyFunc(char, int, int, int)
; Да, мы ошиблись и тип long int приняли за int, но, поскольку в компиляторе
; Microsoft Visual C++ эти типы идентичны, такой ошибкой можно пренебречь
push eax
; Передаем полученный результат функции printf
push offset asc_406030 ; "%x\n"
call _printf
add esp, 8
xor eax, eax
pop ebp
retn
main endp
MyFunc proc near ; CODE XREF: main+Ep
var_8 = dword ptr -8
var_4 = byte ptr –4
arg_0 = dword ptr 8
arg_4 = dword ptr 0Ch
; Через стек функции передавались лишь два аргумента и их успешно распознала IDA
push ebp
mov ebp, esp
sub esp, 8
; Резервируем 8 байт для локальных переменных
mov [ebp+var_8], edx
; Регистр EDX не был явно инициализирован до того загрузки в
; локальную переменную var_8. Значит, он используется для передачи аргументов!
; Поскольку эта программа была скомпилирована компилятором Microsoft Visual C,
; а он, как известно, передает аргументы в регистрах ECX:EDX можно сделать
; вывод, что мы имеем дело со вторым, считая слева, аргументом функции
; и где-то ниже по тексту нам должно встретиться обращение к ECX
– первому
; слева аргументу функции.
; (хотя не обязательно – первый аргумент функцией может и не использоваться)
mov [ebp+var_4], cl
; Действительно, обращение к CL не заставило должно себя ждать. Поскольку,
; через CL передается тип char, то, вероятно, первый аргумент функции – char.
; Некоторая неуверенность вызвана тем, что функция может просто обращаться
; к младшему байту аргумента типа int, скажем.
; Однако, посмотрев на код вызывающей функции, мы можем убедиться, что
; функции передается именно char, а не int.
; Попутно отметим глупость компилятора – стоило ли передавать аргументы через
; регистры, чтобы тут же заслать их в локальные переменные!
; Ведь обращение к памяти сжирает всю выгоду от быстрого вызова!
; Такой "быстрый" вызов быстрым даже язык не поворачивается назвать.
movsx eax, [ebp+var_4]
; В EAX загружается первый слева аргумент, переданный через CL, типа char
; со знаковым расширением до двойного слова. Значит, это signed char
; (т.е. char по умолчанию для Microsoft Visual C++)
add eax, [ebp+var_8]
; Складываем EAX со вторым слева аргументом
add eax, [ebp+arg_0]
; Складываем результат предыдущего сложения с третьим слева аргументом,
; переданным через стек…
add eax, [ebp+arg_4]
; …и все это складываем с четвертым аргументом, так же переданным через стек.
mov esp, ebp
pop ebp
; Закрываем кадр стека
retn 8
; Чистим за собой стек, как и положено по fastcall
соглашению
MyFunc endp
Листинг 71
А теперь сравним это с результатом компиляции Borland C++:
; int __cdecl main(int argc,const char **argv,const char *envp)
_main proc near ; DATA XREF: DATA:00407044o
argc = dword ptr 8
argv = dword ptr 0Ch
envp = dword ptr 10h
push ebp
mov ebp, esp
push 4
; Передаем аргумент через стек. Скосив глаза вниз, мы обнаруживаем явную
; инициализацию регистров ECX, EDX, AL. Для четвертого аргумента регистров
; не хватило и его пришлось передавать через стек. Значит, четвертый слева
; аргумент функции – 0x4
mov ecx, 3
mov edx, 2
mov al, 1
; Этот код не может быть ничем иным, как передачей аргументов через регистры
call MyFunc
push eax
push offset unk_407074 ; format
call _printf
add esp, 8
xor eax, eax
pop ebp
retn
_main endp
MyFunc proc near ; CODE XREF: _main+11p
arg_0 = dword ptr 8
; через стек функции передавался лишь один аргумент
push ebp
mov ebp, esp
; Открываем кадр стека
movsx eax, al
; Borland
сгенерировал более оптимальный код, чем Microsoft, не помещая
; регистр в локальную переменную и экономя тем самым память. Впрочем, если бы
; был задан соответствующий ключ оптимизации, Microsoft Visual C++ поступил
; точно так же.
; Обратите внимание еще и на то, что Borland
обрабатывает аргументы
; в выражениях слева направо в порядке их перечисления в прототипе функции,
; в то время как Microsoft Visual C++ поступает наоборот.
add edx, eax
add ecx, edx
; Регистры EDX и CX не были инициализированы, значит, в них функции были
; переданы аргументы.
mov edx, [ebp+arg_0]
; Загружаем в EDX последний аргумент функции, переданный через стек…
add ecx, edx
; …складываем еще раз
mov eax, ecx
; Передаем в EAX (в EAX функция возвращает результат своего завершения)
pop ebp
retn 4
; Вычищаем за собой стек
MyFunc endp
Листинг 72
Наконец, результат компиляции WATCOM C должен выглядеть так:
main_ proc near ; CODE XREF: __CMain+40p
push 18h
call __CHK
; Проверка стека на переполнение
push ebx
push esi
push edi
; Сохраняем регистры в стеке
mov ebx, 4
mov edi, 3
mov esi, 2
mov eax, 1
; Смотрите, аргументы передаются через те аргументы, которые мы указали!
; Более того, отметьте, что первый аргумент типа char
передается через
; 32-разрядный регистр EAX! Такое поведение WATCOM-а чрезвычайно
; затрудняет восстановление прототипов функций! В данном случае присвоение
; регистрам значений происходит согласно порядку объявления аргументов
; в прототипе функции, считая справа. Но так, увы, бывает далеко не всегда.
call MyFunc
push eax
push offset unk_420004
call printf_
add esp, 8
xor eax, eax
pop edi
pop esi
pop ebx
retn
main_ endp
MyFunc proc near ; CODE XREF: main_+21p
; Функция не принимает через стек ни одного аргумента
push 4
call __CHK
and eax, 0FFh
; Обнуление старших двадцати четырех бит вкупе с обращением к регистру
; до его инициализации наводит на мысль, что через EAX
передается тип char
; какой это аргумент мы сказать не можем, увы...
add esi, eax
; Регистр ESI не был инициализирован нашей функцией, следовательно, через
; него передается аргумент типа int. Можно предположить, что это – второй
; слева аргумент в прототипе функции, т.к. (если ничто не препятствует),
; регистры в вызывающей функции инициализируются согласно их порядку
; перечисления в прототипе, считая справа, а выражения вычисляются
; слева направо.
; Разумеется, подлинный порядок следования аргументов некритичен, но
; все-таки приятно, если удается его восстановить
lea eax, [esi+edi]
; Опаньки, выдерем Тигре хвост с корнем! Вы думаете, что в EAX
загружается
; указатель? А ESI и EDI переданные функции – так же указатели? EAX
с его
; типом char становится очень похожим на индекс...
; Увы! Компилятор WATCOM слишком хитер и при анализе программ,
; скомпилированных с его помощью, очень легко впасть в грубые ошибки.
; Да, EAX это указатель, в том смысле, что LEA
используется для вычисления
; суммы ESI и EDI, но обращения к памяти по этому указателю не происходит
; ни в вызывающей, ни в вызываемой функции. Следовательно, аргументы функции
; не указатели, а константы!
add eax, ebx
; Аналогично – EDX содержит в себе аргумент, переданный функции.
; Итак, прототип функции должен быть выглядеть так:
; MyFunc(char a, int b, int c, int d)
; Однако, порядок следования аргументов может быть и иным...
retn
MyFunc endp
Листинг 73
Как мы видим, в передаче аргументов через регистры ничего особенного сложно нет, можно даже восстановить подлинный прототип вызываемой функции.
Однако ситуация, рассмотренная выше, достаточно идеализирована, и в реальных программах передача одних лишь непосредственных значений встречается редко. Давайте же теперь, освоившись с быстрыми вызовами, дизассемблируем более трудный пример:
#if defined(__BORLANDC__) || defined (_MSC_VER)
__fastcall
#endif
MyFunc(char a, int *b, int c)
{
#if defined(__WATCOMC__)
#pragma aux MyFunc parm [EAX] [EBX] [ECX];
#endif
return a+b[0]+c;
}
main()
{
int a=2;
printf("%x\n",MyFunc(strlen("1"),&a,strlen("333")));
}
Листинг 74 Трудный пример с fastcall
Результат компиляции Microsoft Visual C++ должен выглядеть так:
main proc near ; CODE XREF: start+AFp
var_4 = dword ptr -4
push ebp
mov ebp, esp
; Открываем кадр стека
push ecx
push esi
; Сохраняем регистры в стеке
mov [ebp+var_4], 2
; Присваиваем локальной переменной var_4 типа int
значение 2.
; Тип определяется на основе того, что переменная занимает 4 байта
; (подробнее см. "Идентификация локальных стековых переменных")
push offset a333 ; const char *
; Передаем функции strlen указатель на строку "333".
; Аргументы функции MyFunc как и положено передаются справа налево
call _strlen
add esp, 4
push eax
; Здесь – либо мы сохраняем возвращенное функцией значение в стеке,
; либо передаем его следующей функции.
lea esi, [ebp+var_4]
; В ESI заносим указатель на локальную переменную var_4
push offset a1 ; const char *
; Передаем функции strlen указатель на строку "1"
call _strlen
add esp, 4
mov cl, al
; Возвращенное значение копируется в регистр CL, а ниже инициализируется EDX.
; Поскольку, ECX:EDX
используются для передачи аргументов fastcall-функциям,
; инициализация этих двух регистров перед вызовом функции явно не случайна!
; Можно предположить, что через CL
передается крайний левый аргумент типа char
mov edx, esi
; В ESI содержится указатель на var_4, следовательно, второй аргумент функции,
; типа int, заносимый в EDX, передается по ссылке.
call MyFunc
; Предварительный прототип функции выглядит так:
; MyFunc(char *a, int *b, inc c)
; Откуда взялся аргумент с? А помните, выше в стек был затолкнут EAX
и
; ни до вызова функции, ни после так и не вытолкнут? Впрочем, чтобы
; убедится в этом окончательно, требуется посмотреть сколько байт со стека
; снимает вызываемая функция
; Обратите так же внимание и на то, что значения, возвращенные функцией strlen,
; не заносилось в локальные переменные, а передавались непосредственно MyFunc.
; Это наводит на мысль, что исходный код программы выглядел так:
; MyFunc(strlen("1"),&var_4,strlen("333"));
; Хотя, впрочем, не факт, - компилятор мог оптимизировать код, выкинув
; локальную переменную, если она нигде более не используется. Однако,
; во-первых, судя по коду вызываемой функции компилятор работает без
; оптимизации, а во-вторых, если значения, возвращенные функциями strlen,
; используются один единственный раз в качестве аргумента MyFunc, то помещение
; их в локальную переменную – большая глупость, только затуманивающая суть
; программы. Тем более, что исследователю важно не восстановить подлинный
; исходный код, а понять его алгоритм.
push eax
push offset asc_406038 ; "%x\n"
call _printf
add esp, 8
pop esi
mov esp, ebp
pop ebp
; Закрываем кадр стека
retn
main endp
MyFunc proc near ; CODE XREF: main+2Ep
var_8 = dword ptr -8
var_4 = byte ptr -4
arg_0 = dword ptr 8
; Функция принимает один аргумент – значит, это и есть тот EAX, занесенный в стек
push ebp
mov ebp, esp
; Открываем кадр стека
sub esp, 8
; Резервируем восемь байт под локальные переменные
mov [ebp+var_8], edx
; Поскольку, EDX используется без явной инициализации, очевидно,
; через него передается второй слева аргумент функции.
; (согласно соглашению fastcall компилятора Microsoft Visual C++)
; Из анализа кода вызывающей функции мы уже знаем,
; что в EDX помещается указатель на var_4, следовательно,
; var_8 теперь содержит указатель на var_4.
mov [ebp+var_4], cl
; Через CL передается самый левый аргумент функции типа char
и тут же
; заносится в локальную переменную var_4.
movsx eax, [ebp+var_4]
; Переменная var_4 расширяется до signed int.
mov ecx, [ebp+var_8]
; В регистр ECX загружается содержимое указателя var_8, переданного через EDX.
; Действительно, как мы помним, через EDX
функции передавался указатель.
add eax, [ecx]
; Складываем EAX (хранит первый слева аргумент функции) с содержимым
; ячейки памяти, на которую указывает указатель ECX
(второй слева аргумент).
add eax, [ebp+arg_0]
; А вот и обращение к тому аргументу функции, что был передан через стек
mov esp, ebp
pop ebp
; Закрываем кадр стека
retn 4
; Функции был передан 1 аргумент через стек
MyFunc endp
Листинг 75
Просто? Просто! Тогда рассмотрим результат творчества Borland C++, который должен выглядеть так:
; int __cdecl main(int argc,const char **argv,const char *envp)
_main proc near ; DATA XREF: DATA:00407044o
var_4 = dword ptr -4
argc = dword ptr 8
argv = dword ptr 0Ch
envp = dword ptr 10h
push ebp
mov ebp, esp
; Открываем кадр стека
push ecx
; Сохраняем ECX... Постойте! Это что-то новое! В прошлых примерах Borland
; никогда не сохранял ECX при входе в функцию. Очень похоже, что через ECX
; функции был передан какой-то аргумент, и теперь она передает его другой
; функции через стек.
; Увы, каким бы убедительным такое решение ни выглядело оно неверно!
; Компилятор просто резервирует под локальные переменные четыре байта. Почему?
; Из чего это следует? Смотрите: IDA
распознала одну локальную переменную var_4
; но память под нее явно не резервировалась, во всяком случае команды SUB ESP,4
; не было. Постой-ка, постой, но ведь PUSH ECX
как раз и приводит к уменьшению
; регистра ESP на четыре! Ох, уж эта оптимизация!
mov [ebp+var_4], 2
; Заносим в локальную переменную значение 2
push offset a333 ; s
; Передаем функции strlen указатель на строку "333"
call _strlen
pop ecx
; Выталкиваем аргумент из стека
push eax
; Здесь – либо мы передаем возращенное функцией strlen
значение следующей
; функции как стековый аргумент, либо временно сохраняем EAX
в стеке
; (позже выяснится, что справедливо последнее предположение)
push offset a1 ; s
; Передаем функции strlen указатель на строку "1"
call _strlen
pop ecx
; Выталкиваем аргумент из стека
lea edx, [ebp+var_4]
; Загружаем в EDX смещение локальной переменной var_4
pop ecx
; Что-то выталкиваем из стека, но что именно? Прокручивая экран
; дизассемблера вверх, находим, что последним в стек заносился EAX,
; содержащий значение, возвращенное функцией strlen("333").
; Теперь оно помещается в регистр ECX
; (как мы помним, Borland передает через него второй слева аргумент)
; Попутно отметим для любителей fastcall-а: не всегда он приводит к одидаемому
; ускорению вызова, - у Intel 80x86 слишком мало регистров и их то и дело
; приходится сохранять в стеке.
; Передача аргумента через стек потребовала бы всего одного обращения: PUSH EAX
; здесь же мы наблюдаем два – PUSH EAX
и POP ECX!
call MyFunc
; При восстановлении прототипа функции не забудьте о регистре EAX, - он
; не инициализируется явно, но хранит значение, возращенное последним вызовом
; strlen. Поскольку, компилятор Borland C++ 5.x
использует следующий список
; предпочтений: EAX, EDX, ECX
можно сделать вывод, что в EAX
передается первый
; слева аргумент функции, а два остальных в EDX
и ECX
соответственно.
; Обратите внимание и на то, что Borland C++, в отличие от Microsoft Visual C++
; обрабатывает аргументы не в порядке их перечисления, а сначала вычисляет
; значение всех функций, "выдергивая" их справа налево, и только
; потом переходит к переменным и константам.
; И в этом есть свой здравый смысл – функции
; изменяют значение многих регистров общего назначения и, до тех пор пока не
; будет вызвана последняя функция, нельзя приступать к передаче аргументов
; через регистры.
push eax
push offset asc_407074 ; format
call _printf
add esp, 8
xor eax, eax
; Возвращаем нулевое значение
pop ecx
pop ebp
; Закрываем кадр стека
retn
_main endp
MyFunc proc near ; CODE XREF: _main+26p
push ebp
mov ebp, esp
; Открываем кадр стека
movsx eax, al
; Расширяем EAX до знакового двойного слова
mov edx, [edx]
; Загружаем в EDX содержимое ячейки памяти, на которую указывает указатель EDX
add eax, edx
; Складываем первый аргумент функции с переменной типа int, переданной
; вторым аргументом по ссылке
add ecx, eax
; Складываем третий аргумент типа int
с результатом предыдущего сложения
mov eax, ecx
; Помещаем результат обратно в EAX
; Глупый компилятор, не проще ли было переставить местами аргументы предыдущей
; команды?
pop ebp
; Закрываем кадр стека
retn
MyFunc endp
Листинг 76
А теперь рассмотрим результат компиляции того же примера компилятором WATCOM C, у которого всегда есть чему поучиться:
main_ proc near ; CODE XREF: __CMain+40p
var_C = dword ptr -0Ch
; Локальная переменная
push 18h
call __CHK
; Проверка стека на переполнение
push ebx
push ecx
; Сохранение модифицируемых регистров
; Или – быть может, резервирование памяти под локальные переменные?
sub esp, 4
; Вот это уж точно явное резервирование памяти под одну локальную переменную,
; следовательно, две команды PUSH, находящиеся выше, действительно сохраняют
; регистры.
mov [esp+0Ch+var_C], 2
; Занесение в локальную переменную значения 2
mov eax, offset a333 ; "333"
call strlen_
; Обратите внимание – WATCOM передает функции strlen указатель на строку
; через регистр!
mov ecx, eax
; Возращенное функцией значение копируется в регистр ECX.
; WATCOM
знает, что следующий вызов strlen
не портит этот регистр!
mov eax, offset a1 ; "1"
call strlen_
and eax, 0FFh
; Поскольку strlen возвращает тип int, здесь имеет место явное преобразование
; типов: int -> char
mov ebx, esp
; В EBX заносится указатель на переменную var_C
call MyFunc
; Какие же аргументы передавались функции? Во-первых, EAX
– вероятно крайний
; левый аргумент, во-вторых, EBX – явно инициализированный перед вызовом
; функции, и, вполне возможно, ECX, хотя последнее и не обязательно.
; ECX
может содержать и регистровую переменную, но в таком случае вызываемая
; функция не должна к нему обращаться.
push eax
push offset asc_42000A ; "%x\n"
call printf_
add esp, 8
add esp, 4
; А еще говорят, что WATCOM – оптимизирующий компилятор! А вот две команды
; объединить в одну, он увы не смог!
pop ecx
pop ebx
retn
main_ endp
MyFunc proc near ; CODE XREF: main_+33p
push 4
call __CHK
; Проверка стека
and eax, 0FFh
; Повторное обнуление 24-старших бит. WATCOM-у следовало бы определиться:
; где выполнять эту операцию – в вызываемой или вызывающей функции, но зато
; подобный "дублеж" упрощает восстановление прототипов функций
add eax, [ebx]
; Складываем EAX типа char и теперь расширенное до int с переменной типа int
; переданной по ссылке через регистр EBX
add eax, ecx
; Ага, вот оно обращение к ECX, - следовательно, этот регистр использовался
; для передачи аргументов
retn
; Таким образом, прототип функции должен выглядеть так:
; MyFunc(char EAX, int *EBX, int ECX)
; Обратите внимание, что восстановить его удалось лишь совместным анализом
; вызываемой и вызывающей функций!
MyFunc endp
Листинг 77
::передача вещественных значений. Кодоломатели в своей массе не очень-то разбираются в вещественной арифметике, избегая ее как огня. Между тем, в ней нет ничего сверхсложного и освоить управление сопроцессором можно буквально за полтора-два дня. Правда, с математическими библиотеками, поддерживающими вычисления с плавающей запятой, справиться намного труднее, (особенно если IDA не распознает имен их функций), но какой компилятор сегодня пользуется библиотеками? Микропроцессор и сопроцессор монтируются на одном кристалле, и сопроцессор, начиная с 80486DX (если мне не изменяет память), доступен всегда, поэтому, прибегать к его программной эмуляции нет никакой нужды.
До конца девяностых среди хакеров бытовало мнение, что можно всю жизнь прожить, но так и не столкнуться с вещественной арифметикой. Действительно, в старые добрые времена процессоры в своей медлительности ни в чем не уступали черепахам, сопроцессоры имелись не у всех, а задачи, стоящие перед компьютерами, допускали (не без ухищрений, правда) решения и в целочисленной арифметике.
Сегодня все кардинально изменилось. Вычисления с плавающей точкой, выполняемые сопроцессором параллельно с работой основной программы, даже быстрее целочисленных вычислений, обсчитываемых основным процессором. И программисты, окрыленные такой перспективой, стали лепить вещественные типы данных даже там, где раньше с лихвой хватало целочисленных. (Например, если a=b/c*100, то, изменив порядок вычислений a=b*100/c, мы можем обойтись и типами int).
Современным исследователям программ без значения команд сопроцессора очень трудно обойтись.
Сопроцессоры 80x87 поддерживают три вещественных типа данных: короткий 32-битный, длинный 64-битный и расширенный
80-битный, соответствующие следующим типам языка Си: float, double и long double. {>>> сноска Внимание: Стандарт ANSI С не оговаривает точного представления указанных выше типов и это утверждение справедливо только для платформы PC, да и то не для всех реализаций}
|
тип |
размер |
диапазон значений |
предпочтительные типы передачи |
|
float |
4 байта |
10-38...10+38 |
регистры CPU, стек CPU, стек FPU |
|
double |
8 байт |
10-308...10+308 |
регистры CPU, стек CPU, стек FPU |
|
long double |
10 байт |
10-4932...10+4932 |
стек CPU, стек FPU |
|
real[3] |
6 байт |
2.9*10-39...1.7*10+38 |
регистры CPU, стек CPU, стек FPU |
Аргументы типа float и double могут быть переданы функции тремя различными способами: через регистры общего назначения основного процессора, через стек основного процессора и через стек сопроцессора. Аргументы типа long double потребовали бы для своей передачи слишком много регистров общего назначения, поэтому, в подавляющем большинстве случаев они заталкиваются в стек основного процессора или сопроцессора.
Первые два способа передачи нам уже знакомы, а вот третий – это что-то новенькое! Сопроцессор 80x87 имеет восемь восьмидесятибитных регистров, обозначаемых ST(0), ST(1), ST(2), ST(3), ST(4), ST(5), ST(6) и ST(7), организованных в форме кольцевого стека. Это обозначает, что большинство команд сопроцессора не оперируют номерами регистров, а в качестве приемника (источника) используют вершину стека. Например, чтобы сложить два вещественных числа сначала необходимо затолкнуть их в стек сопроцессора, а затем вызывать команду сложения, суммирующую два числа, лежащих на вершине стека, и возвращающую результат свой работы опять-таки через стек.
Существует возможность сложить число, лежащее в стеке сопроцессора с числом, находящимся в оперативной памяти, но непосредственно сложить два числа из оперативной памяти невозможно!
Таким образом, первый этап операций с вещественными типами – запихивание их в стек сопроцессора. Эта операция осуществляется командами из серии FLDxx, перечисленных с краткими пояснениями в таблице 9. В подавляющем большинстве случаев используется инструкция "FLD источник", заталкивающая в стек сопроцессора вещественное число из оперативной памяти или регистра сопроцессора. Строго говоря, это не одна команда, а четыре команды в одной упаковке с опкодами 0xD9 0x0?, 0xDD 0x0?, 0xDB 0x0? и 0xD9 0xCi, для загрузки короткого, длинного, расширенного типов и регистра FPU соответственно, где ? – адресное поле, уточняющие в регистре или в памяти находится операнд, а 'i' – индекс регистра FPU.
Отсутствие возможности загрузки вещественных чисел из регистров CPU, обессмысливает их использование для передачи аргументов типа float, double или long double. Все равно, чтобы затолкать эти аргументы в стек сопроцессора, вызываемая функция будет вынуждена скопировать содержимое регистров в оперативную память. Как ни крути, от обращения к памяти не избавишься. Вот поэтому-то, регистровая передача вещественных типов крайне редка и в подавляющем большинстве случаев они, как и обычные аргументы, передаются через стек основного процессора или через стек сопроцессора. (Последнее умеют только продвинутые компиляторы, в частности WATCOM, но не Microsoft Visual C++ и не Borland C++).
Впрочем, некоторые "избранные" значения могут загружаться и без обращений к памяти, в частности, существуют команды для заталкивания в стек сопроцессора чисел ноль, один, ? и некоторые другие – полный список приведен в таблице 9.
Любопытной особенностью сопроцессора является поддержка операций с целочисленными вычислениями. Мне не известно ни одного компилятора, использующего эту возможность, но такой прием иногда встречается в ассемблерных вставках, поэтому, пренебрегать изучением целочисленных команд сопроцессора все же не стоит.
|
Команда |
Назначение |
|
FLD источник |
Заталкивает вещественное число из источника на вершину стека сопроцессора |
|
FSTP приемник |
Выталкивает вещественное число из вершины стека сопроцессора в приемник |
|
FST приемник |
Копирует вещественное число из вершины стека сопроцессора в приемник |
|
FLDZ |
Заталкивает ноль на вершину стека сопроцессора |
|
FLD1 |
Заталкивает единицу на вершину стека сопроцессора |
|
FLDPI |
Заталкивает на вершину стека сопроцессора число ? |
|
FLDL2T |
Заталкивает на вершину стека сопроцессора двоичный логарифм десяти |
|
FLDL2E |
Заталкивает на вершину стека сопроцессора двоичный логарифм числа e |
|
FLDLG2 |
Заталкивает на вершину стека сопроцессора десятичный логарифм двух |
|
FLDLN2 |
Заталкивает на вершину стека сопроцессора натуральный логарифм двух |
|
FILD источник |
Заталкивает целое число из источника на вершину стека сопроцессора |
|
FIST приемник |
Копирует целое число с вершины стека сопроцессора в приемник |
|
FISTP приемник |
Выталкивает целое число с вершины стека сопроцессора в приемник |
|
FBLD источник |
Заталкивает десятичное число из приемника на вершину стека сопроцессора |
|
FBSTP приемник |
Копирует десятичное число с вершины стека сопроцессора в приемник |
|
FXCH ST(индекс) |
Обмен значениями между вершиной стека сопроцессора и регистром ST(индекс) |
Типы double
и long double занимают более одного машинного слова и через стек основного процессора передаются за несколько итераций. Это приводит к тому, что анализ кода вызывающей функции не всегда позволяет установить количество и тип передаваемых вызываемой функции аргументов. Выход – в исследовании алгоритма работы вызываемой функции. Поскольку сопроцессор не может самостоятельно определить тип операнда, находящегося в памяти (т.е. не знает: сколько ячеек он занимает), за каждым типом закрепляется "своя" команда.
Синтаксис ассемблера скрывает эти различия, позволяя программисту абстрагироваться от тонкостей реализации (а еще говорят, что ассемблер – язык низкого уровня), и мало кто знает, что FADD [float] и FADD [double] это разные машинные инструкции с опкодами 0xD8 ??000??? и 0xDC ??000??? соответственно. Плохая новость, помет Тигры! Анализ дизассемблерного листинга не дает никакой информации о вещественных типах – для получения этой информации приходится спускаться на машинный уровень, вгрызаясь в шестнадцатеричные дампы инструкций.
В таблице 10 приведены опкоды основных команд сопроцессора, работающих с памятью. Обратите внимание, что с вещественными значениями типа long double непосредственные математические операции невозможны – прежде их необходимо загрузить в стек сопроцессора.
|
Команда |
Тип |
||
|
короткий (float) |
длинный (double) |
расширенный (long double) |
|
|
FLD |
0xD9 ??000??? |
0xDD ??000??? |
0xDB ??101??? |
|
FSTP |
0xD9 ??011??? |
0xDD ??011??? |
0xDB ??111??? |
|
FST |
0xD9 ??010??? |
0xDD ??010??? |
нет |
|
FADD |
0xD8 ??000??? |
0xDC ??000??? |
нет |
|
FADDP |
0xDE ??000??? |
0xDA ??000??? |
нет |
|
FSUB |
0xD8 ??100??? |
0xDC ??100??? |
нет |
|
FDIV |
0xD8 ??110??? |
0xDC ??110??? |
нет |
|
FMUL |
0xD* ??001??? |
0xDC ??001??? |
нет |
|
FCOM |
0xD8 ??010??? |
0xDC ??010??? |
нет |
|
FCOMP |
0xD8 ??011??? |
0xDC ??011??? |
нет |
Замечание о вещественных типах языка Turbo Pascal. Вещественные типы языка Си вследствие его машиноориентированности совпадают с вещественными типами сопроцессора, что логично. Основной же вещественный тип Turbo Pascal-я, - Real, занимает 6 байт и противоестественен для машины. Поэтому, при вычислениях через сопроцессор он программно переводится в Extended тип (long double в терминах Си). Это "съедает" львиную долю производительности, но других типов встроенная математическая библиотека, призванная заменить собой сопроцессор, увы - не поддерживает.
При наличии же "живого" сопроцессора появляются чисто процессорные типы Single, Double, Extended и Comp, соответствующие float, double, long double и __int64.
Функциям математической библиотеки, обеспечивающий поддержу вычислений с плавающей запятой, вещественные аргументы передаются через регистры: в AX, BX, DX помещается первый слева аргумент, а в CX, SI, DI – второй (если он есть). Системные функции сопряжения с интерфейсом процессора (в частности, функции преобразования Real в Extended) принимают аргументы через регистры, а результат возвращают через стек сопроцессора. Наконец, прикладные функции и процедуры получают вещественные аргументы через стек основного процессора.
В зависимости от настроек компилятора программа может компилироваться либо с использованием встроенной математической библиотеки (по умолчанию), либо с непосредственным вызовом команд сопроцессора (ключ N$+). В первом случае программа вообще не использует возможности сопроцессора, даже если он и установлен на машине. Во втором же: при наличии сопроцессора возлагает все вычислительные возможности на него, а если он отсутствует, попытка вызова сопроцессорных команд приводит к генерации основным процессором исключения int 0x7. Его "отлавливает" программный эмулятор сопроцессора – фактически та же самая встроенная библиотека поддержки вычислений с плавающей точкой.
Что ж, теперь мы общих чертах представляем себе как происходит передача вещественных аргументов и горим нетерпением увидеть как это происходит "в живую". Для начала возьмем тривиальный пример:
#include <stdio.h>
float MyFunc(float a, double b)
{
#if defined(__WATCOMC__)
#pragma aux MyFunc parm [8087];
// Компилить с ключом -7
#endif
return a+b;
}
main()
{
printf("%f\n",MyFunc(6.66,7.77));
}
Листинг 78 Демонстрация передачи функции вещественных аргументов
Результат компиляции Microsoft Visual C++ должен выглядеть так:
main proc near ; CODE XREF: start+AFp
var_8 = qword ptr -8
; Локальная переменная, занимающая судя по всему 8 байт
push ebp
mov ebp, esp
; Открываем кадр стека
push 401F147Ah
; К сожалению IDA не может представить операнд в виде числа с плавающей запятой
; К тому же у нас нет возможности определить, что это именно вещественное число
; Его тип может быть каким угодно: и int, и указателем
; (кстати, оно очень похоже на указатель).
push 0E147AE14h
push 40D51EB8h
; "Черновой" вариант прототипа выглядит так: MyFunc(int a, int b, int c)
call MyFunc
add esp, 4
; Хвост Тигра! Со стека снимается только одно машинное слово, тогда как
; ложится туда три!
fstp [esp+8+var_8]
; Стягиваем со стека сопроцессора какое-то вещественное число. Чтобы узнать
; какое, придется нажать <ALT-O>, выбрать в открывшемся меню пункт
; "Text representation", и в
нем в окно "Number of opcode bytes" ввести
; сколько знакомест отводится под опкод команд, например, 4.
; Тут же слева от FSTP появляется ее машинное представление - DD 1C 24
; По таблице 10 определяем тип данных с которым манипулирует эта команда.
; Это – double. Следовательно функция возвратила в через стек сопроцессора
; вещественное значение.
; Раз функция возвращает вещественные значения, вполне возможно, что она их и
; принимает в качестве аргументов. Однако, без анализа MyFunc
подтвердить это
; предположение невозможно.
push offset aF ; "%f\n"
; Передаем функции printf указатель на строку спецификаторов, предписывая ей
; вывести одно вещественное число. Но... при этом мы его не заносим в стек!
; Как же так?! Прокручиваем окно дизассемблера вверх, параллельно с этим
; обдумывая все возможные пути разрешения ситуации.
; Внимательно рассматривая команду "FSTP [ESP+8+var_8]" попытаемся вычислить
; куда же она помещает результат своей работы.
; IDA
определила var_8 как "qword ptr
–8", следовательно [ES+8-8] эквивалентно
; [ESP], т.е. вещественная переменная стягивается прямо на вершину стека.
; А что у нас на вершине? Два аргумента, переданных MyFunc
и так и не
; вытолкнутых из стека. Какой хитрый компилятор! Он не стал создавать локальную
; переменную, а использовал аргументы функции для временного хранилища данных!
call _printf
add esp, 0Ch
; Выталкиваем со стека три машинных слова
pop ebp
retn
main endp
MyFunc proc near ; CODE XREF: sub_401011+12p
var_4 = dword ptr -4
arg_0 = dword ptr 8
arg_4 = qword ptr 0Ch
; Смотрим – IDA обнаружила только два аргумента, в то время как функции передавалось
; три машинных слова! Очень похоже, что один из аргументов занимает 8 байт...
push ebp
mov ebp, esp
; Открываем кадр стека
push ecx
; Нет, это не сохранение ECX – это резервирование памяти под локальную
; переменную. Т.к. на том месте, где лежит сохраненный ECX
находится
; переменная var_4.
fld [ebp+arg_0]
; Затягиваем на стек сопроцессора вещественную переменную, лежащую по адресу
; [ebp+8] (первый слева аргумент). Чтобы узнать тип этой переменной, смотрим
; опкод инструкции FLD - D9 45 08. Ага, D9 – значит, float
; Выходит, первый слева аргумент – float.
fadd [ebp+arg_4]
; Складываем arg_0 типа float со вторым слева аргументом типа... Вы думаете,
; раз первый был float, то и второй так же будет float-ом?
; А вот и не обязательно! Лезем в опкод - DC 45 0C, значит, второй аргумент
; double, а
не float!
fst [ebp+var_4]
; Копируем значение с верхушки стека сопроцессора
;(там лежит результат сложения) в локальную переменную var_4.
; Зачем? Ну... мало ли, вдруг бы она потребовалась?
; Обратите внимание – значение не стягивается, а копируется! Т.е. оно все еще
; остается в стеке. Таким образом, прототип функции MyFunc
выглядел так:
; double MyFunc(float a, double b);
mov esp, ebp
pop ebp
; Закрываем кадр стека
retn
MyFunc endp
Листинг 79
Поскольку результат компиляции Borland C++ 5.x практически в точности идентичен уже рассмотренному выше примеру от Microsoft Visual C++ 6.x, не будем терять на него время и сразу перейдем к разбору WATCOM C (как всегда – у WATCOM-а есть чему поучиться):
main_ proc near ; CODE XREF: __CMain+40p
var_8 = qword ptr -8
; локальная переменная на 8 байт
push 10h
call __CHK
; Проверка стека на переполнение
fld ds:dbl_420008
; Закидываем на вершину стека сопроцессора переменную типа double,
; взимаемую из сегмента данных.
; Тип переменной успешно определила сама IDA, предварив его префиксом 'dbl'.
; А если бы не определила – тогда бы мы обратились к опкоду команды FLD.
fld ds:flt_420010
; Закидываем на вершину стека сопроцессора переменную типа float
call MyFunc
; Вызываем MyFunc с передачей двух аргументов через стек сопроцессора,
; значит, ее прототип выглядит так: MyFunc(float a, double b).
sub esp, 8
; Резервируем место для локальной переменной размеров в 8 байт
fstp [esp+8+var_8]
; Стягиваем с вершины стека вещественное типа double
; (тип определяется размером переменной).
push offset unk_420004
call printf_
; Ага, уже знакомый нам трюк передачи var_8 функции printf!
add esp, 0Ch
retn
main_ endp
MyFunc proc near ; CODE XREF: main_+16p
var_C = qword ptr -0Ch
var_4 = dword ptr –4
; IDA
нашла две локальные переменные
push 10h
call __CHK
sub esp, 0Ch
; Резервируем место под локальные переменные
fstp [esp+0Ch+var_4]
; Стягиваем с вершины стека сопроцессора вещественное значение типа float
; (оно, как мы помним, было занесено туда последним).
; На всякий случай, впрочем, можно удостоверится в этом, посмотрев опкод
; команды FSTP - D9 5C 24 08.
Ну, раз, 0xD9, значит, точно float.
fstp [esp+0Ch+var_C]
; Стягиваем с вершины стека сопра вещественное значение типа double
; (оно, как мы помним, было занесено туда перед float).
; На всякий случай удостоверяемся в этом, взглянув на опкод команды FSTP.
; Он есть - DD 1C 24. 0xDD – раз 0xDD, значит, действительно, double.
fld [esp+0Ch+var_4]
; Затаскиваем на вершину стека наш float
обратно и…
fadd [esp+0Ch+var_C]
; …складываем его с нашим double. Вот, а еще говорят, что WATCOM C
; оптимизирующий компилятор! Трудно же с этим согласится, раз компилятор
; не знает, что от перестановки слагаемых сумма не изменяется!
add esp, 0Ch
; Освобождаем память, ранее выделенную для локальных переменных
retn
MyFunc endp
dbl_420008 dq 7.77 ; DATA XREF: main_+A^r
flt_420010 dd 6.6599998 ; DATA XREF: main_+10^r
Листинг 80
Настала очередь компилятора Turbo Pascal for Windows 1.0. Наберем в текстовом редакторе следующий пример:
USES WINCRT;
Procedure MyProc(a:Real);
begin
WriteLn(a);
end;
VAR
a: Real;
b: Real;
BEGIN
a:=6.66;
b:=7.77;
MyProc(a+b);
END.
Листинг 81 Демонстрация передачи вещественных значений компилятором Turbo Pascal for Windows 1.0
А теперь, тяпнув с Тигрой пивка для храбрости, откомпилируем его без поддержки сопроцессора (так и происходит с настройками по умолчанию).
PROGRAM proc near
call INITTASK
call @__SystemInit$qv ; __SystemInit(void)
; Инициализация модуля SYSTEM
call @__WINCRTInit$qv
; __WINCRTInit(void)
; Инициализация модуля WINCRT
push bp
mov bp, sp
; Открываем кадр стека
xor ax, ax
call @__StackCheck$q4Word ; Stack overflow check (AX)
; Проверяем есть ли в стеке хотя бы ноль свободных байт
mov word_2030, 0EC83h
mov word_2032, 0B851h
mov word_2034, 551Eh
; Инициализируем переменную типа Real.
Что это именно Real
мы пока, конечно,
; знаем только лишь из исходного текста программы.
; Визуально отличить эту серию команд от трех переменных типа Word
невозможно.
mov word_2036, 3D83h
mov word_2038, 0D70Ah
mov word_203A, 78A3h
; Инициализируем другую переменную типа Real
mov ax, word_2030
mov bx, word_2032
mov dx, word_2034
mov cx, word_2036
mov si, word_2038
mov di, word_203A
; Передаем через регистры две переменные типа Real
call @$brplu$q4Realt1 ; Real(AX:BX:DX)+=Real(CX:SI:DI)
; К счастью, IDA "узнала" в этой функции оператор сложения и даже
; подсказала нам ее прототип.
; Без ее помощи нам вряд ли удалось понять что делает эта очень длинная и
; запутанная функция.
push dx
push bx
push ax
; Передаем возращенное значение процедуре MyProc
через стек,
; следовательно, ее прототип выглядит так: MyProc(a:Real).
call MyProc
pop bp
; Закрываем кадр стека
xor ax, ax
call @Halt$q4Word ; Halt(Word)
; Прерываем выполнение программы
PROGRAM endp
MyProc proc near ; CODE XREF: PROGRAM+5Cp
arg_0 = word ptr 4
arg_2 = word ptr 6
arg_4 = word ptr 8
; Три аргумента, переданные процедуре, как мы уже выяснили на самом деле представляют
; собой три "дольки" одного аргумента типа Real.
push bp
mov bp, sp
; Открываем кадр стека
xor ax, ax
call @__StackCheck$q4Word ; Stack overflow check (AX)
; Есть ли в стеке ноль байт?
mov di, offset unk_2206
push ds
push di
; Заталкиваем в стек указатель на буфер для вывода строки
push [bp+arg_4]
push [bp+arg_2]
push [bp+arg_0]
; Заталкиваем все три полученные аргумента в стек
mov ax, 11h
push ax
; Ширина вывода – 17 символов
mov ax, 0FFFFh
push ax
; Число точек после запятой – max
call @Write$qm4Text4Real4Wordt3 ; Write(var f; v: Real; width, decimals: Word)
; Выводим вещественное число в буфер unk_2206
call @WriteLn$qm4Text ; WriteLn(var f: Text)
; Выводим строку из буфера на экран
call @__IOCheck$qv ; Exit if error
pop bp
retn 6
MyProc endp
Листинг 82
А теперь, используя ключ '/$N+' задействуем команды сопроцессора и посмотрим: как это скажется на код:
PROGRAM proc near
call INITTASK
call @__SystemInit$qv ; __SystemInit(void)
; Инициализируем
модуль System
call @__InitEM86$qv ; Initialize software emulator
; Врубаем
эмулятор сопроцессора
call @__WINCRTInit$qv ; __WINCRTInit(void)
; Инициализируем модуль WINCRT
push bp
mov bp, sp
; Открываем кадр стека
xor ax, ax
call @__StackCheck$q4Word ; Stack overflow check (AX)
; Проверка стека на переполнение
mov word_21C0, 0EC83h
mov word_21C2, 0B851h
mov word_21C4, 551Eh
mov word_21C6, 3D83h
mov word_21C8, 0D70Ah
mov word_21CA, 78A3h
; Пока мы не можем определить тип инициализируемых переменных.
; Это с равным успехом может быть и WORD
и Real
mov ax, word_21C0
mov bx, word_21C2
mov dx, word_21C4
call @Extended$q4Real ; Convert Real to Extended
; А вот теперь мы передаем word_21C0, word_21C2 и word_21C4 функции,
; преобразующий Real в Extend с загрузкой последнего в стек сопроцессора,
; значит, word_21C0 – word_21C4 это переменная типа Real.
mov ax, word_21C6
mov bx, word_21C8
mov dx, word_21CA
call @Extended$q4Real ; Convert Real to Extended
; Аналогично – word_21C6 – word_21CA – переменная типа Real
wait
; Ждем-с пока сопроцессор не закончит свою работу
faddp st(1), st
; Складываем два числа типа extended, лежащих на вершине стека сопроцессора
; с сохранением результата в том же самом стеке.
call @Real$q8Extended ; Convert Extended to Real
; Преобразуем Extended в Real
; Аргумент передается через стек сопроцессора, а возвращается в
; регистрах AX BX DX.
push dx
push bx
push ax
; Регистры AX, BX
и DX
содержат значение типа Real,
; следовательно прототип процедуры выглядит так:
; MyProc(a:Real);
call MyProc
pop bp
xor ax, ax
call @Halt$q4Word ; Halt(Word)
PROGRAM endp
MyProc proc near ; CODE XREF: PROGRAM+6Dp
arg_0 = word ptr 4
arg_2 = word ptr 6
arg_4 = word ptr 8
; Как мы уже помним, эти три аргумента – на самом деле один аргумент типа Real
push bp
mov bp, sp
; Открываем кадр стека
xor ax, ax
call @__StackCheck$q4Word ; Stack overflow check (AX)
; Проверка стека на переполнение
mov di, offset unk_2396
push ds
push di
; Заносим в стек указатель на буфер для вывода строки
mov ax, [bp+arg_0]
mov bx, [bp+arg_2]
mov dx, [bp+arg_4]
call @Extended$q4Real ; Convert Real to Extended
; Преобразуем Real в
Extended
mov ax, 17h
push ax
; Ширина вывода 0х17 знаков
mov ax, 0FFFFh
push ax
; Количество знаков после запятой – все что есть, все и выводить
call @Write$qm4Text8Extended4Wordt3 ; Write(var f; v: Extended{st(0); width decimals: Word)
; Вывод вещественного числа со стека сопроцессора в буфер
call @WriteLn$qm4Text ; WriteLn(var f: Text)
; Печать строки из буфера
call @__IOCheck$qv ; Exit if error
pop bp
retn 6
MyProc endp
Листинг 83
::соглашения о вызовах thiscall и соглашения о вызове по умолчанию.
В Си++ программах каждая функция объекта неявно принимает аргумент this – указатель на экземпляр объекта, из которого вызывается функция. Подробнее об этом уже рассказывалось в главе "Идентификация this", поэтому не будет здесь повторяться.
По умолчанию все известные мне Си++ компиляторы используют комбинированное соглашение о вызовах – передавая явные аргументы через стек (если только функция не объявлена как fastcall), а указать this через регистр с наибольшим предпочтением (см.
таблицы 2 - 7).
Соглашения же cdecl и stdcall предписывают передать все аргументы через стек, включая неявный аргумент this, заносимый в стек в последнюю очередь – после всех явных аргументов (другими словами, this – самый левый аргумент).
Рассмотрим следующий пример:
#include <stdio.h>
class MyClass{
public:
void demo(int a);
// прототип demo в действительности выглядит так demo(this, int a)
void __stdcall demo_2(int a, int b);
// прототип demo_2 в действительности выглядит так demo_2(this, int a, int b)
void __cdecl demo_3(int a, int b, int c);
// прототип demo_2 в действительности выглядит так demo_2(this, int a, int b, int c)
};
// Реализзация функция demo, demo_2, demo_3 для экономии места опущена
main()
{
MyClass *zzz = new MyClass;
zzz->demo();
zzz->demo_2();
zzz->demo_3();
}
Листинг 84 Демонстрация передачи неявного аргумента - this
Результат компиляции этого примера компилятором Microsoft Visual C++ 6.0 должен выглядеть так (показана лишь функция main, все остальное не представляет на данный момент никакого интереса):
main proc near ; CODE XREF: start+AFp
push esi
; Сохраняем ESI в стеке
push 1
call ??2@YAPAXI@Z ; operator new(uint)
; Выделяем один байт для экземпляра объекта
mov esi, eax
; ESI
содержит указатель на экземпляр объекта
add esp, 4
; Выталкиваем аргумент из стека
mov ecx, esi
; Через ECX функции Demo передается указатель this.
; Как мы помним, компилятор Microsoft Visual C++ использует регистр ECX
; для передачи самого первого аргумента функции.
; В данном случае этим аргументом и является указатель this.
; А компилятор Borland C++ 5.x передал бы this через регистр EAX, т.к.
; он отдает ему наибольшее предпочтение (см. таблицу 4)
push 1
; Заносим в стек явный аргумент функции. Значит, это не fastcall-функция,
; иначе бы данный аргумент был помещен в регистр EDX.
Выходит,
; мы имеем дело с типом вызова по умолчанию.
call Demo
push 2
; Заталкиваем в стек первый справа аргумент
push 1
; Заталкиваем в стек второй справа аргумент
push esi
; Заталкиваем в стек неявный аргумент this.
; Такая схема передачи говорит о том, что имело место явное преобразование
; типа функции в stdcall или cdecl. Прокручивая экран дизассемблера немного
; вниз, мы видим, что стек вычищает вызываемая функция, значит, она следует
; соглашению stdcall.
call demo_2
push 3
push 2
push 1
push esi
call sub_401020
add esp, 10h
; Раз функция вычищает за собой стек сама, то она имеет либо тип по умолчанию,
; либо -- cdecl. Передача указателя this через стек подсказывает, что истинно
; второе предположение.
xor eax, eax
pop esi
retn
main endp
Листинг 85
::аргументы по умолчанию.
Для упрощения вызова функций с "хороводом" аргументов в язык Си++ была введена возможность задания аргументов по умолчанию. Отсюда возникает вопрос – отличается ли чем ни будь вызов функций с аргументами по умолчанию от обычных функций? И кто инициализирует опущенные аргументы вызываемая или вызывающая функция?
Так вот, при вызове функций с аргументами по умолчанию, компилятор самостоятельно добавляет недостающие аргументы, и вызов такой функции ни чем не отличается от вызова обычных функций.
Докажем это на следующем примере:
#include <stdio.h>
MyFunc(int a=1, int b=2, int c=3)
{
printf("%x %x %x\n",a,b,c);
}
main()
{
MyFunc();
}
Листинг 86 Демонстрация передачи аргументов по умолчанию
Результат его компиляции будет выглядеть приблизительно так (для экономии места показана только вызывающая функция):
main proc near ; CODE XREF: start+AFp
push ebp
mov ebp, esp
push 3
push 2
push 1
; Как видно, все опущенные аргументы были переданы функции
; самим компилятором
call MyFunc
add esp, 0Ch
pop ebp
retn
main endp
Листинг 87
:: техника исследования механизма передачи аргументов неизвестным компилятором. Огромное многообразие существующих компиляторов и постоянное появление новых не позволяет привести здесь всеохватывающую таблицу, расписывающую характер каждого из компиляторов. Как же быть, если вам попадается программа, откомпилированная компилятором, не освещенным данной книгой?
Если компилятор удастся опознать (например, с помощью IDA или по текстовым строкам, содержащимся в файле) остается только раздобыть его экземпляр и прогнать через него серию тестовых примеров с передачей "подопытной" функции аргументов различного типа. Нелишне изучить прилагаемую к компилятору документацию, возможно, там будут хотя бы кратно описаны все поддерживаемые им механизмы передачи аргументов.
Хуже, когда компилятор не опознается или же достать его копию нет никакой возможности. Тогда придется кропотливо тщательно исследовать взаимодействие вызываемой и вызывающей функций.
Идентификация библиотечных функций
"Сегодня целый день идет снег. Он падает, тихо кружась. Ты помнишь? Тогда тоже все было засыпано снегом - это был снег наших встреч. Он лежал перед нами, белый-белый, как чистый лист бумаги, и мне казалось, что мы напишем на этом листе повесть нашей любви"
Снегопад "Пламя"
Читая текст программы, написанный на языке высокого уровня, мы только в исключительных случаях изучаем реализацию стандартных библиотечных функций, таких, например, как printf. Да и зачем? Ее назначение известно и без того, а если и есть какие непонятки – всегда можно заглянуть в описание…
Анализ дизассемблерного листинга – дело другое. Имена функций за редкими исключениями в нем отсутствуют, и определить printf это или что-то другое "на взгляд" невозможно. Приходится вникать в алгоритм… Легко сказать! Та же printf представляет собой сложный интерпретатор строки спецификаторов – с ходу в нем не разберешься! А ведь есть и более монструозные функции. Самое обидное – алгоритм их работы не имеет никакого отношения к анализу исследуемой программы. Тот же new может выделять память и из Windows-кучи, и реализовывать собственный менеджер, но нам-то от этого что? Достаточно знать, что это именно new, - т.е. функция выделения памяти, а не free или fopen, скажем.
Доля библиотечных функций в программе в среднем составляет от пятидесяти до девяноста процентов. Особенно она велика у программ, составленных в визуальных средах разработки, использующих автоматическую генерацию кода (например, Microsoft Visual C++, DELPHI). Причем, библиотечные функции под час намного сложнее и запутаннее тривиального кода самой программы. Обидно – львиная доля усилий по анализу вылетает впустую… Как бы оптимизировать этот процесс?
Уникальная способность IDA различать стандартные библиотечные функции множества компиляторов, выгодно отличает ее от большинства других дизассемблеров, этого делать не умеющих. К сожалению, IDA (как и все, созданное человеком) далека от идеала – каким бы обширный список поддерживаемых библиотек ни был, конкретные версии конкретных поставщиков или моделей памяти могут отсутствовать.
И даже из тех библиотек, что ей известны, распознаются не все функции (о причинах будет рассказано чуть ниже). Впрочем, нераспознанная функция – это полбеды, неправильно распознанная функция – много хуже, ибо приводит к ошибкам (иногда трудноуловимым) анализа исследуемой программы или ставит исследователя в глухой тупик. Например, вызывается fopen и возвращенный ей результат спустя некоторое время передается free – с одной стороны: почему бы и нет? Ведь fopen
возвращает указатель на структуру FILE, а free ее и удаляет. А если free – никакой не free, а, скажем, fseek? Пропустив операцию позиционирования, мы не сможем правильно восстановить структуру файла, с которым работает программа.
Распознать ошибки IDA будет легче, если представлять: как именно она выполняет распознание. Многие почему-то считают, что здесь задействован тривиальный подсчет CRC (контрольной суммы). Что ж, заманчивый алгоритм, но, увы, непригодный для решения данной задачи. Основной камень преткновения – наличие непостоянных фрагментов, а именно – перемещаемых элементов (подробнее см. "Шаг четвертый Знакомство с отладчиком :: Бряк на оригинальный пароль"). И хотя при подсчете CRC перемещаемые элементы можно элементарно игнорировать (не забывая проделывать ту же операцию и в идентифицируемой функции), разработчик IDA пошел другим, более запутанным и витиеватым, но и более быстрым путем.
Ключевая идея заключается в том, что незачем тратить время на вычисление CRC, - для предварительной идентификации функции вполне сойдет и тривиальное посимвольное сравнение, за вычетом перемещаемых элементов (они игнорируются и в сравнении не участвуют). Точнее говоря, не сравнение, а поиск заданной последовательности байт в эталонной базе, организованной в виде двоичного дерева. Время двоичного поиска, как известно, пропорционально логарифму количества записей в базе. Здравый смысл подсказывает, что длина шаблона (иначе говоря, сигнатуры – т.е. сравниваемой последовательности) должна быть достаточной для однозначной идентификации функции.
Однако разработчик IDA по непонятным для меня причинам решил ограничиться только первыми тридцать двумя байтами, что (особенно с учетом вычета пролога, который у всех функций практически одинаков) – довольно мало.
И верно! Достаточно многие функции попадают на один и тот же лист дерева – возникает коллизия, - неоднозначность отождествления. Для разрешения ситуации, у всех "коллизиеных" функций подсчитывается CRC16 с тридцать второго байта до первого перемещаемого элемента и сравнивается с CRC16 эталонных функций. Чаще всего это "срабатывает", но если первый перемещаемый элемент окажется расположенным слишком близко к тридцать второму байту – последовательность подсчета контрольной суммы окажется слишком короткой, а то и вовсе равной нулю (может же быть тридцать второй байт перемещаемым элементом, - почему бы и нет?). В случае повторной коллизии – находим в функциях байт, в котором все они отличаются, и запоминаем его смещение в базе.
Все это (да просит меня разработчик IDA!) напоминает следующий анекдот: поймали туземцы немца, американца и хохла и говорят им: мол, или откупайтесь чем-нибудь, или съедим. На откуп предлагается: миллион долларов (только не спрашивайте меня: зачем туземцам миллион долларов – может, костер жечь), сто щелбанов или съесть мешок соли. Ну, американец достает сотовый, звонит кому-то… Приплывает катер с миллионом долларов и американца благополучно отпускают. Немец в это время героически съедает мешок соли, и его полуметрового спускают на воду. Хохол же ел соль, ел-ел, две трети съел, не выдержал и говорит, а, ладно, черти, бейте щелбаны. Бьет вождь его, и только девяносто ударов отщелкал, хохол не выдержал и говорит, да нате миллион, подавитесь!
Так и с IDA, - посимвольное сравнение не до конца, а только тридцати двух байт, подсчет CRC не для всей функции – а сколько случай на душу положит, наконец, последний ключевой байт – и тот то "ключевой", да не совсем. Дело в том, что многие функции совпадают байт в байт, но совершенно различны по названию и назначению.
Не верите? Тогда как вам понравится следующее:
read: write:
push ebp push ebp
mov ebp,esp mov ebp,esp
call _read call _write
pop ebp pop ebp
ret ret
Листинг 55
Тут без анализа перемещаемых элементов не обойтись! Причем, это не какой-то специально надуманный пример, - подобных функций очень много. В частности библиотеки от Borland ими так и кишат. Неудивительно, что IDA часто "спотыкается" и впадает в грубые ошибки. Взять, к примеру, следующую функцию:
void demo(void)
{
printf("DERIVED\n");
};
Даже последняя на момент написания этой книги версия IDA 4.17 ошибается, "обзывая" ее __pure_error:
CODE:004010F3 __pure_error_ proc near ; DATA XREF: DATA:004080BCvo
CODE:004010F3 push ebp
CODE:004010F4 mov ebp, esp
CODE:004010F6 push offset aDerived ; format
CODE:004010FB call _printf
CODE:00401100 pop ecx
CODE:00401101 pop ebp
CODE:00401102 retn
CODE:00401102 __pure_error_ endp
Стоит ли говорить: какие неприятные последствия для анализа эта ошибка может иметь? Бывает, сидишь, тупо уставившись в листинг дизассемблера, и никак не можешь понять: что же этот фрагмент делает? И только потом обнаруживаешь – одна или несколько функций опознаны неправильно!
Для уменьшения количества ошибок IDA пытается по стартовому коду распознать компилятор, подгружая только библиотеку его сигнатур. Из этого следует, что "ослепить" IDA очень просто – достаточно слегка видоизменить стартовый код. Поскольку, он по обыкновению поставляется вместе с компилятором в исходных текстах, сделать это будет нетрудно. Впрочем, хватит и изменения одного байта в начале startup-функции. И все, - хакер скинет ласты! К счастью, в IDA предусмотрена возможность ручной загрузки базы сигнатур ("FILE\Load file\FLIRT signature file"), но… попробуй-ка вручную определить: сигнатуры какой именно версии библиотеки требуется загружать! Наугад – слишком долго… Хорошо, если удастся визуально опознать компилятор (опытным исследователям это обычно удается, т.к.
каждый из них имеет свой уникальный "почерк"). К тому же, существует принципиальная возможность использования библиотек из поставки одного компилятора, в программе, скомпилированной другим компилятором.
Словом, будьте готовы к тому, что в один прекрасный момент столкнетесь с необходимостью самостоятельно опознавать библиотечные функции. Решение задачи состоит из двух этапов. Первое – определение самого факта "библиотечности" функции, второе – определение происхождения библиотеки и третье – идентификация функция по этой библиотеке.
Используя тот факт, что линкер обычно располагает функции в порядке перечисления obj модулей и библиотек, а большинство программистов указывают сначала собственные obj-модули, а библиотеки – потом (кстати, так же поступают и компиляторы, самостоятельно вызывающие линкер по окончании своей работы), можно заключить: библиотечные функции помещаются в конце программы, а собственно ее код – в начале. Кончено, из этого правила есть исключения, но все же срабатывает оно достаточно часто.

Рисунок 14 0х009 Художнику заштриховать что ли? Структура pkzip.exe. Обратите внимание - все библиотечные функции (голубые) в одном месте - в конце сегмента кода перед началом сегмента данных
Рассмотрим, к примеру, структуру общеизвестной программы pkzip.exe, - на диаграмме, построенной IDA 4.17, видно, что все библиотечные функции сосредоточены в одном месте – в конце сегмента кода, вплотную примыкая к сегменту данных. Самое интересное – start-up функция в подавляющем большинстве случаев расположена в самом начале региона библиотечных функций или находится в непосредственной близости от него. Найти же саму start-up не проблема – она совпадает с точкой входа в файл!
Таким образом, можно с высокой долей уверенности утверждать, что все функции, расположенные "ниже" Start-up (т.е. в более старших адресах) – библиотечные. Посмотрите – распознала ли их IDA или переложила эту заботу на вас? Грубо - возможны две ситуации: вообще никакие функции не распознаны и не распознана только часть функций.
Если не распознана ни одна функция, скорее всего IDA не сумела опознать компилятор или использовались неизвестные ей версии библиотек. Техника распознавания компиляторов – разговор особый, а вот распознание версий библиотек – это то, чем мы сейчас и займемся.
Прежде всего, многие из них содержат копирайты с названием имени производителя и версии библиотеки – просто поищите текстовые строки в бинарном файле. Если их нет, - не беда – ищем любые другие текстовые строки (как правило, сообщения об ошибках) и простым контекстным поиском пытаемся найти во всех библиотеках, до которых удастся "дотянуться" (хакер должен иметь большую библиотеку компиляторов и библиотек на своем жестком диске). Возможные варианты: никаких других текстовых строк вообще нет; строки есть, но они не уникальны – обнаруживаются во многих библиотеках; наконец, искомый фрагмент нигде не обнаружен. В первых двух случаях следует выделить из одной (нескольких) библиотечных функций характерную последовательность байт, не содержащую перемещаемых элементов, и вновь попытаться отыскать ее во всех доступных вам библиотеках. Если же это не поможет, то… увы, искомой библиотеки у вас в наличие нет и положение – ласты.
Ласты, да не совсем! Конечно, автоматически восстановить имена функций уже не удастся, но надежда на быстрое выяснение назначения функций все же есть. Имена API-функций Windows, вызываемые из библиотек, позволяют идентифицировать по крайней мере категорию библиотеки (например, работа с файлами, памятью, графикой и т.д.) Математические же функции по обыкновению богаты командами сопроцессора.
Дизассемблирование очень похоже на разгадывание кроссворда (хотя не факт, что хакеры любят разгадывать кроссворды) – неизвестные слова угадываются за счет известных. Применительно к данной ситуации – в некоторых контекстах название функции вытекает из ее использования. Например, запрашиваем у пользователя пароль, передаем ее функции X вместе с эталонным паролем, - если результат завершения нулевой – пишем "пароль ОК" и, соответственно, наоборот.
Не подсказывает ли ваша интуиция, что функция X ни что иное, как strcmp? Конечно, это простейший случай, но по любому, столкнувшись с незнакомой подпрограммой, не спешите впадать в отчаяние, приходя в ужас от ее "монстроузности" – просмотрите все вхождения, обращая внимания кто вызывает ее, когда и сколько раз.
Статистический анализ на очень многое проливает свет (функции, как и буквы алфавита, встречаются каждая со своей частотой), а контекстная зависимость дает пищу для размышлений. Так, функция чтения из файла не может предшествовать функции открытия!
Другие зацепки: аргументы и константы. Ну, с аргументами все более или менее ясно. Если функция получает строку, то это очевидно функция из библиотеки работы со строками, а если вещественное значение – возможно, функция математической библиотеки. Количество и тип аргументов (если их учитывать) весьма сужают круг возможных кандидатов. С константами же еще проще, - очень многие функции принимают в качестве аргумента флаг, принимающий одно из нескольких значений. За исключением битовых флагов, которые все похожи друг на друга как один, довольно часто встречаются уникальные значения, пускай не однозначно идентифицирующие функцию, но все равно сужающие круг "подозреваемых". Да и сами функции могут содержать характерные константы, скажем, встретив стандартный полином для подсчета CRC, можно быть уверенным, что "подследственная" вычисляет контрольную сумму…
Мне могут возразить: мол, все это частности. Возможно, но, опознав часть функций, назначения остальных можно вычислить "от противного" и уж по крайней мере понять: что это за библиотека такая и где ее искать.
Напоследок, - идентификацию алгоритмов (т.е. назначения функции) очень сильно облегчает значение этих самих алгоритмов. В частности, код, осуществляющий LZ-сжатие (распаковку), настолько характерен, что узнается с беглого взгляда – достаточно знать этот механизм упаковки. Напротив, если не иметь о нем никакого представления – ох, и нелегко же будет анализировать программу! Зачем открывать изобретать колесо, когда можно взять уже готовое? Хоть и бытует мнение, что хакер – в первую очередь хакер, а уж потом программист (да и зачем ему уметь программировать?), в жизни все наоборот, - программист, не умеющий программировать, проживет – вокруг уйма библиотек, воткни – и заработает! Хакеру же знание информатики необходимо, - без этого далеко не уплывешь (разумеется, отломать серийный номер можно и без высшей математики).
Понятное дело, библиотеки как раз на то и создавались, чтобы избавить разработчиков от необходимости вникать в те предметные области, без которых им и так хорошо. Увы, у исследователей программ нет простых путей – приходится думать и руками, и головой, и даже… пятой точкой опоры вкупе со спинным мозгом, - только так и дизассемблируются серьезные программы. Бывает, готовое решение приходит в поезде или во сне…
Анализ библиотечных функций – это сложнейший аспект дизассемблирования и просто замечательно, когда есть возможность идентифицировать их имена по сигнатурам.
Идентификация циклов
"связь между элементами системы носит трансуровневый характер и проявляет себя в виде повторяющихся единиц разных уровней (мотивов)"
тезис классического постструктурализма в его отечественном изводе
Циклы
– единственная (за исключением неприличного "GOTO") конструкция языков высокого уровня, имеющая ссылку "назад", т.е. в область более младших адресов. Все остальные виды ветвлений – будь то IF – THEN – ELSE или оператор множественного выбора switch всегда направлены "вниз" – в область старших адресов. Вследствие этого, логическое дерево, изображающее цикл, настолько характерно, что легко опознается с первого взгляда.
Существуют три основных типа цикла: циклы с условием вначале (см. рис. 36 слева), циклы с условием в конце (см. рис. 36 в центре) и циклы с условием в середине (см. рис. 36 справа). Комбинированные циклы имеют несколько условий в разных местах, например, в начале и в конце одновременно.
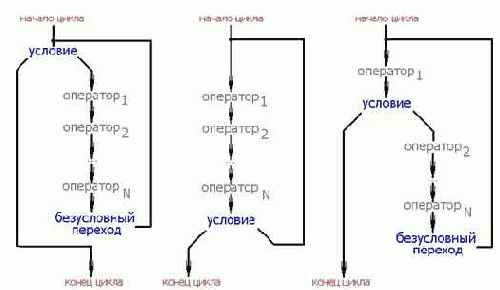
Рисунок 36 0х024 Логическое дерево цикла с условием вначале (слева) и условием в конец (справа).
В свою очередь условия бывают двух типов: условия завершения цикла и условия продолжения цикла. В первом случае: если условие завершения истинно происходит переход в конец цикла, иначе – его продолжение. Во втором: если условие продолжения цикла ложно происходит переход в конец цикла, в противном случае – его продолжения. Легко показать, что условия продолжения цикла представляют собой инвертированные условия завершения. Таким образом, со стороны транслятора вполне достаточно поддержки условий одного типа. И действительно, операторы циклов while,do и for
языка Си работают исключительно с условиями продолжения цикла. Оператор while
языка Pascal так же работает с условием продолжения цикла, и исключение составляет один лишь repeat-until
ожидающий условие завершения цикла.
::Циклы с условиями в начале (так же называемые циклами с преусловием). В языках Си и Pascal поддержка циклов с преусловием обеспечивается оператором "while (условие)", где "условие" – условие продолжения цикла.
Т.е. цикл "while (a < 10) a++;"
выполняется до тех пор, пока условие (a > 10) остается истинным. Однако транслятор при желании может инвертировать условие продолжение цикла на условие завершения цикла. На платформе Intel 80x86 такой трюк экономит от одной до двух машинных команд. Смотрите: на листинге 180 слева приведен цикл с условием завершения, а справа – с условием продолжения. Как видно, цикл с условием завершения на одну команду короче! Поэтому, практически все компиляторы (даже не оптимизирующие) всегда генерируют левый вариант. (А некоторые, особо одаренные, даже умеют превращать циклы с предусловием в еще более эффективные циклы с пост-условием – см. "Циклы с условием в конце").
while: while:
CMP A, 10 CMP A, 10
JAE end JB continue
INC A JMP end
JMP while continue:
end: INC A
JMP while
end:
Листинг 180 Слева показан цикл с условием завершения цикла, а справа – тот же цикл, но с условием продолжения цикла. Как видно, цикл с условием завершения на одну команду короче.
Цикл с условием завершения не может быть непосредственно отображен на оператор while. Кстати, об этом часто забывают начинающие, допуская ошибку "что вижу, то пишу": "while (a >= 10) a++". С таким условием данный цикл вообще не выполниться ни разу! Но как выполнить инверсию условия и при этом гарантированно не ошибиться? Казалось бы, что может быть проще, - а вот попросите знакомого хакера назвать операцию, обратную "больше". Очень может быть (даже наверняка!) ответом будет… "меньше". А вот и нет, - правильный ответ "меньше или равно". Полный перечень обратных операций отношений можно найти в таблице 25, приведенной ниже
|
Логическая операция |
Обратная логическая операция |
|
== |
!= |
|
!= |
== |
|
> |
<= |
|
< |
>= |
|
<= |
> |
|
>= |
< |
Таблица 25 Обратные операции отношения
::Циклы с условием в конце (так же называемые циклами с пост-условием). В языке Си поддержка циклов с пост-условием обеспечивается парой операторов do – while, а в языке Pascal – repeat\until. Циклы с пост-условием без каких либо проблем непосредственно отображаются с языка высокого уровня на машинный код и, соответственно, наоборот. Т.е. в отличие от циклов с предусловием, инверсии условия не происходит.
Например: "do a++; while (a<10)" в общем случае компилируется в следующий код (обратите внимание: в переходе использовалась та же самая операция отношения, что и в исходном цикле, - красота и никаких ошибок при декомпиляции):
repeat: <---------!
INC A !
CMP A, 10 !
JB repeat---!
end:
Листинг 181
Вернувшись страницей назад, сравним код цикла с пост-условием с кодом цикла с предусловием. Не правда ли, цикл с условием в конце компактнее и быстрее? Некоторые компиляторы (например, Microsoft Visual C++) умеют транслировать циклы с предусловием в циклы с пост-условием. На первый взгляд – это вопиющая самодеятельность компилятора, - если программист хочет проверять условие в начале, то какое право имеет транслятор ставить его в конце?! На самом же деле, разница между "до" или "после" не столь велика и значительна. Если компилятор уверен, что цикл выполняется хотя бы один раз, то он вправе выполнять проверку когда угодно. Разумеется, при этом необходимо несколько скорректировать условие проверки: "while (a<b)" не эквивалентно "do … while (a<b)", т.к. в первом случае при (a == b) уже происходит выход из цикла, а во втором цикл выполняется еще одну итерацию. Однако этой беде легко помочь: увеличим а на единицу ("do … while ((a+1)<b)") или вычтем эту единицу из b ("do … while (a<(b-1))") и… теперь все будет работать!
Спрашивается: и на кой все эти извращения, значительно раздувающие код? Дело в том, что блок статического предсказания направления ветвлений Pentium-процессоров оптимизирован именно под переходы, направленные назад, т.е.
в область младших адресов. Поэтому, циклы с постусловием должны выполняться несколько быстрее аналогичных им циклов с предусловием.
::Циклы со счетчиком.
Циклы со счетчиком (for) не являются самостоятельным типом циклов, а представляют собой всего лишь синтаксическую разновидность циклов с предусловием. В самом деле, "for (a = 0; a < 10; a++)" в первом приближении это то же самое, что и: "a = 0; while (a < 10) {…;a++;}". Однако, результаты компиляции двух этих конструкций не обязательно должны быть идентичны друг другу!
Оптимизирующие компиляторы (да и значительная часть не оптимизирующих) поступают хитрее, передавая после инициализации переменной-счетчика управление на команду проверки условия выхода из цикла. Образовавшаяся конструкция, во-первых, характерна и при анализе программы сразу бросается в глаза, а, во-вторых, не может быть непосредственно отображена на циклы while
языка высокого уровня. Смотрите:
MOV A, xxx ; Инициализация переменной "счетчика"
JMP conditional ; Переход к проверке условия продолжения цикла
repeat: ; Начало цикла
… ; // ТЕЛО
… ; // ЦИКЛА
ADD A, xxx [SUB A, xxx]; Модификация счетчика
conditional: ; Проверка условия продолжения цикла
CMP A, xxx ; ^
Jxx repeat ; Переход в начало цикла, если условие истинно
Листинг 182
Непосредственный прыжок вниз может быть результат компиляции и цикла for, и оператора GOTO, но GOTO сейчас не в моде и используется крайне редко, а без него оператор условного перехода "IF – THEN" не может прыгнуть непосредственно в середину цикла while! Выходит, изо всех "кандидатов" остается только цикл for.
Некоторые, особо продвинутые компиляторы (Microsoft Visual C++, Borland C++, но не WATCOM C), поступают хитрее: анализируя код они еще на стадии компиляции пытаются определить: выполняется ли данный цикл хотя бы один раз и, если видят, что он действительно выполняется, превращают for в типичный цикл с постусловием:
MOV A, xxx ; Инициализация переменной "счетчика"
repeat: ; Начало цикла
… ; // ТЕЛО
… ; // ЦИКЛА
ADD A, xxx [SUB A, xxx]; Модификация счетчика
CMP A, xxx ; Проверка условия продолжения цикла
Jxx repeat ; Переход в начало цикла, если условие истинно
Листинг 183
Наконец, самые крутые компиляторы (из которых автор на вскидку может назвать один лишь Microsoft Visual C++ 6.0) могут даже заменять циклы с приращением на циклы с убыванием при условии, что параметр цикла не используется операторами цикла, а лишь прокручивает цикл определенное число раз. Зачем это компилятору? Оказывается, циклы с убыванием гораздо короче – однобайтовая инструкция DEC
не только уменьшает операнд, но и выставляет Zero-флаг при достижении нуля. В результате, в команде CMP A, xxx
отпадает всякая необходимость.
MOV A, xxx ; Инициализация переменной "счетчика"
repeat: ; Начало цикла
… ; // ТЕЛО
… ; // ЦИКЛА
DEC A ; Декремент счетчика
JNZ repeat ; Повтор, пока A != 0
Листинг 184
Таким образом, в зависимости от настроек и характера компилятора, циклы for могут транслироваться и в циклы с предусловием, и в циклы с постусловием, начинающими свое выполнение с проверки условия продолжения цикла. Причем, условие продолжения может инвертироваться в условие завершения, а возрастающий цикл может "волшебным" образом превращаться в убывающий.
Такая неоднозначность затрудняет идентификацию циклов for, – надежно отождествляются лишь циклы, начинающиеся с проверки постусловия (т.к. они не могут быть отображены на do без использования GOTO). Во всех остальных случаях никаких строгих рекомендаций по распознаванию for
дать невозможно.
Скажем так: если логика исследуемого цикла синтаксически удобнее выражается через оператор for, то и выражайте ее через for! В противном случае используйте while или do
(repeat\until) для циклов с пред- и пост- условием соответственно.
И в заключение пара слов о "кастрированных" циклах – язык Си позволяет опустить инициализацию переменной цикла, условие выхода из цикла, оператор приращения переменной или все это вместе. При этом for
вырождается во while, и становится практически неотличимым от него.
::Циклы с условием в середине.
Популярные языки высокого уровня непосредственно не поддерживают циклы с условием в середине, хотя необходимость в них возникает достаточно часто. Поэтому, программисты их реализуют на основе уже имеющихся циклов while (while\do) и оператора выхода из цикла break. Например:
while(1) repeat:
{ …
… CMP xxx
if (условие) break; Jxx end
… …
} JMP repeat
end:
Листинг 185
Компилятор (если он не совсем Осел – Иi в смысле) разворачивает бесконечный цикл в безусловный переход JMP, направленный, естественно назад (ослы генерируют код like – "MOV EAX, 1\CMP EAX,1\JZ repeat"). Безусловный переход, направленный назад, весьма характерен – за исключением бесконечного цикла его может порождать один лишь оператор GOTO, но GOTO уже давно не в моде. А раз у нас есть бесконечный цикл, то условие его завершения может находиться лишь в середине этого цикла (сложные случаи многопоточных защит, модифицирующих из соседнего потока безусловный переход в NOP, мы пока не рассматриваем). Остается прочесать тело цикла и найти это самое условие.
Сделать это будет нетрудно – оператор break транслируется в переход на первую команду, следующую на JMP repeat, а сам break
получает управление от ветки IF (условие) – THEN – [ELSE]. Условие ее срабатывания и будет искомым условием завершения цикла. Вот, собственно, и все.
::Циклы с множественными условиями выхода. Оператор break позволяет организовать выход из цикла в любом удобном для программиста месте, поэтому, любой цикл может иметь множество условий выхода беспорядочно разбросанных по его телу.
Это ощутимо усложняет анализ дизассемблируемой программы, т.к. возникает риск "прозевать" одно из условий завершения цикла, что приведет к неправильному пониманию логики программы.
Идентифицировать же условия выхода из цикла очень просто – они всегда направлены "вниз" т.е. в область старших адресов и указывают на команду, непосредственно следующую за инструкций условного (безусловного) перехода, направленного "вверх" – в область младших адресов. (см. так же "Циклы с условием в середине").
::Циклы с несколькими счетчиками.
Оператор "запятая" языка Си позволяет осуществлять множественную инициализацию и модификацию счетчиков цикла for. Например: "for (a=0, b=10; a != b; a++, b--)". А как насчет нескольких условий завершения? И "ветхий" и "новый " заветы (первое и второе издание K&R соответственно), и стандарт ANSI C, и руководства по С, прилагаемые к компиляторам Microsoft Visual C, Borland C, WATCOM C на этот счет хранят "партизанское" гробовое молчание.
Если попробовать скомпилировать следующий код "for (a=0, b=10; a >0, b <10 ; a++, b--)" он будет благополучно "проглочен" практически всеми компиляторами без малейших ругательств с их стороны, но ни один их них не откомпилирует данный пример правильно. Логическое условие (a1,a2,a3,…an) лишено смысла и компиляторы без малейших колебаний и зазрений совести отбросяст все, кроме самого правого выражения an. Оно-то и будет единолично пределять условие продолжение цикла. Один лишь WATCOM вяло ворчит по этому поводу: "Warning! W111: Meaningless use of an expression: the line contains an expression that does nothing useful. In the example "i = (1,5);", the expression "1," is meaningless. This message is also generated for a comparison that is useless"
Если условие продолжения цикла зависит от нескольких переменных, то их сравнения следует объединить в одно выражение посредством логических операций OR, AND
и др. Например: "for (a=0, b=10; (a >0 && b <10) ; a++, b--)" – цикл прерывается сразу же, как только одно из двух условий станет ложно; "for (a=0, b=10; (a >0 || b <10); a++, b--)" – цикл продолжается до тех пор, пока истинно хотя бы одно условие из двух.
В остальном же циклы с несколькими счетчиками транслируются аналогично циклам с одним счетчиком, за исключением того, что инициализируется и модифицируется не одна, а сразу несколько переменных.
::Идентификация continue. Оператор continue приводит к непосредственной передаче управления на код проверки условия продолжения (завершения) цикла. В общем случае он транслируется в безусловный jump, в циклах с предусловием направленный вверх, а в циклах в постусловием – вниз. Код, следующий за continue, уже не получает управления, поэтому continue
практически всегда используется в условных конструкциях.
Например: "while (a++ < 10) if (a == 2) continue;…" компилируется приблизительно так:
repeat: ; Начало цикла while
INC A ; a++
CMP A, 10 ; Проверка условия завершения цикла
JAE end ; Конец, если a >= 10
CMP A,2 ; if (a == 2) …
JNZ woo ; Переход к варианту "иначе", если a
!= 2
JMP repeat ; ç continue
woo: ; // ТЕЛО
… ; // ЦИКЛА
JMP repeat ; Переход в начало цикла
Листинг 186
::Сложные условия.
До сих пор, говоря об условиях завершения и продолжения цикла, мы рассматривали лишь элементарные условия отношения, в то время как практически все языки высокого уровня допускают использование составных условий. Однако составные условия можно схематично изобразить в виде абстрактного "черного ящика" с входом/выходом и логическим двоичными деревом внутри. Построение и реконструкция логических деревьев подробно рассматриваются в главе "Идентификация IF – THEN – ELSE" здесь же нас интересует не сами условия, а организация циклов.
::Вложенные циклы.
Циклы – понятное дело – могут быть и вложенными. Казалось бы, какие проблемы? Начало каждого цикла надежно определяется по перекрестной ссылке, направленной вниз. Конец цикла – условный или безусловный переход на его начало. У каждого цикла только одно начло и только один конец (хотя условий выхода может быть сколько угодно, но это – другое дело). Причем, циклы не могут пересекаться – если между началом и концом одного цикла встречается начало другого цикла, то этот цикл – вложенный.
Но не все так просто: тут есть два подводных камня. Первый: оператор continue в циклах с предусловием, второй – сложные условия продолжения цикла с постусловием. Рассмотрим их подробнее.
Поскольку, continue в циклах с предусловием, транслируется в безусловный переход, направленный "вверх", он становится практически неотличим от конца цикла. Смотрите:
while(условие1)
{
…
if (условие2) continue;
…
}
транслируется в:
NOT
условие1 выхода из цикла–––––––––! <-! <-----!
… ! ! !
если НЕ условие2 GOTO continue ---! ! ! !
безусловный переход в начало ------)--)---! !
continue: <-----! ! !
… ! !
безусловный переход в начало ---------)------------!
конец всего <------------------------!
Два конца и два начала вполне напоминают два цикла, из которых один вложен в другой. Правда, начала обоих циклов совмещены, но ведь может же такое быть, если в цикл с пост условием вложен цикл с предусловием? На первый взгляд да, но если подумать, то… ай-ай-ай! А ведь условие1
выхода из цикла прыгает аж за второй конец! Если это предусловие вложенного цикла, то оно прыгало бы за первый конец. А если условие1 – это предусловие материнского цикла, то конец вложенного цикла не смог бы передать на него управление. Выходит, это не два цикла, а один. А первый "конец" – результат трансляции оператора continue.
С разбором сложных условий продолжения цикла с постусловием дела обстоят еще лучше. Рассмотрим такой пример:
do
{
…
} while(условие1 || условие2);
Результат его трансляции в общем случае будет выглядеть так:
… <---! <-!
условие продолжения1 ---! !
условие прололжения2 -------!
Ну, чем не:
do
{
do
{
…
}while(условие1)
}while(условие2)
Строго говоря, предложенный вариант является логически верным, но синтаксически некрасивым. Материнский цикл крутит в своем теле один лишь вложенный цикл и не содержит никаких других операторов. Так зачем он тогда, спрашивается, нужен? Объединить его с вложенным циклом в один!
Дизассемблерные листинги примеров. Давайте для закрепления сказанного рассмотрим несколько живых примеров.
Начнем с самого простого – с циклов while\do:
#include <stdio.h>
main()
{
int a=0;
while(a++<10) printf("Оператор
цикла while\n");
do {
printf("Оператор
цикла do\n");
} while(--a >0);
}
Листинг 187 Демонстрация идентификации циклов while\do
Результат компиляции этого примера компилятором Microsoft Visual C++ 6.0 с настройками по умолчанию должен выглядеть так:
main proc near ; CODE XREF: start+AFp
var_a = dword ptr -4
push ebp
mov ebp, esp
; Открываем кадр стека
push ecx
; Резервируем память для одной локальной переменной
mov [ebp+var_a], 0
; Заносим в переменную var_a
значение 0x0
loc_40100B: ; CODE XREF: main_401000+29j
; ^^^^^^^^^^^^^^
; Перекрестная ссылка, направленная вниз, говорит о том, что это начло цикла
; Естественно: раз перекрестная ссылка направлена вниз, то переход,
; ссылающийся на этот адрес, будет направлен вверх!
mov eax, [ebp+var_a]
; Загружаем в EAX значение переменной var_a
mov ecx, [ebp+var_a]
; Загружаем в EСX
значение переменной var_a
; (недальновидность компилятора – можно было бы поступить и короче MOV ECX,EAX)
add ecx, 1
; Увеличиваем ECX на единицу
mov [ebp+var_a], ecx
; Обновляем var_a
cmp eax, 0Ah
; Сравниваем старое ( до обновления) значение переменной var_a с числом 0xA
jge short loc_40102B
; Если var_a
>= 0xA – прыжок "вперед", непосредственно за инструкцию
; безусловного перехода, направленного "назад"
; Раз "назад", значит, – это цикл, а, поскольку, условие выхода из цикла
; проверяется в его начале, то это цикл с предусловием
; Для его отображения на цикл while
необходимо инвертировать условие выхода
; из цикла на условие продолжения цикла (Т.е. заменить >= на <)
; Сделав это, мы получаем:
; while (var_a++ < 0xA)…
;
// Начало
тела цикла
push offset aOperatorCiklaW ; "Оператор
цикла while\n"
call _printf
add esp, 4
; printf("Оператор цикла while\n")
jmp short loc_40100B
; Безусловный переход, направленный назад, на метку loc_40100B
; Между loc_40100B и jmp short loc_40100B есть только одно условие
; выхода из цикла – jge short loc_40102B, значит, исходный цикл
; выглядел так:
; while (var_a++ < 0xA) printf("Оператор цикла while\n")
loc_40102B: ; CODE XREF: main_401000+1Aj
; main_401000+45j
; ^^^^^^^^^^^^^^^^
; // Это начало цикла с пост-условием
; // Однако на данном этапе мы этого еще не знаем, хотя и можем догадываться
; // благодаря наличию перекрестной ссылки, направленной вниз
; Ага, никакого условия в начале цикла не присутствует, значит, это цикл
; с условием в конце или середине
push offset aOperatorCiklaD ; "Оператор
цикла do\n"
call _printf
add esp, 4
; printf("Оператор цикла do\n")
; // Тело
цикла
mov edx, [ebp+var_a]
; Загружаем в EDX значение переменной var_a
sub edx, 1
; Уменьшаем EDX на единицу
mov [ebp+var_a], edx
; Обновляем переменную var_a
cmp [ebp+var_a], 0
; Сравниваем переменную var_a
с нулем
jg short loc_40102B
; Если var_a
> 0, то переход в начало цикла
; Поскольку, условие расположено в конце тела цикла, этот цикл – do:
; do printf("Оператор цикла
do\n"); while (--a > 0)
;
; // Для повышения читабельности дизассемблерного текста рекомендуется
; // заменить префиксы loc_ в начале цикла на while и do (repeat) в циклах
; // с пред- и пост- условием соответственно
mov esp, ebp
pop ebp
; Закрываем кадр стека
retn
main endp
Листинг 188
Совсем другой результат получится если включить оптимизацию. Откомпилируем тот же самый пример с ключом "/Ox" (максимальная оптимизация) и посмотрим на результат, выданный компилятором:
main proc near ; CODE XREF: start+AFp
push esi
push edi
; Сохраняем регистры в стеке
mov esi, 1
; Присваиваем ESI значение 0х1
; Внимание – взгляните на исходный код – ни одна из переменных не имела
; такого значения!
mov edi, 0Ah
; Присваиваем EDI значение 0xA. Ага, это константа для проверки условия
; выхода из цикла
loc_40100C: ; CODE XREF: main+1Dj
; ^^^^^^^^^^^^^^^^^^^^
; Судя по перекрестной ссылке, направленной вниз, этот – цикл!
push offset aOperatorCiklaW ; "Оператор
цикла while\n"
call _printf
add esp, 4
; printf("Оператор цикла
while\n")
; …тело цикла while? (растерянно так)
; Постой, постой! А где же предусловие?!
dec edi
; Уменьшаем EDI на один
inc esi
; Увеличиваем ESI на один
test edi, edi
; Проверяем EDI на равенство нулю
ja short loc_40100C
; Переход в начало цикла, пока EDI
!= 0
; Так… (задумчиво) Компилятор в порыве оптимизации превратил неэффективный
; цикл с предусловием в более компактный и быстрый цикл с пост-условием
; Имел ли он на это право? А почему нет?! Проанализировав код, компилятор понял
; что данный цикл выполняется, по крайней мере, один раз, следовательно,
; скорректировав условие продолжения, его проверку можно вынести в конец цикла
; Поэтому-то начальное значение переменной цикла равно единице, а не нулю!
; Т.е. while ((int a = 0) < 10) компилятор
заменил на do … while (((int a = 0)+1) < 10) ==
; do … while ((int a=1) < 10)
;
; Причем, что интересно, он не сравнивал переменную цикла с константой,
; а поместил константу в регистр и уменьшал его до тех пор, пока тот не стал
; равен нулю! Зачем? А затем, что так короче, да и работает быстрее
; Что ж, это все хорошо, но как нам декомпилировать этот цикл?
; Непосредственное отображение на язык Си дает следующую конструцию:
; var_ ESI = 1; var _EDI = 0xA;
; do {
;;printf("Оператор цикла
while\n"); var_EDI--; var_ESI++;
; } while(var_EDI > 0)
;
; Правда, коряво и запутано? Что-ж, тогда попытаемся избавится от одной
; из двух переменных. Это действительно возможно, т.к. они модифицируются
; синхронно, и var_EDI = 0xB – var_ESI
; ОК, выполняем подстановку:
; var_ ESI = 1; var _EDI = 0xB – var_ESI ; (== 0xA;)
; do {
;;printf("Оператор цикла
while\n"); var_EDI--; var_ESI++;
; ^^^^^^^^^^
; Это мы вообще сокращаем, т.к. var_EDI уже выражена через var_ESI
; } while((0xB – var_ESI) > 0); (== var_ESI > 0xB)
;
; Что, ж уже получается нечто осмысленное:
;
; var_ ESI = 1; var _EDI == 0xA;
; do {
;; printf("Оператор цикла
while\n"); var_ESI++;
; } while(var_ESI > 0xB)
; На этом можно и остановится, а можно и пойти дальше, преобразовав цикл
; с пост-условием в более наглядный цикл с предусловием
;
; var_ ESI = 1; var _EDI == 0xA; ß var_EDI не используется, можно сократить
; while (var_ESI <= 0xA) {
;; printf("Оператор цикла
while\n"); var_ESI++;
; }
; Но и это не предел выразительности: во-первых var_ESI <= 0xA эквивалентно
; var_EDI < 0xB, а во-вторых, поскольку, переменная var_ESI используется лишь
; как счетчик, ее начальное значение можно безбоязненно привести к нулевому
; значению, а операцию инкремента внести в сам цикл:
; var_ ESI = 0;
; while (var_ESI++ < 0xA) ß
вычитаем единицу из левой и правой половины
; printf("Оператор цикла while\n");
;
; Ну, разве не красота?! Сравните этот вариант с первоначальным –
; насколько он стал яснее и понятнее
loc_40101F: ; CODE XREF: main+2Fj
; ^^^^^^^^^^^^^^^^^^^^
; Перекрестная ссылка, направленная вниз, говорит о том, что это – начало цилка
; // Предусловия нет – значит, это цикл do
push offset aOperatorCiklaD ; "Оператор
цикла do\n"
call _printf
add esp, 4
; printf("Оператор цикла do\n");
dec esi
; Уменьшаем var_ESI
test esi, esi
; Проверка ESI на равенство нулю
jg short loc_40101F
; Продолжать цикл, пока var_ESI
> 0
;
; ОК. Этот цикл легко и непринужденно отображается на язык Си:
; do printf("Оператор цикла
do\n"); while (--var_ESI > 0 )
pop edi
pop esi
; Восстанавливаем сохраненные регистры
retn
main endp
Листинг 189
Несколько иначе оптимизирует циклы компилятор Borland C++ 5.x. Смотрите:
_main proc near ; DATA XREF: DATA:00407044o
push ebp
mov ebp, esp
; Открываем кадр стека
push ebx
; Сохраняем EBP в стеке
xor ebx, ebx
; Присваиваем регистровой переменной EBX
значение ноль
; Как легко догадаться – EBX и есть "a"
jmp short loc_40108F
; Безусловный прыжок вниз. Очень похоже на цикл for…
loc_401084: ; CODE XREF: _main+19j
; ^^^^^^^^^^^^^^^^^^^^^
; Перекрестная ссылка, направленная вниз – значит, это начало какого-то цикла
push offset aOperatorCiklaW ; "Оператор
цикла while\n"
call _printf
pop ecx
; printf("Оператор цикла
while\n")
loc_40108F: ; CODE XREF: _main+6j
; А вот сюда был направлен самый первый jump
; Посмотрим: что же это такое?
mov eax, ebx
; Копирование EBX в EAX
inc ebx
; Увеличение EBX
cmp eax, 0Ah
; Сравнение EAX со значением 0xA
jl short loc_401084
; Переход в начало цикла, если EAX
< 0xA
; Вот так-то Borland оптимизировал код! Он расположил условие в конце цикла,
; но, чтобы не транслировать цикл с предусловием в цикл с постусловием,
; просто начал выполнение цикла с этого самого условия!
;
; Отображение этого цикла на язык Си дает:
; for (int a=0; a < 10; a++) printf("Оператор цикла
while\n")
;
; и, хотя подлинный цикл выглядел совсем не так, наш вариант нечем не хуже!
; (а может даже и лучше – нагляднее)
loc_401097: ; CODE XREF: _main+29j
; ^^^^^^^^^^^^^^^^^^^^^
; Начало цикла!
; Условия нет – значит, это цикл с постусловием
push offset aOperatorCiklaD ; "Оператор
цикла do\n"
call _printf
pop ecx
; printf("Оператор цикла do\n")
dec ebx
; --var_EBX
test ebx, ebx
jg short loc_401097
; Продолжать цикл, пока var_EBX
> 0
; do printf("Оператор цикла
do\n"); while (--var_EBX > 0)
xor eax, eax
; return 0
pop ebx
pop ebp
; Восстанавливаем сохраненные регистры
retn
_main endp
Листинг 190
Остальные компиляторы генерируют аналогичный или даже еще более примитивный и очевидный код, поэтому не будем подробно их разбирать, а лишь кратно опишем используемые ими схемы трансляции.
Компилятор Free Pascal 1.x ведет себя аналогично компилятору Borland C++ 5.0, всегда помещая условие в конец цикла и начиная с него выполнение while-циклов.
Компилятор WATCOM C не умеет преобразовывать циклы с предусловием в циклы с постусловием, вследствие чего располагает условие выхода из цикла в начале while-циклов, а в их конец вставляет безусловный jump. (Классика!)
Компилятор GCC вообще не оптимизирует циклы с предусловием, генерируя самый неоптимальный код. Смотрите:
mov [ebp+var_a], 0
; Присвоение переменной a значения 0
mov esi, esi
; Э… на редкость умный код! При его виде трудно не упасть со стула!
loc_401250: ; CODE XREF: sub_40123C+34j
; ^^^^^^^^^^^^^^^^^^^^^^^^^^^^
; Начало
цикла
mov eax, [ebp+var_a]
; Загрузка в EAX значения переменной var_a
inc [ebp+var_a]
; Увеличение var_a
на единицу
cmp eax, 9
; Сравнение EAX со значением 0x9
jle short loc_401260
; Переход, если EAX <= 0x9 (EAX < 0xA)
jmp short loc_401272
; Безусловный переход в конец цикла
; Стало быть, предыдущий условный переход – переход на его продолжение
; Какой неоптимальный код! Зато нет инверсии условия продолжения цикла,
; что упрощает дизассемблирование
align
4
; Выравнивание перехода по адресам, кратным четырем, ускорят код, но заметно
; увеличивает его размер (особенно, если переходов очень много)
loc_401260: ; CODE XREF: sub_40123C+1Dj
add esp, 0FFFFFFF4h
; Вычитание из ESP значения 12 (0xC)
push offset aOperatorCiklaW ; "Оператор
цикла while\n"
call printf
add esp, 10h
; Восстанавливаем стек (0xC + 0x4 ) == 0x10
jmp short loc_401250
; Переход в начало цикла
loc_401272:
; Конец цикла
Листинг 191
Разобравшись с while\do, перейдем к циклам for. Рассмотрим следующий пример:
#include <stdio.h>
main()
{
int a;
for (a=0;a<10;a++) printf("Оператор
цикла for\n");
}
Листинг 192 Демонстрация идентификации циклов for
Результат компиляции Microsoft Visual C++ 6.0 с настройками по умолчанию будет выглядеть так:
main proc near ; CODE XREF: start+AFp
var_a = dword ptr -4
push ebp
mov ebp, esp
; Открываем кадр стека
push ecx
; Резервируем память для локальной переменной
mov [ebp+var_a], 0
; Присваиваем локальной переменной var_a значение 0
jmp short loc_401016
; Непосредственный переход на код проверки условия продолжения цикла -
; характерный признак for
loc_40100D: ; CODE XREF: main+29j
; ^^^^^^^^^^^^^^^^^^^^
; Перекрестная ссылка, направленная вниз говорит о том, что это начало цикла
mov eax, [ebp+var_a]
; Загрузка в EAX значения переменной var_a
add eax, 1
; Увеличение EAX на единицу
mov [ebp+var_a], eax
; Обновление EAX
; Следовательно, исходный код выглядел так:
; ++a
loc_401016: ; CODE XREF: main+Bj
cmp [ebp+var_a], 0Ah
; Сравниваем var_a
со значением 0xA
jge short loc_40102B
; Выход из цикла, если var_a
>= 0xA
push offset aOperatorCiklaF ; "Оператор
цикла for\n"
call _printf
add esp, 4
; printf("Оператор цикла for\n")
jmp short loc_40100D
; Безусловный переход в начало цикла
;
; Итак, что мы имеем?
; инициализация переменной var_a
; переход на проверку условия выхода из цикла –---–----!
; инкремент переменной var_a ß-------------------! !
; проверка условия относительно var_a ß--------- ! ---!
; прыжок на выход из цикла, если условие истинно–!–---!
; вызов printf ! !
; переход в начало цикла ------------------------! !
; конец цикла ß-------------------------------–-–----!
;
; Проверка на завершения, расположенная в начале цикла, говорит о том, что
; это цикл с предусловием, но непосредственно выразить его через while
; не удается – мешает безусловный переход в середину цикла, минуя код
; инкремента переменной var_a
; Однако этот цикл с легкостью отображается на оператор for, смотрите:
; for (a = 0; a < 0xA; a++) printf("Оператор цикла
for\n")
;
; Действительно, цикл for сначала инициирует переменную – счетчик,
; затем проверяет условие продолжение цикла
; (оптимизируемое компилятором в условие завершение), далее выполняет
; оператор цикла, модифицирует счетчик, вновь проверяет условие и т.д.
;
loc_40102B: ; CODE XREF: main+1Aj
mov esp, ebp
pop ebp
; Закрываем кадр стека
retn
main endp
Листинг 193
А теперь задействуем оптимизацию и посмотрим, как видоизмениться наш цикл:
main proc near ; CODE XREF: start+AFp
push esi
mov esi, 0Ah
; Инициализируем переменную – счетчик
; Внимание! В исходном коде начальное значение счетчика равнялось нулю!
loc_401006: ; CODE XREF: main+14j
push offset aOperatorCiklaF ; "Оператор
цикла for\n"
call _printf
add esp, 4
; printf("Оператор цикла for\n")
; Выполняем оператор цикла! Причем безо
всяких проверок!
; Хитрый компилятор проанализировал код и понял, что цикл выполняется
; по крайней мере один раз!
dec esi
; Уменьшаем счетчик, хотя в исходном коде программы мы его увеличивали!
; Ну, правильно – dec \ jnz намного короче INC\ CMP reg, const\ jnz xxx
; Ой и мудрит компилятор! Кто же ему давал право так изменять цикл?!
; А очень просто – он понял, что параметр цикла в самом цикле используется
; только как счетчик, и нет никакой разницы – увеличивается он
; с каждой итерацией или уменьшается!
jnz short loc_401006
; Переход в начало цикла если ESI
> 0
;
; М да, по внешнему виду это типичный
; a = 0xa; do printf("Оператор цикла
for\n"); while (--a)
;
; Если вас устраивает читабельность такой формы записи – оставляйте ее, а нет:
; for (a = 0; a < 10; a++) Оператор цикла
for\n")
;
; Постой, постой! На каком основании автор выполнил такое преобразование?!
; А на том самом – что и компилятор: раз параметр цикла используется только
; как счетчик, законна любая запись, выполняющая цикл ровно десять раз –
; остается выбрать ту, которая удобнее (с эстетической точки зрения)
; Никто же не будет утверждать, что
; for (a = 10; a > 0; a--) более
привычно чем for (a = 0; a < 10; a++)?
pop esi
retn
main endp
Листинг 194
А что скажет нам товарищ Borland C++ 5.0? Компилируем и смотрим:
_main proc near ; DATA XREF: DATA:00407044o
push ebp
mov ebp, esp
; Открываем кадр стека
push ebx
; Сохраняем EBX в стеке
xor ebx, ebx
; Присваиваем регистровой переменной EBX
значение 0
loc_401082: ; CODE XREF: _main+15j
; ^^^^^^^^^^^^^^^^^^^^^^
; Начало
цикла
push offset aOperatorCiklaF ; format
call _printf
pop ecx
; Начинаем цикл с выполнения его тела
; OK, Borland
понял, что цикл выполняется по крайней мере раз
inc ebx
; Увеличиваем параметр цикла
cmp ebx, 0Ah
; Сравниваем EBX со значением 0xA
jl short loc_401082
; Переход в начало цикла, пока EBX
< 0xA
xor eax, eax
pop ebx
pop ebp
retn
_main endp
Листинг 195
Видно, что Borland C++ 5.0 не дотягивает до Microsoft Visual C++ 6.0 – понять, что цикл выполняется один раз он понял, а вот реверс счетчика ума уже не хватило. Аналогичным образом поступает и большинство других компиляторов, в частности WATCOM C.
Теперь настала очередь циклов с условием в середине или циклов, завершаемых вручную оператором break. Рассмотрим следующий пример:
#include <stdio.h>
main()
{
int a=0;
while(1)
{
printf("1й оператор\n");
if (++a>10) break;
printf("2й оператор\n");
}
do
{
printf("1й оператор\n");
if (--a<0) break;
printf("2й оператор\n");
}while(1);
}
Листинг 196 Демонстрация идентификации break
Результат компиляции Microsoft Visual C++ 6.0 с настройками по умолчанию должен выглядеть так:
main proc near ; CODE XREF: start+AFp
var_a = dword ptr -4
push ebp
mov ebp, esp
; Открываем кадр стека
push ecx
; Резервируем место для локальной переменной
mov [ebp+var_a], 0
; Присваиваем переменной var_a
значение 0х0
loc_40100B: ; CODE XREF: main+3Fj
; ^^^^^^^^^^^^^^^^^^^^^
; Перекрестная ссылка, направленная вниз – цикл
mov eax, 1
test eax, eax
jz short loc_401041
; Смотрите! Когда optimize disabled, - компилятор транслирует безусловный
; цикл "слишком буквально", т.к. присваивает EAX
значение 1 (TRUE)
; и затем педантично проверяет ее на равенство нулю
; Если в кои веки TRUE будет равно FALSE – произойдет выход из цикла
; Словом, все эти три инструкции – глупый и бесполезный код цикла
; while (1)
push offset a1iOperator ; "1й оператор\n"
call _printf
add esp, 4
; printf("1й оператор\n")
mov ecx, [ebp+var_a]
; Загружаем в ECX значение переменной var_a
add ecx, 1
; Увеличивем ECX на единицу
mov [ebp+var_a], ecx
; Обновляем var_a
cmp [ebp+var_a], 0Ah
; Сравниваем var_a
со значением 0xA
jle short loc_401032
; Переход, если var_a
<= 0xA
; Но куда этот переход? Во-первых, переход направлен вниз, т.е. это уже
; не переход к началу цикла, следовательно и условие – не условие цикла, а
; результат компиляции конструкции IF – THEN
; Второе – переход прыгает на первую команду, следующую за безусловным
; jump loc_401041, передающим управление инструкции, следующей
; за командной jmp short loc_401075 – безусловного перехода, направленного
; вверх – в начало цикла
; Следовательно, jmp short loc_401041 осуществляет выход из цикла, а
; jle short loc_401032 – продолжает его выполнение
jmp short loc_401041
; ОК, - это переход на завершение цикла. А кто у нас завершает цикл?
; Ну, конечно же, break! Следовательно, окончательная декомпиляции выглядит так
; if (++var_a > 0xA) break
; Мы инвертировали "<=" в ">", т.к. JLE
передает управление на код продолжения
; цикла, а ветка THEN в нашем случае – на break
loc_401032: ; CODE XREF: main+2Ej
; ^^^^^^^^^^^^^^^^^^^^^
; Перекрестная ссылка направлена вверх – следовательно, это не начало цикла
push offset a2iOperator ; "2й оператор\n"
call _printf
add esp, 4
; printf("2й оператор\n")
jmp short loc_40100B
; Прыжок в начало цикла. Вот мы и добрались до конца цикла
; Восстанавливаем исходный код:
; while(1)
; {
; printf("1й оператор\n");
; if (++var_a > 0xA) break;
; printf("2й оператор\n");
; }
;
loc_401041: ; CODE XREF: main+12j main+30j ...
; ^^^^^^^^^^
; Перекрестная ссылка, направленная вниз, говорит, что это начало цикла
push offset a1iOperator_0 ; "1й оператор\n"
call _printf
add esp, 4
; printf("1й оператор\n")
mov edx, [ebp+var_a]
sub edx, 1
mov [ebp+var_a], edx
; --var_a
cmp [ebp+var_a], 0
; Сравниваем var_a со значением 0x0
jge short loc_40105F
; Переход вниз, если var_a
>= 0
; Смотрите: оператор break цикла do ничем не отличается от break цикла while!
; Поэтому, не будем разглагольствовать, а сразу его декомпилируем!
; if (var_a < 0) …
jmp short loc_401075
; …break
loc_40105F: ; CODE XREF: main+5Bj
push offset a2iOperator_0 ; "2й оператор\n"
call _printf
add esp, 4
; printf("2й оператор\n")
mov eax, 1
test eax, eax
jnz short loc_401041
; А это – проверка продолжения цикла
loc_401075: ; CODE XREF: main+5Dj
mov esp, ebp
pop ebp
; Закрываем кадр стека
retn
main endp
Листинг 197
Что ж, оператор break в обоих циклах выглядит одинаково и элементарно распознается (правда, не с первого взгляда, но отслеживанием нескольких переходов – да). А вот с бесконечными циклами не оптимизирующий компилятор подкачал, транслировав их в код, проверяющий условие, истинность (не истинность) которого очевидна. А как поведет себя оптимизирующий компилятор?
Давайте откомпилируем тот же самый пример компилятором Microsoft Visual C++ 6.0 с ключом "/Ox" и посмотрим:
main proc near ; CODE XREF: start+AFp
push esi
; Сохраняем ESI в стеке
xor esi, esi
; Присваиваем ESI значение 0
; var_ESI = 0;
loc_401003: ; CODE XREF: main+23j
; ^^^^^^^^^^^^^^^^^^^^^
; Перекрестная ссылка, направленная вперед
; Это – начало цикла
push offset a1iOperator
; "1й оператор\n"
call _printf
add esp, 4
; printf("1й оператор\n")
;
; Ага! Проверки на дорогах нет, значит, это цикл с постусловием
; (или условием в середине)
inc esi
; ++var_ESI
cmp esi, 0Ah
; Сравниваем var_ESI
со значением 0xA
jg short loc_401025
; Выход из цикла, если var_ESI
> 0xA
; Поскольку, данная команда – не последняя в теле цикла,
; это цикл с условием в середине
; if (var_ESI > 0xA) break
push offset a2iOperator ; "2й оператор\n"
call _printf
add esp, 4
; printf("2й оператор\n")
jmp short loc_401003
; Безусловный переход в начало цикла
; Как видно, оптимизирующий компилятор выкинул никому ненужную проверку
; условия, упростив код и облегчив его понимание:
; Итак:
; var_ESI = 0
; for (;;) ß
вырожденный for
представляет собой бесконечный цикл
; {
; printf("1й оператор\n");
; ++var_ESI;
; if (var_ESI > 0xA) break;
; printf("2й оператор\n");
; }
loc_401025: ; CODE XREF: main+14j
; ^^^^^^^^^^^^^^^^^^^^^
; Это не начало цикла!
push offset a1iOperator_0 ; "1й оператор\n"
call _printf
add esp, 4
; printf("1й оператор\n")
; Хм, как же это не начало цикла?! Очень похоже!
dec esi
; --var_ESI
js short loc_401050
; Выход из цикла, если var_ESI
< 0
inc esi
; Увеличиваем var_ESI
на единицу
; М–м-м… (задумчиво)…
loc_401036: ; CODE XREF: main+4Ej
; ^^^^^^^^^^^^^^^^^^^^^^
; А вот это начало цикла!
push offset a2iOperator_0 ; "2й оператор\n"
call _printf
; printf("2й оператор\n")
; Только странно, что начало цикла начинается с его, с позволения сказать,
; середины…
push offset a1iOperator_0 ; "1й оператор\n"
call _printf
add esp, 8
; printf("1й оператор\n")
;
; ???!!! Что за чудеса творятся? Во-первых, вызов первого оператора второго
; цикла уже встречался ранее, во-вторых, не может же следом за серединой цикла
; следовать его начало?!
dec esi
; --var_ESI
jnz short loc_401036
; Продолжение цикла, пока var_ESI
!= 0
loc_401050: ; CODE XREF: main+33j
; Конец цикла
; Да… тут есть над чем подумать!
; Компилятор нормально "перевалил" первую строку цикла
; printf("1й оператор\n")
; а затем "напоролся" на ветвление:
; if
(--a<0) break
; Хитрые парни из Microsoft знают, что для супер - конвейерных процессоров
; (коими и являются чипы Pentium) ветвления все равно, что чертополох для
; Тиггеров. Кстати, Си-компиляторы под процессоры серии CONVEX
вообще
; отказываются компилировать циклы с ветвлениями, истощенно понося
; умственные способности программистов. А вы еще IBM PC
ругаете ;-)
; Вот и приходится компилятору исправлять ляпы программиста, что он делать
; в принципе не обязан, но за что ему большое человеческое спасибо!
; Компилятор как бы "прокручивает" цикл, "слепляя" вызовы функций printf
; и вынося ветвления в конец
; Образно исполняемый код можно представить трассой, а процессор – гонщиком
; Чем длиннее участок дороги без поворотов, тем быстрее его проскочит гонщик!
; Выносить условие из середины цикла в его конец компилятор вполне правомерен,
; ведь переменная, относительно которой выполняется ветвление,
; не модифицируется ни функцией printf, ни какой другой
; Поэтому, не все ли равно где ее проверять? Конечно же не все равно!!!
; К моменту когда условие (--a < 10) становится истинно, успевает выполниться
; первый printf, а вот второй – уже не получает управления
; Вот для этого-то компилятор и поместил код проверки условия следом за
; первым вызовом первой функции printf, а затем изменил порядок вызова
; printf
в теле цикла. Это привело к тому, что на момент выхода из цикла
; по условию первый printf выполняется на один раз больше, чем второй
; (т.к. он встречается дважды)
; Остается разобраться с увеличением var_ESI – что бы это значило?
; Давайте рассуждать от противного: что произойдет, если выкинуть
; команду INC ESI? Поскольку, счетчик цикла при первой итерации цикла
; декрементируется дважды, возникнет недостача и цикл выполниться на раз
; короче. Что бы этого не произошло, var_ESI искусственно увеличивается
; на единицу
; Ой, и не просто во всей этой головоломке разобраться, а представьте:
; насколько сложно реализовать компилятор, умеющий проделывать такие фокусы!
; А еще кто-то ругает автоматическую оптимизацию. Да уж! Конечно, руками-то
; можно и круче оптимизировать(особенно понимания смысл кода), но ведь эдак
; и мозги вывихнуть будет можно! А компилятор, даже будучи стиснут со всех
; сторон кривым кодом программиста, за доли секунды успевает его довольно
; прилично окультурить
pop esi
retn
main endp
Листинг 198
Компиляторы Borland C++ и WATCOM при трансляции бесконечных циклов заменяют код проверки условия продолжения цикла на безусловный переход, но вот, увы, оптимизировать ветвления, вынося их в конец цикла так, как это делает Microsoft Visual C++ 6.0 они не умеют…
Теперь, после break, рассмотрим: как компиляторы транслирует его "астральный антипод", - оператор continue. Возьмем следующий пример:
#include <stdio.h>
main()
{
int a=0;
while (a++<10)
{
if (a == 2) continue;
printf("%x\n",a);
}
do
{
if (a == 2) continue;
printf("%x\n",a);
} while
(--a>0);
}
Листинг 199 Демонстрация идентификации continue
Результат его компиляции компилятором Microsoft Visual C++ 6.0 с настройками по умолчанию будет выглядеть так:
main proc near ; CODE XREF: start+AFp
var_a = dword ptr -4
push ebp
mov ebp, esp
; Открываем кадр стека
push ecx
; Резервируем место для локальной переменной
mov [ebp+var_a], 0
; Присваиваем локальной переменной var_a значение 0
loc_40100B: ; CODE XREF: main+22j main+35j
; ^^^^^^^^^^^^^^^^^^^
; Две перекрестные ссылки, направленные вперед, говорят о том, что это либо
; начало двух циклов (один из которых – вложенный), либо переход в начало
; цикла
оператором
continue
mov eax, [ebp+var_a]
; Загружаем в EAX значение var_a
mov ecx, [ebp+var_a]
; Загружаем в ECX значение var_a
add ecx, 1
; Увеличиваем ECX на единицу
mov [ebp+var_a], ecx
; Обновляем переменную var_a
cmp eax, 0Ah
; Сравниваем значение переменной var_a до увеличения с числом 0xA
jge short loc_401037
; Выход из цикла ( переход на команду, следующую за инструкцией, направленной
; вверх – в начало цикла) если var_a >= 0xA
cmp [ebp+var_a], 2
; Сравниваем var_a
со значением 0x2
jnz short loc_401024
; Если var_a
!= 2, то прыжок на команду, следующую за инструкцией
; безусловного перехода, направленной вверх – в начало цикла
; Очень похоже на условие выхода из цикла, но не будет спешить с выводами!
; Вспомним – в начале цикла нам встретились две перекрестные ссылки
; Безусловный переход "jmp short loc_40100B" как раз образует одну из них
; А кто "отвечает" за другую?
; Чтобы ответить на этот вопрос необходимо проанализировать остальной код цикла
jmp short loc_40100B
; Безусловный переход, направленный в начало цикла – это либо конец цикла,
; либо continue
; Предположим, что это конец цикла. Тогда что же представляет собой
; "jge short loc_401037"? Предусловие выхода из цикла? Не похоже – в таком
; случае они прыгало бы гораздо "ближе" – на метку loc_401024
; А может, "jge short loc_401037" предусловие одного цикла, а
; "jnz short loc_401024" – постусловие другого, вложенного в него?
; Вполне возможно, но маловероятно – в этом случае постусловие представляло бы
; собой условие продолжения, а не завершения цилкла
; Поэтому, с некоторой долей неуверенности, мы можем принять конструкцию
; CMP var_a, 2 \ JNZ loc_401024 \ JMP loc_40100B за if (a==2) continue
loc_401024: ; CODE XREF: main+20j
mov edx, [ebp+var_a]
push edx
push offset asc_406030 ; "%x\n"
call _printf
add esp, 8
; printf("%x\n",var_a)
jmp short loc_40100B
; А вот это – явно конец цикла, т.к. jmp short loc_40100B – самая
; последняя ссылка на начало цикла
; Итак, подытожим, что мы имеем:
; Условие, расположенное в начале цикла, крутит этот цикл до тех пор, пока
; var_a < 0xA, причем инкремент параметра цикла происходит до его сравнения
; Затем следует еще одно условие, возвращающее управление в начало цикла, если
; var_a == 2. Строй замыкает оператор цикла printf
и безусловный переход в его
; начало. Т.е.
;
; Начало цикла: <-----------! <--!
; Инкремент переменной var_a ! !
; условие "далекого" выхода -------! ! !
; условие "ближнего" продолжения --)----! !
; тело цикла ! !
; безусловный переход в начало ----)---------!
; конец цикла <----!
;
; Условие "ближнего" продолжение не может быть концом цикла, т.к. тогда условию
; "далекого" выхода пришлось выйти аж из надлежащего цикла, на что ни break,
; ни другие операторы не способны. Таким образом, условие ближнего продолжения
; может быть только оператором continue
и на языке Си всю эту конструкция
; будет выглядеть так:
; while(a++<10) // <-- инкремент var_a и условие далекого выхода
; {
; if (a == 2) continue; // <-- условие ближнего продолжения
; printf(%x\n",var_a); // <-- тело цикла
; } // <-- безусловный переход на начало цикла
loc_401037: ; CODE XREF: main+1Aj main+5Dj
; ^^^^^^^^^
; Начало цикла
cmp [ebp+var_a], 2
; Сравниваем переменную var_a
со значением 0x2
jnz short loc_40103F
; Если var_a
!= 2, то продолжение цикла
jmp short loc_401050
; Переход к коду проверки условия продолжения цикла
; Это бесспорно "continue" и вся конструкция выглядит так:
; if (a==2) continue
loc_40103F: ; CODE XREF: main+3Bj
mov eax, [ebp+var_a]
push eax
push offset asc_406034 ; "%x\n"
call _printf
add esp, 8
; printf("%x\n", var_a)
loc_401050: ; CODE XREF: main+3Dj
mov ecx, [ebp+var_a]
sub ecx, 1
mov [ebp+var_a], ecx
; --var_a
cmp [ebp+var_a], 0
; Сравнение var_a
с нулем
jg short loc_401037
; Пока var_a
> 0 продолжать цикл. Похоже на постусловие верно? Тогда:
; do
; {
; if (a==2) continue;
; printf("%x\n", var_a);
; } while (--var_a > 0);
;
mov esp, ebp
pop ebp
retn
main endp
Листинг 200
А теперь посмотрим, как повлияла оптимизация ("/Ox") на вид циклов:
main proc near ; CODE XREF: start+AFp
push esi
mov esi, 1
loc_401006: ; CODE XREF: main+1Fj
; ^^^^^^^^^^^^^^^^^^^^
; Начало цикла
cmp esi, 2
jz short loc_401019
; Переход на loc_401019, если ESI == 2
push esi
push offset asc_406030 ; "%x\n"
call _printf
add esp, 8
; printf("%x\n", ESI)
; Прим: эта ветка выполняется только если ESI
!=2
; Следовательно, ее можно изобразить так:
; if (ESI != 2) printf("%x\n", ESI)
loc_401019: ; CODE XREF: main+9j
mov eax, esi
inc esi
; ESI++;
cmp eax, 0Ah
jl short loc_401006
; Продолжение цикла пока (ESI++ < 0xA)
; Итого:
; do
; {
; if (ESI != 2) printf("%x\n", ESI);
; } while (ESI++ < 0xA)
;
; А что, выглядит вполне читабельно, не правда ли? Ни чуть не хуже, чем
; if (ESI == 2) continue
;
loc_401021: ; CODE XREF: main+37j
; ^^^^^^^^
; Начало цикла
cmp esi, 2
jz short loc_401034
; Переход на loc_401034, если ESI == 2
push esi
push offset asc_406034 ; "%x\n"
call _printf
add esp, 8
; printf("%x\n",ESI);
; Прим. эта ветка выполняется лишь когда ESI
!= 2
loc_401034: ; CODE XREF: main+24j
dec esi
; --ESI
test esi, esi
jg short loc_401021
; Условие продолжение цикла – крутить кака ESI
> 0
; Итого:
; do
; {
; if (ESI != 2)
; {
; printf("%x\n", ESI);
; }
; } while (--ESI > 0)
;
pop esi
retn
main endp
Листинг 201
Остальные компиляторы сгенерируют приблизительно такой же код. Общим для всех случаев будет то, что на циклах с предусловием оператор continue
практически неотличим от вложенного цикла, а на циклах с постусловием continue эквивалентен элементарному ветвлению.
Наконец, настала очередь циклов for, вращающих несколько счетчиков одновременно. Рассмотрим следующий пример:
main()
{
int a; int b;
for (a = 1, b = 10; a < 10, b > 1; a++, b --)
printf("%x %x\n", a, b);
}
Листинг 202 Демонстрация идентификации циклов for с несколькими счетчиками
Результат его компиляции компилятором Microsoft Visual C++ 6.0 должен выглядеть так:
main proc near ; CODE XREF: start+AFp
var_b = dword ptr -8
var_a = dword ptr -4
push ebp
mov ebp, esp
; Открываем кадр стека
sub esp, 8
; Резервируем память для двух локальных переменных
mov [ebp+var_a], 1
; Присваиваем переменной var_a
значение 0x1
mov [ebp+var_b], 0Ah
; Присваиваем переменной var_b
значение 0xA
jmp short loc_401028
; Прыжок на код проверки условия выхода из цикла
; Это характерная черта не оптимизированных циклов for
loc_401016: ; CODE XREF: main+43j
; ^^^^^^^^^
; Перекрестная ссылка, направленная вниз, говорит о том, что это – начало цикла
; А выше мы уже выяснили, что тип цикла - for
mov eax, [ebp+var_a]
add eax, 1
mov [ebp+var_a], eax
; var_a++
mov ecx, [ebp+var_b]
sub ecx, 1
mov [ebp+var_b], ecx
; var_b--
loc_401028: ; CODE XREF: main+14j
cmp [ebp+var_b], 1
jle short loc_401045
; Выход из цикла, если var_b
<= 0x1
; Обратите внимание: выполняется проверка лишь одного (второго слева) счетчика!
; Выражение (a1,a2,a3,…an) компилятор считает бессмысленным и берет лишь an
; молчаливо отбрасывая все остальное
; (из известных мне компиляторов на это ругается один WATCOM)
; В данном случае проверяется лишь условие (b
> 1), а (a
< 10) игнорируется!!!
mov edx, [ebp+var_b]
push edx
mov eax, [ebp+var_a]
push eax
push offset aXX ; "%x %x\n"
call _printf
add esp, 0Ch
; printf("%x %x\n", var_a, var_b)
jmp short loc_401016
; Конец цикла
; Итак, данный цикл можно представить как:
; while(1)
; {
; var_a++;
; var_b--;
; if (var_b <= 0x1) break;
; printf("%x %x\n", var_a, var_b)
; }
;
; Но по соображениям удобочитаемости имеет смысл скомпоновать это код в for
; for (var_a=1,var_b=0xA;var_b>1;var_a++,var_b--) printf("%x %x\n",var_a,var_b)
;
loc_401045: ; CODE XREF: main+2Cj
mov esp, ebp
pop ebp
; Закрываем кадр стека
retn
main endp
Листинг 203
Оптимизированный вариант программы рассматривать не будем, т.к. это не покажет нам ничего нового. Какой бы компилятор мы не выбрали – выражения инициализации и модификации счетчиков будут обрабатываться вполне корректно в порядке их объявления в тексте программы, а вот множественные выражения продолжения цикла не умеет правильно обрабатывать ни один компилятор!
Идентификация функций
"Для некоторых людей программирование является такой же внутренней потребностью, подобно тому, как коровы дают молоко, или писатели стремятся писать
Николай Безруков
Функция
(так же называемая процедурой или подпрограммой) – основная структурная единица процедурных и объективно-ориентированных языков, поэтому дизассемблирование кода обычно начинается с отождествления функций и идентификации передаваемых им аргументов.
Строгого говоря, термин "функция" присутствует не во всех языках, но даже там, где он присутствует, его определение варьируется от языка к языку. Не вдаваясь в детали, мы будем понимать под функцией обособленную последовательность команд, вызываемую из различных частей программы. Функция может принимать один и более аргументов, а может не принимать ни одного; может возвращать результат своей работы, а может и не возвращать, - это уже не суть важно. Ключевое свойство функции – возвращение управления на место ее вызова, а ее характерный признак – множественный вызов из различных частей программы (хотя некоторые функции вызываются лишь из одного места).
Откуда функция знает: куда следует возвратить управление? Очевидно, вызывающий код должен предварительно сохранить адрес возврата и вместе с прочими аргументами передать его вызываемой функции. Существует множество способов решения этой проблемы: можно, например, перед вызовом функции поместить в ее конец безусловный переход на адрес возврата, можно сохранить адрес возврата в специальной переменной и после завершения функции выполнить косвенный переход, используя эту переменную как операнд инструкции jump,… Не останавливаясь на обсуждении сильных и слабых сторон каждого метода, отметим, что компиляторы в подавляющем большинстве случаев используют специальные машинные команды CALL и RET
соответственно предназначенные для вызова и выхода из функции.
Инструкция CALL закидывает адрес следующей за ней инструкции на вершину стека, а RET стягивает и передает на него управление. Тот адрес, на который указывает инструкция CALL, и есть адрес начала функции.
А замыкает функцию инструкция RET
(но, внимание: не всякий RET обозначает конец функции! подробнее об этом см. "Идентификация значения, возращенного функцией").
Таким образом, распознать функцию можно двояко: по перекрестным ссылкам, ведущим к машинной инструкции CALL и по ее эпилогу, завершающемуся инструкцией RET. Перекрестные ссылки и эпилог в совокупности позволяют определить адреса начала и конца функции. Немного забегая вперед (см. "Идентификация локальных стековых переменных") заметим, что в начале многих функций присутствует характерная последовательность команд, называемая эпилогом, которая так же пригодна для идентификации функций. А теперь расскажем обо всем этом поподробнее.
::Перекрестные ссылки. Просматривая дизассемблерный код, находим все инструкции CALL – содержимое их операнда и будет искомым адресом начала функции. Адрес не виртуальных функций, вызываемых по имени, вычисляется еще на стадии компиляции и операнд инструкции CALL
в таких случаях представляет собой непосредственное значение. Благодаря этому адрес начала функции выявляется простым синтаксическим анализом: ищем контекстным поиском все подстроки "CALL" и запоминаем (записываемым) непосредственные операнды.
Рассмотрим следующий пример:
func();
main(){
int a;
func();
a=0x666;
func();
}
func(){
int a;
a++;
}
Листинг 6 Пример, демонстрирующий непосредственный вызов функции
Результат его компиляции должен выглядеть приблизительно так:
.text:00401000 push ebp
.text:00401001 mov ebp, esp
.text:00401003 push ecx
.text:00401004 call 401019
.text:00401004 ; Вот мы выловили инструкцию call c
непосредственным операндом,
.text:00401004 ; представляющим собой адрес начала функции. Точнее - ее смещение
.text:00401004 ; в кодовом сегменте (в данном случае в сегменте ".text")
.text:00401004 ; Теперь можно перейти к строке ".text:00401019" и, дав функции
.text:00401004 ; собственное имя, заменить операнд инструкции call
на конструкцию
.text:00401004 ; "call offset Имя функции"
.text:00401004 ;
.text:00401009 mov dword ptr [ebp-4], 666h
.text:00401010 call 401019
.text:00401010 ; А вот еще один вызов функции! Обратившись к строке ".text:401019"
.text:00401010 ; мы увидим, что эта совокупность инструкций уже определена как функция
.text:00401010 ; и все, что потребуется сделать, – заменить call
401019 на
.text:00401010 ; "call offset Имя функции"
.text:00401010
.text:00401015 mov esp, ebp
.text:00401017 pop ebp
.text:00401018 retn
.text:00401018 ; Вот нам встретилась инструкция возврата из функции, однако, не факт
.text:00401018 ; что это действительно конец функции – ведь функция может иметь и
.text:00401018 ; и несколько точек выхода. Однако, смотрите: следом за ret
.text:00401018 ; расположено начало функции "моя функция", отождествленное по
.text:00401018 ; операнду инструкции call.
.text:00401018 ; Поскольку, функции не могут перекрываться, выходит, что данный ret -
.text:00401018 ; конец функции!
.text:00401018 ;
.text:00401019 push ebp
.text:00401019 ; На эту строку ссылаются операнды нескольких инструкций call.
.text:00401019 ; Следовательно, это – адрес начала функции.
.text:00401019 ; Каждая функция должна иметь собственное имя – как бы нам ее назвать?
.text:00401019 ; Назовем ее "моя функция" :-)
.text:00401019 ;
.text:0040101A mov ebp, esp ; <-
.text:0040101C push ecx ; <-
.text:0040101D mov eax, [ebp-4] ; <-
.text:00401020 add eax, 1 ; <- Это – тело "моей функции"
.text:00401023 mov [ebp-4],eax ; <-
.text:00401026 mov esp, ebp ; <-
.text:00401028 pop ebp ; <-
.text:00401029 retn
.text:00401029; Конец "моей функции"
Листинг 7
Как мы видим, все очень просто.
Однако задача заметно усложняется, если программист (или компилятор) использует косвенные вызовы функций, передавая их адрес в регистре и динамически вычисляя его (адрес, не регистр!) на стадии выполнения программы. Именно так, в частности, реализована работа с виртуальными функциями (см. "Идентификация виртуальных функций"), однако, в любом случае компилятор должен каким-то образом сохранить адрес функции в коде, значит, его можно найти и вычислить! Еще проще загрузить исследуемое приложение в отладчик, установить на "подследственную" инструкцию CALL точку останова и, дождавшись всплытия отладчика, посмотреть по какому адресу она передаст управление.
Рассмотрим следующий пример:
func();
main(){
int (a*)();
a=func;
a();
}
Листинг 8 Пример, демонстрирующий вызов функции по указателю
Результат его компиляции должен в общем случае выглядеть так:
.text:00401000 push ebp
.text:00401001 mov ebp, esp
.text:00401003 push ecx
.text:00401004 mov dword ptr [ebp-4], 401012
.text:0040100B call dword ptr [ebp-4]
.text:0040100B ; Вот инструкция CALL, осуществляющая косвенный вызов функции
.text:0040100B ; по адресу, содержащемуся в ячейке [EBP-4].
.text:0040100B ; Как знать – что же там содержится? Прокрутим экран дизассемблера
.text:0040100B ; немного вверх, пока не встретим строку "mov dword
ptr [ebp-4],401012"
.text:0040100B ; Ага! Значит, управление передается по адресу ".text: 401012", -
.text:0040100B ; это и есть адрес начала функции!
.text:0040100B ; Даем функции имя и заменяем "mov dword ptr
[ebp-4], 401012" на
.text:0040100B ; "mov dword ptr [ebp-4], offset
Имя функции"
.text:0040100B ;
.text:0040100E mov esp, ebp
.text:00401010 pop ebp
.text:00401011 retn
Листинг 9
В некоторых, достаточно немногочисленных, программах встречается и косвенный вызов функции с комплексным вычислением ее адреса. Рассмотрим следующий пример:
func_1();
func_2();
func_3();
main()
{
int x;
int a[3]={(int) func_1,(int) func_2, (int) func_3};
int (*f)();
for (x=0;x < 3;x++)
{
f=(int (*)()) a[x];
f();
}
}
Листинг 10 Пример, демонстрирующий вызов функции по указателю с комплексным вычислением целевого адреса
Результат его дизассемблирования в общем случае должен выглядеть так:
.text:00401000 push ebp
.text:00401001 mov ebp, esp
.text:00401003 sub esp, 14h
.text:00401006 mov [ebp+0xC], offset sub_401046
.text:0040100D mov [ebp+0x8], offset sub_401058
.text:00401014 mov [ebp+0x4], offset sub_40106A
.text:0040101B mov [ebp+0x14], 0
.text:00401022 jmp short loc_40102D
.text:00401024 mov eax, [ebp+0x14]
.text:00401027 add eax, 1
.text:0040102A mov [ebp+0x14], eax
.text:0040102D cmp [ebp+0x14], 3
.text:00401031 jge short loc_401042
.text:00401033 mov ecx, [ebp+0x14]
.text:00401036 mov edx, [ebp+ecx*4+0xC]
.text:0040103A mov [ebp+0x10], edx
.text:0040103D call [ebp+0x10]
.text:0040103D ; Так-с, косвенный вызов функции. А что у нас в [EBP+0x10]?
.text:0040103D ; Поднимаем глаза на строку вверх – в [EBP+0x10] у нас значение EDX.
.text:0040103D ; А чем равен сам EDX? Прокручиваем еще одну строку вверх – EDX
равен
.text:0040103D ; содержимому ячейки [EBP+ECX*4+0xC]. Вот дела! Мало, что нам надо
.text:0040103D ; узнать содержимое этой ячейки, так еще предстоит вычислить ее адрес!
.text:0040103D ; Чему равен ECX? Содержимому [EBP+0x14]. А оно чему равно?
.text:0040103D ; "Сейчас выясним…" бормочем мы себе под нос, прокручивая экран
.text:0040103D ; дизассемблера вверх. Ага, нашли, - в строке 0x40102A в него
.text:0040103D ; загружается содержимое EAX! Какая радость! И долго мы по коду так
.text:0040103D ; блуждать будем?
.text:0040103D ; Конечно, можно затратив неопределенное количество времени и усилий
.text:0040103D ; реконструировать весь ключевой алгоритм целиком (тем более, что мы
.text:0040103D ; практически подошли к концу анализа), но где гарантия, что при этом
.text:0040103D ; не будут допущены ошибки?
.text:0040103D ; Гораздо быстрее и надежнее загрузить исследуемую программу в
.text:0040103D ; отладчик, установить бряк на строку "text:0040103D" и,
.text:0040103D ; дождавшись всплытия отладчика, посмотреть: что у нас расположено
.text:0040103D ; в ячейке [EBP+0х10]. Отладчик будут всплывать трижды, причем каждый
.text:0040103D ; раз показывать новый адрес! Заметим, что определить этот факт в
.text:0040103D ; дизассемблере можно только после полной реконструкции алгоритма!
.text:0040103D ; Однако не стоит по поводу мощи отладчика питать излишних иллюзий!
.text:0040103D ; Программа может тысячу раз вызывать одну и ту же функцию, а на
.text:0040103D ; тысяче первый – вызвать совсем другую! Отладчик бессилен это
.text:0040103D ; определить. Ведь вызов такой функции может произойти в
.text:0040103D ; непредсказуемый момент,например, при определенном сочетании времени,
.text:0040103D ; данных, обрабатываемых программой и текущей фазы Луны. Ну не будем же
.text:0040103D ; мы целую вечность гонять программу под отладчиком?
.text:0040103D ; Дизассемблер – дело другое. Полная реконструкция алгоритма позволит
.text:0040103D ; однозначно и гарантированно отследить все адреса косвенных вызовов.
.text:0040103D ; Вот потому, дизассемблер и отладчик должны скакать в одной упряжке!
.text:0040103D ;
.text:00401040 jmp short loc_401024
.text:00401042
.text:00401042 mov esp, ebp
.text:00401044 pop ebp
.text:00401045 retn
Самый тяжелый случай представляют "ручные" вызовы функции командой JMP с предварительной засылок в стек адреса возврата. Вызов через JMP в общем случае выглядит так: "PUSH ret_addrr/JMP func_addr", где "ret_addrr"
и "func_addr" – непосредственные или косвенные адреса возврата и начала функции соответственно. (Кстати, заметим, что команды PUSH и JPM не всегда следует одна за другой, и порой бывают разделены другими командами)
Возникает резонный вопрос – чем же там плох CALL, и зачем прибегать к JMP? Дело в том, что функция, вызванная по CALL, после возврата управления материнской функции всегда передает управление команде, следующей за CALL. В ряде случаев (например, при структурной обработке исключений) возникает необходимость после возврата из функции продолжать выполнение не со следующей за CALL командой, а совсем с другой ветки программы. Тогда-то и приходится "вручную" заносить требуемый адрес возврата и вызывать дочернею функцию через JMP.
Идентифицировать такие функции (особенно если они не имею пролога – см. "Пролог") очень сложно – контекстный поиск ничего не даст, поскольку команд JMP, использующихся для локальных переходов, в теле любой программы очень и очень много – попробуй-ка, проанализируй их все! Если же этого не сделать – из поля зрения выпадут сразу две функции – вызываемая функция и функция, на которую передается управление после возврата. К сожалению, быстрых решений этой проблемы не существует – единственная зацепка – вызывающий JMP практически всегда выходит за границы функции, в теле которой он расположен. Определить же границы функции можно по эпилогу (см. "Эпилог").
Рассмотрим следующий пример:
funct();
main()
{
__asm
{
LEA ESI, return_addr
PUSH ESI
JMP funct
return_addr:
}
}
Листинг 11 Пример, демонстрирующий "ручной" вызов функции инструкцией JPM
Результат его компиляции в общем случае должен выглядеть так:
.text:00401000 push ebp
.text:00401001 mov ebp, esp
.text:00401003 push ebx
.text:00401004 push esi
.text:00401005 push edi
.text:00401006 lea esi, [401012h]
.text:0040100C push esi
.text:0040100D jmp 401017
.text:0040100D ; Смотрите – казалось бы тривиальный условный переход, - что в нем
.text:0040100D ; такого? Ан, нет! Это не простой переход, - это замаскированный
.text:0040100D ; вызов функции! Откуда это следует? А давайте перейдем по адресу
.text:0040100D ; 0x401017 и посмотрим
.text:0040100D ; .text:00401017 push ebp
.text:0040100D ; .text:00401018 mov ebp, esp
.text:0040100D ; .text:0040101A pop ebp
.text:0040100D ; .text:0040101B retn
.text:0040100D ; ^^^^
.text:0040100D ; Как вы думаете, куда этот ret возвращает управление? Естественно,
.text:0040100D ; по адресу, лежащему на верхушке стека. А что у нас лежит на стеке?
.text:0040100D ; PUSH EBP из строки 401017 обратно выталкивается инструкцией POP
.text:0040100D ; из строки 40101B, так… возвращаемся назад, к месту безусловного
.text:0040100D ; перехода и начинаем медленно прокручивать экран дизассемблера вверх
.text:0040100D ; отслеживая все обращения к стеку. Ага, попалась птичка! Инструкция
.text:0040100D ; PUSH ESI из строки 401000C закидывает на вершину стека содержимое
.text:0040100D ; регистра ESI, а он сам, в свою очередь, строкой выше принимает
.text:0040100D ; "на грудь" значение 0x401012 – это и есть адрес начала функции,
.text:0040100D ; вызываемой командой "JMP" (вернее, не адрес, а смещение, но это не
.text:0040100D ; принципиально важно).
.text:0040100D ;
.text:00401012 pop edi
.text:00401013 pop esi
.text:00401014 pop ebx
.text:00401015 pop ebp
.text:00401016 retn
Листинг 12
Автоматическая идентификация функций посредством IDA Pro. Дизассемблер IDA Pro способен анализировать операнды инструкций CALL, что позволяет ему автоматически разбивать программу на функции. Причем, IDA вполне успешно справляется с большинством косвенных вызовов! С комплексными вызовами и "ручными" вызовами функций командой JMP
она, правда, совладеть пока не в состоянии, но это не повод для огорчения – ведь подобные конструкции крайне редки и составляют менее процента от "нормальных" вызов функций, тех, которые IDA без труда распознает!
::Пролог. Большинство не оптимизирующих компиляторов помешают в начало функции следующий код, называемый прологом.
push ebp
mov ebp, esp
sub esp, xx
Листинг 13 Обобщенный код пролога функции
В общих чертах назначение пролога сводиться к следующему: если регистр EBP
используется для адресации локальных переменных (как часто и бывает), то перед его использованием он должен быть сохранен в стеке (иначе вызываемая функция "сорвет крышу" материнской), затем в EBP копируется текущее значение регистра указателя вершины стека (ESP) – происходит, так называемое, открытие кадра стека, и значение ESP
уменьшается на размер области памяти, выделенной под локальные переменные.
Последовательность PUSH EBP/MOV EBP,ESP/SUB ESP,xx
может служить хорошей сигнатурой для нахождения всех функций в исследуемом файле, включая и тех, на которые нет прямых ссылок. Такой прием, в частности, использует в своей работе IDA Pro, однако, оптимизирующие компиляторы умеют адресовать локальные переменные через регистр ESP и используют EBP
как и любой другой регистр общего назначения. Пролог оптимизированных функций состоит из одной лишь команды SUB ESP, xxx – последовательность слишком короткая для использования ее в качестве сигнатуры функции, - увы. Более подробный рассказ об эпилогах функций нас ждет впереди (см. "Идентификация локальных стековых переменных"), поэтому, во избежание никому не нужного дублирования, не будем здесь на нем останавливаться.
::Эпилог. В конце своей жизни функция закрывает кадр стека, перемещая указатель вершины стека "вниз", и восстанавливает прежнее значение EBP (если только оптимизирующий компилятор не адресовал локальные переменные через ESP, используя EBP
как обычный регистр общего назначения). Эпилог функции может выглядеть двояко: либо ESP увеличивается на нужное значение командой ADD, либо в него копируется значение EBP, указывающие на низ кадра стека:
pop ebp mov esp, ebp
add esp, 64h pop ebp
retn retn
Эпилог 1 Эпилог 2
Листинг 14 Обобщенный код эпилога функции
Важно отметить: между командами POP EBP/ADD ESP, xxx
и MOV ESP,EBP/POP EBP
могут находиться и другие команды – они не обязательно должны следовать вплотную друг к другу. Поэтому, для поиска эпилогов контекстный поиск непригоден – требуется применять поиск по маске.
Если функция написана с учетом соглашение PASCAL, то ей приходится самостоятельно очищать стек от аргументов. В подавляющем большинстве случаев это осуществляется инструкцией RET n, где n – количество байт, снимаемых из стека после возврата. Функции же, соблюдающие Си-соглашение, предоставляют очистку стека вызывающему их коду и всегда оканчиваются командой RET. API-функции Windows представляют собой комбинацию соглашений Си и PASCAL – аргументы заносятся в стек справа налево, но очищает стек сама функция (подробнее обо всем этом см. "Идентификация аргументов функций").
Таким образом, RET может служить достаточным признаком эпилога функции, но не всякий эпилог – это конец. Если функция имеет в своем теле несколько операторов return (как часто и бывает) компилятор в общем случае генерирует для каждого из них свой собственный эпилог. Посмотрите – находится ли за концом эпилога новый пролог или продолжается код старой функции? Не забывайте и о том, что компиляторы обычно не помещают в исполняемый файл код, никогда не получающий управления. Т.е. у функции будет всего один эпилог, а все, находящееся после первого return, будет выброшено как ненужное:
int func(int a) push ebp
{ mov ebp, esp
mov eax, [ebp+arg_0]
return a++; mov ecx, [ebp+arg_0]
a=1/a; add ecx, 1
return a; mov [ebp+arg_0], ecx
pop ebp
} retn
Листинг 15 Пример, демонстрирующий выбрасывание компилятором кода, расположенного за безусловным оператором return
Напротив, если внеплановый выход из функции происходит при срабатывании некоторого условия, – такой return будет сохранен компилятором и "окаймлен" условным переходом, прыгающим через эпилог.
int func(int a)
{
if (!a) return a++;
return 1/a;
}
Листинг 16 Пример, демонстрирующий функцию с несколькими эпилогами
push ebp
mov ebp, esp
cmp [ebp+arg_0], 0
jnz short loc_0_401017
mov eax, [ebp+arg_0]
mov ecx, [ebp+arg_0]
add ecx, 1
mov [ebp+arg_0], ecx
pop ebp
retn
; Да, это ^^^^^^^^^^^^^^ -- явно эпилог функции, но,
; смотрите: следом идет продолжение кода функции, а
; вовсе не новый пролог!
loc_0_401017: ; CODE XREF: sub_0_401000+7^j
; Данная перекрестная ссылка, приводящая нас к условному переходу,
; говорит о том, что этот код – продолжение прежней функции, а отнюдь не
; начало новой, ибо "нормальные" функции вызываются не jump, а CALL!
; А если это "ненормальная" функция? Что ж, это легко проверить – достаточно
; выяснить: лежит ли адрес возврата на вершине стека или нет? Смотрим –
; нет, не лежит, следовательно, наше предположение относительно продолжения
; кода функции верно.
mov eax, 1
cdq
idiv [ebp+arg_0]
loc_0_401020: ; CODE XREF: sub_0_401000+15^j
pop ebp
retn
Листинг 17
Специальное замечание: начиная с 80286-процессора, в наборе команд появились две инструкции ENTER и LEAVE, предназначенные специально для открытия и закрытия кадра стека. Однако они практически никогда не используются современными компиляторами. Почему? Причина в том, что ENTER и LEAVE очень медлительны, намного медлительнее PUSH EBP/MOV EBP,ESP/SUB ESB, xxx
и MOV ESP,EBP/POP EBP. Так, на Pentium ENTER выполняется за десять тактов, а приведенная последовательность команд – за семь. Аналогично, LEAVE требует пять тактов, хотя туже операцию можно выполнить за два (и даже быстрее, если разделить MOV ESP,EBP/POP EBP какой-нибудь командой).
Поэтому, современный читатель никогда не столкнется ни с ENTER, ни с LEAVE. Хотя, помнить об их назначении будет нелишне (мало ли, вдруг придется дизассемблировать древние программы, или программы, написанные на ассемблере, – не секрет, что многие пишущие на ассемблере очень плохо знают тонкости работы процессора и их "ручная оптимизация" заметно уступает компилятору по производительности).
"Голые" (naked) функции.
Компилятор Microsoft Visual C++ поддерживает нестандартный квалификатор "naked", позволяющий программистам создавать функции без пролога и эпилога. Без пролога и эпилога вообще! Компилятор даже не помещает в конце функции RET и это придется делать вручную, прибегая к ассемблерной вставке "__asm{ret}" (Использование return не приводит к желаемому результату).
Вообще-то, поддержка naked-функций задумывалась исключительно для написания драйверов на чистом Си (ну, почти чистом, с небольшой примесью ассемблерных включений), но она нашла неожиданное признание и среди разработчиков защитных механизмов. Действительно, приятно иметь возможность "ручного" создания функций, не беспокоясь, что их непредсказуемым образом "изуродует" компилятор.
Для нас же, кодокопателей, в первом приближении это обозначает, что в программе может встретиться одна (или несколько) функций, не содержащих ни пролога, ни эпилога. Ну и что в этом страшного? Оптимизирующие компиляторы так же выкидывают пролог, а от эпилога оставляют один лишь RET, - но функции элементарно идентифицируются по вызывающей их инструкции CALL.
Идентификация встраиваемых (inline) функций. Самый эффективный способ избавится от накладных расходов на вызов функций – не вызывать их. В самом деле – почему бы ни встроить код функции непосредственно в саму вызывающую функцию? Конечно, это ощутимо увеличит размер (и тем ощутимее, чем из больших мест функция вызывается), но зато значительно увеличит скорость выполнения программы (и тем значительнее, чем чаще "развернутая" функция вызывается).
Чем плоха "развертка" функций для исследования программы? Прежде всего – она увеличивает размер "материнской" функции и делает ее код менее наглядным, - вместо "CALL\TEST EAX,EAX\JZ xxx" с бросающимся в глаза условным переходом, – теперь куча ничего не напоминающих инструкций, в логике работы которых еще предстоит разобраться!
Вспомним: мы уже сталкивались с таким приемом при анализе crackme02:
mov ebp, ds:SendMessageA
push esi
push edi
mov edi, ecx
push eax
push 666h
mov ecx, [edi+80h]
push 0Dh
push ecx
call ebp ; SendMessageA
lea esi, [esp+678h+var_668]
mov eax, offset aMygoodpassword ; "MyGoodPassword"
loc_0_4013F0: ; CODE XREF: sub_0_4013C0+52j
mov dl, [eax]
mov bl, [esi]
mov cl, dl
cmp dl, bl
jnz short loc_0_401418
test cl, cl
jz short loc_0_401414
mov dl, [eax+1]
mov bl, [esi+1]
mov cl, dl
cmp dl, bl
jnz short loc_0_401418
add eax, 2
add esi, 2
test cl, cl
jnz short loc_0_4013F0
loc_0_401414: ; CODE XREF: sub_0_4013C0+3Cj
xor eax, eax
jmp short loc_0_40141D
loc_0_401418: ; CODE XREF: sub_0_4013C0+38j
sbb eax, eax
sbb eax, 0FFFFFFFFh
loc_0_40141D: ; CODE XREF: sub_0_4013C0+56j
test eax, eax
push 0
push 0
jz short loc_0_401460
Листинг 18
Встроенные функции не имеют ни собственного пролога, ни эпилога, их код и локальные переменные (если таковые имеются) полностью "вживлены" в вызывающую функцию, – результат компиляции выглядит в точности так, как будто бы никакого вызова функции и не было. Единственная зацепка – встраивание функции неизбежно приводит к дублированию ее кода во всех местах вызова, а это хоть с трудом, но можно обнаружить. "С трудом" – потому, что встраиваемая функция, становясь частью вызывающей функции, "в сквозную" оптимизируется в контексте последней, что приводит к значительным вариациям кода.
Рассмотрим такой пример:
#include <stdio.h>
__inline int max( int a, int b )
{
if( a > b ) return a;
return b;
}
int main(int argc, char **argv)
{
printf("%x\n",max(0x666,0x777));
printf("%x\n",max(0x666,argc));
printf("%x\n",max(0x666,argc));
return 0;
}
Листинг 19 Пример, демонстрирующий, сквозную оптимизацию встраиваемых функций
Результат его компиляции в общем случае должен выглядеть так:
push esi
push edi
push 777h ;
ß
код 1-го
вызова max
; Компилятор вычислил значение функции max
еще на этапе компиляции и
; вставил его в программу, избавившись от лишнего вызова функции
push offset aProc ; "%x\n"
call printf
mov esi, [esp+8+arg_0]
add esp, 8
cmp esi, 666h ; ß код 2-го вызова max
mov edi, 666h ; ß код 2-го вызова max
jl short loc_0_401027 ; ß код 2-го вызова max
mov edi, esi ; ß код 2-го вызова max
loc_0_401027: ; CODE XREF: sub_0_401000+23j
push edi
push offset aProc ; "%x\n"
call printf
add esp, 8
cmp esi, 666h ; ß код 3-го вызова max
jge short loc_0_401042 ; ß код 2-го вызова max
mov esi, 666h ; ß код 2-го вызова max
; Смотрите – как изменился код функции! Во-первых, нарушилась очередность
; выполнения инструкций – было "CMP
-> MOV
– Jx", а стало "CMP
-> Jx, MOV"
; А во-вторых, условный переход JL
загадочным образом превратился в JGE!
; Впрочем, ничего загадочного тут нет – просто идет сквозная оптимизация!
; Поскольку, после третьего вызова функции max
переменная argc, размещенная
; компилятором в регистре ESI, более не используется, у компилятора появляется
; возможность непосредственно модифицировать этот регистр, а не вводить
; временную переменную, выделяя под нее регистр EDI
; (см. "Идентификация переменных -> регистровых и временныех
переменныех")
loc_0_401042: ; CODE XREF: sub_0_401000+3Bj
push esi
push offset aProc ; "%x\n"
call printf
add esp, 8
mov eax, edi
pop edi
pop esi
retn
Листинг 20
Смотрите, - при первом вызове компилятор вообще выкинул весь код функции, вычислив результат ее работы еще на стадии компиляции (действительно, 0x777 всегда больше 0x666 и не за чем тратить процессорные такты на их сравнение). А второй вызов очень мало похож на третий, несмотря на то, что в обоих случаях функции передавались один и те же аргументы! Тут не то, что поиск по маске (не говоря уже о контекстном поиске), человек не разберется – одна и та же функция вызывается или нет!

Иное дело – 16-разрядные приложения для MS-DOS и Windows 3.x. В них максимально допустимый размер сегментов составляет всего лишь 64 килобайта, чего явно недостаточно для большинства приложений. В крошечной (tiny) модели памяти сегменты кода, стека и данных так же расположены в одном адресном пространстве, но в отличие от плоской модели это адресное пространство чрезвычайно ограничено в размерах, и мало-мальски серьезное приложение приходится рассовывать по нескольким сегментам.
Теперь для вызова функции уже не достаточно знать ее смещение, – требуется указать еще и сегмент, в котором она расположена. Однако сегодня об этом рудименте старины можно со спокойной совестью забыть. На фоне грядущей 64-разрядной версии Windows, подробно описывать 16-разрядный код просто смешно!
___Порядок трансляции функций: Большинство компиляторов располагают функции в исполняемом файле в том же самом порядке, в котором они были объявлены в программе.
Идентификация глобальных переменных
Да, подумала Алиса, - вот это дерябнулась, так дерябнулась!
Программа, нашпигованная глобальными переменными, - едва ли на самое страшное проклятие хакеров, – вместо древа строгой иерархии, компоненты программы тесно переплетаются друг с другом и, чтобы понять алгоритм одного из них, – приходится "прочесывать" весь листинг в поисках перекрестных ссылок. А в совершенстве восстанавливать перекрестные ссылки не умеет ни один дизассемблер, - даже IDA!
Идентифицировать глобальные переменные очень просто, гораздо проще, чем все остальные конструкции языков высокого уровня. Глобальные переменные сразу же выдают себя непосредственной адресаций памяти, т.е. обращение к ним выглядит приблизительно так: "MOV EAX,[401066]", где 0x401066
и есть адрес глобальной переменной.
Сложнее понять: для чего эта переменная, собственно, нужна и каково ее содержимое на данный момент. В отличие от локальных переменных, глобальные – контекстно-зависимы. В самом деле, каждая локальная переменная инициализируется "своей" функцией и не зависит от того, какие функции были вызваны до нее. Напротив, глобальные переменные может модифицировать кто угодно и когда угодно, - значение глобальной переменной в произвольной точке программы не определено. Чтобы его выяснить, необходимо проанализировать все, манипулирующие с ней функции, и – более того – восстановить порядок из вызова. Подробнее этот вопрос будет рассмотрен в главе "___Построение дерева вызовов", - пока же разберемся с техникой восстановления перекрестных ссылок.
Техника восстановления перекрестных ссылок. В большинстве случаев с восстановлением перекрестных ссылок сполна справляется автоматический анализатор IDA, и делать это "вручную" практически никогда не придется. Однако бывает, что IDA ошибается, да и не всегда (и не у всех!) она бывает под рукой. Поэтому, совсем нелишне уметь справляться с глобальными переменными самому.
Отслеживание обращений к глобальным переменным контекстным поиском их смещения в сегменте кода [данных].
Непосредственная адресация глобальных переменных чрезвычайно облегчает поиск манипулирующих с ними машинных команд. Рассмотрим, например, такую конструкцию: "MOV EA,[0x41B904]". После ассемблирования она будет выглядеть так: "A1 04 B9 41 00". Смещение глобальной переменной записывается "как есть" (естественно, с соблюдением обратного порядка следования байт – старшие располагаются по большему адресу, а младшие – по меньшему).
Тривиальный контекстный поиск позволит выявить все обращения к интересующей вас глобальной переменной, достаточно лишь узнать ее смещение, переписать его справа налево и… вместе с полезной информацией получить какое-то количество мусора. Ведь не каждая число, совпадающее по значению со смещением глобальной переменной, обязано быть указателем на эту переменную. Тому же "04 B9 41 00" удовлетворяет, например, следующий контекст:
83EC04 sub esp,004
B941000000 mov ecx,000000041
Ошибка очевидна – искомое значение не является операндом инструкции, более того, оно "захватило" сразу две инструкции! Отбрасыванием всех вхождений, пересекающих границы инструкции, мы сразу же избавляется от значительной части "мусора". Единственная проблема – как определить границы инструкций, - по части инструкции о самой инструкции сказать ничего нельзя.
Вот, например, встречается нам следующее: "…8D 81 04 B9 41 00 00…". Эту последовательность, за вычетом последнего нуля, можно интерпретировать так: "lea eax,[ecx+0х41B904]", но если предположить, что 0x8D принадлежит "хвосту" предыдущей команды, то получится следующее: "add d,[ecx][edi]*4,000000041", а, может быть, здесь и вовсе несколько команд…
Самый надежный способ определения границ машинных команд – трассированное дизассемблирование, но, к сожалению, это чрезвычайно ресурсоемкая операция, и далеко не всякий дизассемблер умеет трассировать код.
Поэтому, приходится идти другим путем…
Образно машинный код можно изобразить в виде машинописного текста, напечатанного без пробелов. Если попробовать читать с произвольной позиции, мы, скорее всего, попадем на середину слова и ничего не поймем. Может быть, волей случая, первые несколько слогов и сложатся в осмысленное слово (а то и два!), но дальше пойдет сплошная чепуха. Например: "мамылараму". Ага, "мамы" – множественное число от "мама", подходит? Подходит. Дальше – "лараму". "Лараму" – это что, народный индийский герой такой со множеством родительниц? Или "Мамы ла Раму?" А как вам "Мамы Ла Ра Му" – в смысле три мамы "Ла, Ра и Му"? Да, скажите тоже, - вот, ерунда какая!!!
Смещаемся на одну букву вперед, оставляя "м" предыдущему слову. "А", - что ж, вполне возможно, это и есть союз "А", тем более что за ним идет осмысленное местоимение "мы", получается – "А мы Лараму" или "А мы Лара Му". Кто такой этот Лараму?!
Сдвигаемся еще на одну букву и читаем "мыла", а за ним "раму". Заработало! А "ам" стало быть, хвост от "мама".
Вот, примерно так читается и машинный код, причем, такая аналогия весьма полная. Слово (русское) не может начинаться с некоторых букв (например, с "Ы", мягкого и твердого знака), существуют характерные суффиксы и окончания, с сочетанием букв, практически не встречающихся в других частях предложения. Соответственно, видя в конец несколько подряд идущих нулей, можно с высокой степенью уверенности утверждать, что это непосредственное значение, а непосредственные значения располагаются в конце команды (см. "___Тонкости дизассемблирования").
Отличия констант от указателей или продолжаем разгребать мусор дальше. Вот, наконец, мы избавились от ложных срабатываний, бессмысленность которых очевидна с первого взгляда. Куча мусора заметно приуменьшилась, но… в ней все еще продолжают встречаться такие штучки как "PUSH 0x401010".
Что такое 0x401010
– константа или смещение? С равным успехом может быть и то, и другое. Пока не доберемся до манипулирующего с ней кода, мы вообще не сможем сказать ничего вразумительного. Если манипулирующий код обращается к 0x401010 по значению, - это константа (выражающая, например, скорость улепетывания Пяточка от Слонопотама), а если по ссылке – это указатель (в данном контексте смещение).
Подробнее эту проблему мы еще обсудим в главе "Идентификация констант и смещений", пока же заметим с большим облегчением, что минимальный адрес загрузки файла в Windows 9x равен 0x400000, и немного существует констант, выражаемых таким большим числом.
Замечание: минимальный адрес загрузки Windows NT равен 0x10000, однако, чтобы программа могла успешно работать и под NT, и под 9x, она должна грузиться не ниже 0x400000.

байт и допустимые значения смещений заключены в узком интервале [0x0, 0xFFFF], причем у большинства переменных смещения очень невелики и визуально неотличимы от констант.
Другая проблема – один сегмент чаще всего не вмещает в себя всех данных и приходится заводить еще один (а то и больше). Два сегмента – это еще ничего: один адресуется через регистр DS, другой – через ES и никаких трудностей в определении "это указатель на переменную какого
сегмента" не возникает. Например, если нас интересуют все обращения к глобальной переменной X, расположенной в основном сегменте по смещению 0x666, то команду MOV AX, ES:[0x666], мы сразу же откинем в мусорную корзину, т.к. основной сегмент адресуется через DS (по умолчанию), а здесь – ES. Правда, обращение может происходить и в два этапа. Например: "MOV BX,0x666/xxx---xxx/MOV AX,ES:[BX]", увидев "MOV BX,0x666" мы не только не можем определить сегмент, но и даже сказать – смещение ли это вообще? Впрочем, это не сильно затрудняет анализ…
Хуже, если сегментов данных в программе добрый десяток (а, что, может же потребоваться порядка 640 килобайт статической памяти?). Никаких сегментных регистров на это не хватит, и их переназначения будут происходить многократно. Тогда, чтобы узнать к какому именно сегменту происходит обращение, потребуется определить значение сегментного регистра. А как его определить? Самое простое – прокрутить экран дизассемблера немного вверх, ища глазами инициализацию данного сегментного регистра, помня то том, что она может осуществляться не только командой MOV segREG, REG, но довольно частенько и POP! Например, PUSH ES/POP DS
равносильно MOV DS, ES
– правда, команды MOV segREG, segREG
в "языке" микропроцессоров 80x86, увы, нет. Как нет команды MOV segREG, CONST, и ее приходится эмулировать вручную либо так: MOV AX, 0x666/MOV ES,AX, либо так: PUSH 0x666/POP ES.
Как хорошо, что 16-разрядный режим практически полностью ушел в прошлое, унося в песок истории все свои проблемы. Не только программисты, но и хакеры с переходом на 32-разрядный режим вздыхают с облегчением.
Косвенная адресация глобальных переменных. Довольно часто приходится слышать утверждение, что глобальные переменные всегда
адресуются непосредственно (исключая, конечно, ассемблерные вставки, - на ассемблере программист может обращаться к переменным как захочет). На самом же деле все далеко не так... Если глобальная переменная передается функции по ссылке (а почему бы программисту ни передать глобальную переменную по ссылке?), она будет адресоваться косвенно – через указатель.
Мне могут возразить – а зачем вообще явно передавать глобальную переменную функции? Любая функция и без этого может к ней обратится. Не спорю. Да, может, но только если знает об этом заранее. Вот, скажем, есть у нас функция xchg, обменивающая свои аргументы местами, и есть две глобальные переменные, которые позарез приспичило обменять. Функции xchg доступны все глобальные переменные, но она "не знает" какие из них необходимо обменивать (и необходимо ли это вообще?), вот и приходится ей явно передавать глобальные переменные как аргументы.
А это значит, что всех обращений к глобальным переменным простым контекстным поиском мы не нейдем. Самое печальное – не найдет их и IDA Pro (да и как бы она их могла найти? для этого ей потребовался бы полноценный эмулятор процессора или хотя бы основных команд), на чем мы и убедимся в следующем примере:
#include <stdio.h>
int a; int b; // Глобальные переменные a и b
// Функция, обменивающая значения аргументов
xchg(int *a, int *b)
{
int c; c=*a; *b=*a; *b=c;
// ^^^^^^^^^^^^^^^^^^ косвенное обращение к аругментам по указателю
// если аргументы функции – глобальные переменные, то они будут адресоваться
// не прямо, а косвенно
}
main()
{
a=0x666; b=0x777; // Здесь – непосредственное обращение к глобальным переменным
xchg(&a, &b); // Передача глобальной переменной по ссылке
}
Листинг 121 Явная передача глобальных переменных
Результат компиляции компилятором Microsoft Visual C++ должен выглядеть так:
main proc near ; CODE XREF: start+AFp
push ebp
mov ebp, esp
; Открываем кадр стека
mov dword_405428, 666h
; Инициализируем глобальную переменную dword_405428
; На то, что это действительно глобальная переменная указывает непосредственная
; адресация
mov dword_40542C, 777h
; Инициализируем глобальную переменную dword_40542C
push offset dword_40542C
; Смотрите! Передаем функции смещение глобальной переменной dword_40542C как
; аргумент (т.е. другими словами, передаем ее по ссылке)
; Это значит, что вызываемая функция будет обращаться к переменной косвенно,
; через указатель – точно так, как она обращается с локальными переменными
push offset dword_405428
; Передаем функции смещение глобальной переменной dword_405428
call xchg
add esp, 8
pop ebp
retn
main endp
xchg proc near ; CODE XREF: main+21p
var_4 = dword ptr -4
arg_0 = dword ptr 8
arg_4 = dword ptr 0Ch
push ebp
mov ebp, esp
; Открываем кадр стека
push ecx
; Выделяем память для локальной переменной var_4
mov eax, [ebp+arg_0]
; Загружаем а EAX содержимое аргумента arg_0
mov ecx, [eax]
; Смотрите! Косвенное обращение к глобальной переменной!
; А еще говорят – будто бы таких не бывает!
; Разумеется, определить, что обращение происходит именно к глобальной
; переменной (и какой именно глобальной переменной) можно только анализом
; кода вызывающей функции
mov [ebp+var_4], ecx
; Копируем значение *arg_0 в локальную переменную var_4
mov edx, [ebp+arg_4]
; Загружаем в EDX содержимое аргумента arg_4
mov eax, [ebp+arg_0]
; Загружаем в EAX содержимое аргумента arg_0
mov ecx, [eax]
; Копируем в ECX значение аргумента *arg_0
mov [edx], ecx
; Копируем в [arg_4] значение arg_0[0]
mov edx, [ebp+arg_4]
; Загружаем в EDX значение arg_4
mov eax, [ebp+var_4]
; Загружаем в EAX значение локальной переменной var_4 (хранит *arg_0)
mov [edx], eax
; Загружаем в *arg_4 значение *arg_0
mov esp, ebp
pop ebp
retn
xchg endp
dword_405428 dd 0 ; DATA XREF: main+3w main+1Co
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
dword_40542C dd 0 ; DATA XREF: main+Dw main+17o
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
; IDA
нашла все ссылки на обе глобальные переменные
; Первые две: main+3w
и main+Dw на код инициализации
; ('w' – от "write" – т.е. в обращение на запись)
: Вторые две: main+1Co
и main+17o
; ('o' – от "offset" – т.е. получение смещения глобальной переменной)
Листинг 122
Если среди перекрестных ссылок на глобальную переменную присутствуют ссылки с суффиксом 'o', обозначающие взятие смещения (аналог ассемблерной директивы offset), то сразу же вскидывайте свои ушки на макушку – раз offset, значит, имеет место передача глобальной переменной по ссылке.
А ссылка – это косвенная адресация. А косвенная адресация – это ласты: утомительный ручной анализ и никаких чудес прогресса.
Статические переменные. Статические переменные – это разновидность глобальных переменных, но с ограниченной областью видимости – они доступны только из той функции, в которой и были объявлены. Во всем остальном статические и глобальные переменные полностью совпадают – обои размещаются в сегменте данных, обои непосредственно адресуются (исключая случаи обращения через ссылку), обои…
…есть лишь одна существенная разница – к глобальной переменной могут обращаться любые функции, а к статической – только одна. А как насчет глобальных переменных, используемых лишь одной функций? Да какие же это глобальные переменные?! Это – не глобальность, это – кривость исходного кода программы. Если переменная используется лишь одной функцией, нет никакой необходимости объявлять ее глобальной!
Всякая непосредственно адресуемая ячейка памяти – глобальная (статическая) переменная (см. исключения ниже), но не всякая глобальная (глобальная) переменная всегда адресуется непосредственно.
Идентификация if – then – else
Значение каждого элемента текста определяется контекстом его употребления. Текст не описывает мир, а вступает в сложные взаимоотношения с миром.
Тезис аналитической философии
Существует два вида алгоритмов – безусловные
и условные. Порядок действий безусловного алгоритма всегда постоянен и не зависит от входных данных. Например: "a=b+c". Порядок действий условных алгоритмов, напротив, зависит от входных данных. Например: "если c не равно нулю, то: a=b/c; иначе: вывести сообщение об ошибке".
Обратите внимание на выделенные жирным шрифтом ключевые слова "если", "то" и "иначе", называемые операторами условия или условными операторами. Без них не обходится ни одна программа (вырожденные примеры наподобие "Hello, World!" – не в счет). Условные операторы – сердце любого языка программирования. Поэтому, чрезвычайно важно уметь их правильно идентифицировать.
В общем виде (не углубляясь в синтаксические подробности отдельных языков программирования) оператор условия схематично изображается так:
IF (условие) THEN { оператор1; оператор2;} ELSE { операторa; операторb;}
Задача компилятора – преобразовать эту конструкцию в последовательность машинных команд, выполняющих оператор1, оператор2, если условие
истинно и, соответственно - операторa, операторb; если оно ложно. Однако микропроцессоры серии 80x86 поддерживают весьма скромный набор условных команд, ограниченный фактически одними условными переходами (касательно исключений см. "Оптимизация ветвлений"). Программистам, знакомым лишь с IBM PC, такое ограничение не покажется чем-то неестественным, между тем, существует масса процессоров, поддерживающих префикс условного выполнения инструкции. Т.е. вместо того, чтобы писать: "TEST ECX,ECX/JNZ xxx/MOV EAX,0x666", там поступают так: "TEST ECX,ECX/IFZ MOV EAX,0x666". "IFZ" – и есть префикс условного выполнения, разрешающий выполнение следующей команды только в том случае, если установлен флаг нуля.
В этом смысле микропроцессоры 80x86 можно сравнить с ранними диалектами языка Бейсика, не разрешающими использовать в условных выражениях никакой другой оператор кроме "GOTO". Сравните:
IF A=B THEN PRINT "A=B" 10 IF A=B THEN GOTO 30
20 GOTO 40
30 PRINT "A=B"
40 ... // прочий код программы
Листинг 139 Новый диалект "Бейсика" Старый диалект "Бейсика"
Если вы когда-нибудь программировали на старых диалектах Бейсика, то, вероятно, помните, что гораздо выгоднее выполнять GOTO если условие
ложно, а в противном случае продолжать нормальное выполнение программы. (Как видите, вопреки расхожему мнению, навыки программирования на Бейсике отнюдь не бесполезны, особенно – в дизассемблировании программ).
Большинство компиляторов (даже не оптимизирующих) инвертируют истинность условия, транслируя конструкцию "IF (условие) THEN {оператор1; оператор2}" в следующий псевдокод:
IF (NOT
условие) THEN
continue
оператор1;
оператор2;
continue:
…
Листинг 140
Следовательно, для восстановления исходного текста программы, нам придется вновь инвертировать условие и "подцепить" блок операторов {оператор1; оператор2} к ключевому слову THEN. Т.е. если откомпилированный код выглядит так:
10 IF A<>B THEN 30
20 PRINT "A=B"
30 …// прочий код программы
Листинг 141
Можно с уверенностью утверждать, что в исходном тексте присутствовали следующие строки: "IF A=B THEN PRINT "A=B"". А если, программист, наоборот, проверял переменные A и B на неравенство, т.е. "IF A<>B THEN PRINT "A<>B""? Все равно компилятор инвертирует истинность условия и сгенерирует следующий код:
10 IF A=B THEN 30
20 PRINT "A<>B"
30 …// прочий код программы
Листинг 142
Конечно, встречаются и дебильные компиляторы, страдающие многословием. Их легко распознать по безусловному переходу, следующему сразу же после условного оператора:
IF (условие) THEN
do
GOTO continue
do:
оператор1;
оператор2;
continue:
…
Листинг 143
В таком случае инвертировать условие не нужно. Впрочем, если это сделать, ничего страшного не произойдет, разве что код программы станет менее понятным, да и то не всегда.
Рассмотрим теперь как транслируется полная конструкция "IF (условие) THEN { оператор1; оператор2;} ELSE { операторa; операторb;}". Одни компиляторы поступают так:
IF (условие) THEN do_it
// Ветка ELSE
операторa;
операторb
GOTO continue
do_it:
//Ветка IF
оператор1;
оператор2;
continue:
А другие так:
IF (NOT условие) THEN else
//Ветка IF
оператор1;
оператор2;
GOTO continue
else:
// Ветка ELSE
операторa;
операторb
continue:
Листинг 144
Разница межу ними в том, что вторые инвертируют истинность условия, а первые – нет. Поэтому, не зная "нрава" компилятора, определить: как выглядел подлинный исходный текст программы – невозможно! Однако это не создает проблем, ибо условие всегда можно записать так, как это удобно. Допустим, не нравится вам конструкция "IF (c<>0) THEN a=b/c ELSE PRINT "Ошибка!"" пишите ее так: "IF (c==0) THEN PRINT "Ошибка!" ELSE a=b/c" и – ни каких гвоздей!
Типы условий: Условия делятся на простые (элементарные)
и сложные
(составные). Пример первых – "if (a==b)…", вторых "if ((a==b) && (a!=0))…". Очевидно, что любое сложное условие можно разложить на ряд простых условий. Вот с простых условий мы и начнем.
Существуют два основных типа элементарных условий: условия отношений
("меньше", "равно", "больше", "меньше или равно", "не равно", "больше или равно", соответственно обозначаемые как: "<", "==", ">", "<=", "!=", ">=") и логические условия ("И", "ИЛИ", "НЕ", "И исключающее ИЛИ", в Си-нотации соответственно обозначаемые так: "&", "|", "!", "^").
Известный хакерский авторитет Мэтт Питрек приплетает сюда и проверку битов, однако несколько некорректно смешивать в одну кучу людей и коней, даже если они чем-то и взаимосвязаны. Поэтому, о битовых операциях мы поговорим отдельно в одноименной главе.
Если условие истинно, оно возвращает булево значение TRUE, соответственно, если ложно – FALSE. Внутренне (физическое) представление булевых переменных зависит от конкретной реализации и может быть любым. По общепринятому соглашению, FALSE равно нулю, а TRUE не равно нулю. Часто (но не всегда) TRUE равно единице, но на это нельзя полагаться! Так, код "IF ((a>b)!=0)…" абсолютно корректен, а: "IF ((a>b)==1)…" привязан к конкретной реализации и потому нежелателен.
Обратите внимание: "IF ((a>b)!=0)…" проверяет на неравенство нулю отнюдь не значения самих переменных a и b, а именно – результата их сравнения. Рассмотрим следующий пример: "IF ((666==777)==0) printf("Woozl!")" – как вы думаете, что отобразится на экране, если его запустить? Правильно – "Woozl"! Почему? Ведь ни 666, ни 777
не равно нулю! Да, но ведь 666 != 777, следовательно, условие (666==777) – ложно, следовательно равно нулю. Кстати, если записать "IF ((a=b)==0)…" получится совсем иной результат – значение переменной b будет присвоено переменной a, и потом проверено на равенство нулю.
Логические условия чаще всего используются для связывания двух или более элементарных условий отношения в составное. Например, "IF ((a==b) && (a!=0))…". При трансляции программы компилятор всегда выполняют развертку составных условий в простые. В данном случае это происходит так: "IF a==b THEN IF a=0 THEN…"
На втором этапе выполняется замена условных операторов на оператор GOTO:
IF a!=b THEN continue
IF a==0 THEN continue
…// код условия
:continue
…// прочий код
Листинг 145
Порядок вычисления элементарных условий в сложном выражении зависит от прихотей компилятора, гарантируется лишь, что условия, "связанные" операцией логического "И" проверяются слева направо в порядке их объявления в программе.
Причем, если первое условие ложно, то следующее за ним вычислено не будет! Это дает возможность писать код наподобие следующего: "if ((filename) & (f=fopen(&filename[0],"rw")))…" – если указатель filename указывает на невыделенную область памяти (т.е. попросту говоря содержит нуль – логическое FALSE), функция fopen
не вызывается и ее краха не происходит. Такой способ вычислений получил название "быстрых булевых операций" (теперь-то вы знаете, что подразумевается под "быстротой").
Перейдем теперь к вопросу идентификации логических условий и анализу сложных выражений. Вернемся к уже облюбованному нами выражению "if ((a==b) && (a!=0))…" и вглядимся в результат его трансляции:
IF a!=b THEN continue -------!
IF a==0 THEN continue ---! !
…// код условия ! !
:continue <--! <---
…// прочий код
Листинг 146
Легко видеть – он выдает себя серией условных переходов к одной и той же метке, причем, - обратите внимание, - выполняется проверка на неравенство каждого из элементарных условий, а сама метка расположена позади кода условия.
Идентификация логической операции "ИЛИ" намного сложнее в силу неоднозначности ее трансляции. Рассмотрим это на примере выражения "if ((a==b) || (a!=0))…". Его можно разбить на элементарные операции и так:
IF a==b THEN do_it -----------!
IF a!=0 THEN do_it ––-! !
goto continue –––! ! !
:do_it ! <--! <-----!
…// код условия !
:continue <-!
…// прочий код
Листинг 147
и так:
IF a==b THEN do_it -----------!
IF a==0 THEN continue--! !
:do_it ! <-----!
…// код условия !
:continue <-----------!
…// прочий код
Листинг 148
Первый вариант обладает весьма запоминающийся внешностью – серия проверок (без инверсии условия) на одну и ту же метку, расположенную перед кодом условия, а в конце этой серии – безусловный переход на метку, расположенную позади кода условия.
Однако оптимизирующие компиляторы выкидывают безусловный переход, инвертируя проверку последнего условия в цепочке и, соответственно меняя адрес перехода. По неопытности эту конструкцию часто принимают за смесь OR
и AND. Кстати, о смещенных операциях – рассмотрим результат трансляции следующего выражения: "if ((a==b) || (a==c) && a(!=0))…":
IF a==b THEN check_null
IF a!=c THEN continue
check_null:
IF a==0 THEN continue
…// код условия
continue:
…// прочий код
Листинг 149
Как из непроходимого леса элементарных условий получить одно удобочитаемое составное условие? Начинаем плясать от печки, т.е. от первой операции сравнения. Смотрите, если условие a==b
окажется истинно, оно "выводит из игры" проверку условия a!=c. Такая конструкция характерна для операции OR – т.е. достаточно выполнения хотя бы одного условия из двух для "срабатывания" кода. Пишем в уме или карандашом: "if ((a==b) || …)", далее – если условие (a!=c) истинно, все дальнейшие проверки прекращаются, и происходит передача управления на метку, расположенную позади условного кода. Логично предположить, что мы имеем дело в последней операцией OR в цепочке сравнений – это ее "почерк". Значит, мы инвертируем условие выражения и продолжаем писать: "if ((a==b) || (a==c)…)". Последний бастион – проверка условия "a==0". Выполнить условный код, миновав его не удаться, - следовательно, это не OR, а AND! А AND
всегда инвертирует условие срабатывания, и поэтому, оригинальный код должен был выглядеть так: "if ((a==b) || (a==c) && (a!=0))". Ура! У нас получилось!
Впрочем, как любил поговаривать Дмитрий Николаевич, не обольщайтесь – то, что мы рассмотрели – это простейший пример. В реальной жизни оптимизирующие компиляторы такого понаворочают….
___Впрочем, для ломания головы вполне хватит и не оптимизирующих, но прежде, чем перейти к изучению конкретных реализаций, рассмотрим на последок две "редкоземельные" операции NOT и XOR.
__NOT – одноместная операция, поэтому, она не может использоваться для связывания, однако,
Наглядное представление сложных условий в виде дерева. Конструкцию, состоящую из трех – четырех элементарных условий, можно проанализировать и в уме (да и то, если есть соответствующие навыки), но хитросплетения пяти и более условий образуют самый настоящий лабиринт – его с лету не возьмешь. Неоднозначность трансляции сложных условий порождает неоднозначность интерпретации, что приводит к многовариантному анализу, причем с каждым шагом в голове приходится держать все больше и больше информации. Так недолго и крышей поехать или окончательно запутаться и получить неверных результат.
Выход – в использовании двухуровневой системы ретрансляции. На первом этапе элементарные условия преобразуются к некоторой промежуточной форме записи, наглядно и непротиворечиво отображающей взаимосвязь элементарных операций. Затем осуществляется окончательная трансляция в любую подходящую нотацию (например, Си, Бейсик или Pascal).
Единственная проблема – выбрать удачную промежуточную форму. Существует множество решений, но в книге по соображениям экономии бумажного пространства, мы рассмотрим только одно – деревья.
Изобразим каждое элементарное условие в виде узла, с двумя ветвями, соответствующим состояниям: условие истинно и условие ложно. Для наглядности обозначим "ложь" равнобедренным треугольником, а "истину" – квадратом и условимся всегда располагать ложь на левой, а истину на правой ветке. Получившуюся конструкцию назовем "гнездом" (nest).
Рисунок 22 0х015 Схематическое представление гнезда (nest).
Гнезда могут объединяться в деревья, соединясь узлами с ветками другого узла. Причем, каждый узел может соединяться только с одним гнездом, но всякое гнездо может соединяться с несколькими узлами. Непонятно? Не волнуйтесь, сейчас со всем этим мы самым внимательным образом разберемся.
Рассмотрим объединение двух элементарных условий логической операцией "AND" на примере выражения "((a==b) && (a!=0))".
Извлекаем первое слева условие (a==b), "усаживаем" его в гнездо с двумя ветвями: левая соответствует случаю, когда a!=b
(т.е. условие a==b – ложно), а правая, соответственно, – наоборот. Затем, то же самое делаем и со вторым условием (a!=0). У нас получаются два очень симпатичных гнездышка, – остается лишь связать их меж собой операцией логического "AND". Как известно, "AND" выполняет второе условие только в том случае, если истинно первое. Значит, гнездо (a!=0) следует прицепить к правой ветке гнезда (a==b). Тогда – правая ветка гнезда (a!=0) будет соответствовать истинности выражения "((a==b) && (a!=0))", а обе левые ветки – его ложности. Обозначим первую ситуацию меткой "do_it", а вторую – "continue". В результате дерево должно принять вид, изображенный на рис. 23.
Для наглядности отметим маршрут из вершины дерева к метке "do_it" жирной красной стрелкой. Как видите, в пункт "do_it" можно попасть только одним путем. Вот так графически выглядит операция "AND".
Рисунок 23 0х016 Графическое представление операции AND в виде двоичного дерева. Обратите внимание – в пункт do_it можно попасть только одним путем!
Перейдем теперь к операции логического "OR". Рассмотрим конструкцию "((a==b) || (a!=0))". Если условие "(a==b)" истинно, то и все выражение считается истинным. Следовательно, правая ветка гнезда "(a==b)" связана с меткой "do_it". Если же условие же "(a==b)" ложно, то выполняется проверка следующего условия. Значит, левая ветка гнезда "(a==b)" связана с гнездом "(a!=b)". Очевидно, если условие "(a!=b)" истинно, то истинно и все выражение "((a==b) || (a!=0))", напротив, если условие "(a!=b)" ложно, то ложно и все выражение, т.к. проверка условия "(a!=b)" выполняется только в том случае, если условие "(a==b)" ложно.
Отсюда мы заключаем, что левая ветка гнезда "(a!=b)" связана с меткой "continue", а правая – с "do_it". (см. рис. 24). Обратите внимание – в пункт "do_it" можно попасть двумя различными путями! Вот так графически выглядит операция "OR".
Рисунок 24 0х017 Графическое представление операции OR в виде двоичного дерева. Обратите внимание – в пункт do_it можно попасть двумя различными путями!
До сих пор мы отображали логические операции на деревья, но ведь деревья создавались как раз для противоположной цели – преобразованию последовательности элементарных условий к интуитивно понятному представлению. Займемся этим? Пусть в тексте программы встретится следующий код:
IF a==b THEN check_null
IF a!=c THEN continue
check_null:
IF a==0 THEN continue
…// код условия
continue:
…// прочий код
Листинг 150
Извлекаем условие (a==b) и сажаем его в "гнездо", - смотрим: если оно ложно, то выполняется проверка (a!=c), значит, гнездо (a!=c) связано с левой веткой гнезда (a==b). Если же условие (a==b) истинно, то управление передается метке check_null, проверяющей истинность условия (a==0), следовательно, гнездо (a==0) связано с правой веткой гнезда (a==b). В свою очередь, если условие (a!=с) истинно, управление получает метка "continue", в противном случае – "check_null". Значит, гнездо (a!=0) связано одновременно и с правой веткой гнезда (a==b) и с левой веткой гнезда (a!=c).
Конечно, это проще рисовать, чем описывать! Если вы все правильно зарисовали, у вас должно получится дерево очень похожее на изображенное на рисунке 25.
Смотрите: к гнезду "(a==0)" можно попасть двумя путями – либо через гнездо (a==b), либо через цепочку двух гнезд (a==b) à
(a!=c). Следовательно, эти гнезда связаны операцией OR. Записываем: "if ( (a==b) || !(a!=c)….)". Откуда взялся NOT? Так ведь гнездо (a==0) связано с левой веткой гнезда (a!=с), т.е. проверяется ложность его истинности! (Кстати, "ложность истинности" – очень хорошо звучит).
Избавляемся от NOT, инвертируя условие: "if ( (a==b) || (a==c)….)…". Далее – из гнезда (a==0) до пункта do_it
можно добраться только одним путем, значит, оно связано операцией AND. Записываем: "if (((a==b) || (a==c)) && !(a==0))…". Теперь избавляемся от лишних скобок и операции NOT. В результате получается: "if ((a==b) || (a==c) && (a!=0)) {// Код условия}"
Не правда ли все просто? Причем вовсе необязательно строить деревья вручную, - при желании можно написать программу, берущую эту работу на себя.
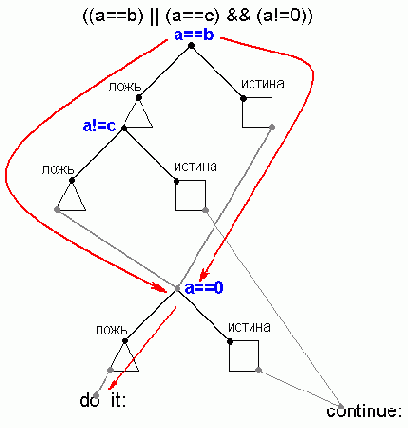
Рисунок 25 0х018 Графическое представление сложного выражения
Исследование конкретных реализаций.
Прежде чем приступать к отображению конструкции "IF (сложное условие) THEN
оператор1:оперратор2 ELSE
оператора:операторb" на машинный язык, вспомним, что, во-первых, агрегат "IF – THEN – ELSE" можно выразить через "IF – THEN", во-вторых, "THEN оператор1:оперратор2" можно выразить через "THEN GOTO do_it", в-третьих, любое сложное условие можно свести к последовательности элементарных условий отношения. Таким образом, на низком уровне мы будем иметь дело лишь с конструкциями "IF (простое условие отношения) THEN GOTO do_it", а уже из них, как из кирпичиков, можно сложить что угодно.
Итак, условия отношения, или другими словами, результат операции сравнения двух чисел. В микропроцессорах Intel 80x86 сравнение целочисленных значений осуществляется командой CMP, а вещественных – одной из следующих инструкций сопроцессора: FCOM, FCOMP, FCOMPP, FCOMI, FCOMIP, FUCOMI, FUCOMIP. Предполагается, что читатель уже знаком с языком ассемблера, поэтому не будем подробно останавливаться на этих инструкциях и рассмотрим их лишь вкратце.
::CMP. Команда CMP эквивалентна операции целочисленного вычитания SUB, за одним исключением – в отличие от SUB, CMP
не изменяет операндов, а воздействует лишь на флаги основного процессора: флаг нуля, флаг переноса, флаг знака
и флаг переполнения.
Флаг нуля
устанавливается в единицу, если результат вычитания равен нулю, т.е. операнды равны друг другу.
Флаг переноса
устанавливается в единицу, если в процессе вычитания произошел заем из старшего бита уменьшаемого операнда, т.е. уменьшаемое меньше вычитаемого.
Флаг знака равен старшему – знаковому – биту результата вычислений, т.е. результат вычислений – отрицательное число.
Флаг переполнения устанавливается в единицу, если в результате вычислений "залез" в старший бит, приводя к потере знака числа.
Для проверки состояния флагов существует множество команд условных переходов, выполняющихся в случае, если определенный флаг (набор флагов) установлен (сброшен). Инструкции, использующиеся для анализа результата сравнения целых чисел, перечислены в таблице 16.
В общем случае конструкция "IF (элементарное условие отношения) THEN do_it" транслируется в следующие команды процессора:
CMP A,B
Jxx do_it
continue:
__Однако шаблон "CMP/Jxx" не
Между инструкциями "CMP" и "Jxx" могут находиться и другие команды, не изменяющие флагов процессора, например "MOV", "LEA".
__синонимы
|
условие |
состояние флагов |
инструкция |
||||||
|
Zero flag |
Carry Flag |
Sing Flag |
||||||
|
a == b |
1 |
? |
? |
JZ |
JE |
|||
|
a != b |
0 |
? |
? |
JNZ |
JNE |
|||
|
a < b |
беззнаковое |
? |
1 |
? |
JC |
JB |
JNAE |
|
|
знаковое |
? |
? |
!=OF |
JL |
JNGE |
|||
|
a > b |
беззнаковое |
0 |
0 |
? |
JA |
JNBE |
||
|
знаковое |
0 |
? |
==OF |
JG |
JNLE |
|||
|
a >=b |
беззнаковое |
? |
0 |
? |
JAE |
JNB |
JNC |
|
|
знаковое |
? |
? |
==OF |
JGE |
JNL |
|||
|
a <= b |
беззнаковое |
(ZF == 1) || (CF == 1) |
? |
JBE |
JNA |
|||
|
знаковое |
1 |
? |
!=OF |
JLE |
JNG |
::сравнение вещественных чисел. Команды сравнения вещественных чисел FCOMxx
(см. таблицу 18) в отличие от команд целочисленного сравнения воздействуют на регистры сопроцессора, а не основного процессора. На первый взгляд – логично, но весь камень преткновения в том, что инструкций условного перехода, управляемых флагами сопроцессора, не существует! К тому же, флаги сопроцессора непосредственно недоступны, - чтобы прочитать их статус необходимо выгрузить регистр состояния сопроцессора SW
в память или регистр общего назначения основного процессора.
Хуже всего – анализировать флаги вручную! Если при сравнении целых чисел можно и не задумываться: какими именно флагами управляется условный переход, достаточно написать, скажем: "CMP A,B; JGE do_it". ("Jump [if] Great [or] Equal" – прыжок, если A
больше или равно B), то теперь этот номер не пройдет! Правда, можно схитрить и скопировать флаги сопроцессора в регистр флагов основного процессора, а затем использовать "родные" инструкции условного перехода из серии Jxx.
Конечно, непосредственно скопировать флаги из сопроцессора в основной процессор нельзя и эту операцию приходится осуществлять в два этапа. Сначала флаги FPU выгружать в память или регистр общего назначения, а уже оттуда заталкивать в регистр флагов CPU. Непосредственно модифицировать регистр флагов CPU умеет только одна команда – POPF. Остается только выяснить – каким флагам сопроцессора, какие флаги процессора соответствуют. И вот что удивительно – флаги 8й, 10й и 14й сопроцессора совпадают с 0ым, 2ым и 6ым флагами процессора – CF, PF и ZF соответственно (см. таблицу 17). То есть – старшей байт регистра флагов сопроцессора можно безо всяких преобразований затолкать в младший байт регистра флагов процессора и это будет работать, но… при этом исказятся 1й, 3й и 5й биты флагов CPU, никак не используемые в текущих версиях процессора, но зарезервированные на будущее. Менять значение зарезервированных битов нельзя! Кто знает, вдруг завтра один из них будут отвечать за самоуничтожение процессора? Шутка, конечно, но в ней есть своя доля истины.
К счастью, никаких сложных манипуляций нам проделывать не придется – разработчики процессора предусмотрели специальную команду – SAHF, копирующую 8й, 10й, 12й, 14й и 15й бит регистра AX в 0й, 2й, 4й, 6й и 7й бит регистра флагов CPU соответственно. Сверяясь по таблице 17 мы видим, что 7й бит регистра флагов CPU содержит флаг знака, а соответствующий ему флаг FPU – признак занятости сопроцессора!
Отсюда следует, что для анализа результата сравнения вещественных чисел использовать знаковые условные переходы(JL, JG, JLE, JNL, JNLE, JGE, JNGE) нельзя! Они работают с флагами знака и переполнения, – естественно, если вместо флага знака им подсовывают флаг занятости сопроцессора, а флаг переполнения оставляют в "подвешенном" состоянии, условный переход будет срабатывать не так, как вам бы этого хотелось! Применяйте лишь беззнаковые инструкции перехода – JE, JB, JA
и др. (см. таблицу 16)
Разумеется, это не означает, что сравнивать знаковые вещественные значения нельзя, - можно, еще как! Но для анализа результатов сравнения обязательно всегда использовать только беззнаковые условные переходы!
|
CPU |
7 |
6 |
5 |
4 |
3 |
2 |
1 |
0 |
|
SF |
ZF |
-- |
AF |
-- |
PC |
-- |
CF |
|
|
FPU |
15 |
14 |
13 |
12 |
11 |
10 |
9 |
8 |
|
Busy! |
C3(ZF) |
TOP |
C2(PF) |
C1 |
C0(CF) |
Таким образом, вещественная конструкция "IF (элементарное условие отношения) THEN do_it" транслируется в одну из двух следующих последовательностей инструкций процессора:
fld [a] fld [a]
fcomp [b] fcomp [b]
fnstsw ax fnstsw ax
sahf test ah, bit_mask
jxx do_it jnz do_it
Листинг 151
Первый вариант более нагляден, зато второй работает быстрее. Однако, такой код (из всех известных мне компиляторов) умеет генерировать один лишь Microsoft Visual C++.
Borland C++ и хваленый WATCOM C испытывают неопределимую тягу к инструкции SAHF, чем вызывают небольшие тормоза, но чрезвычайно упрощают анализ кода, - ибо, встретив команду наподобие JNA, мы и спросонок скажем, что переход выполняется когда a <= b, а вот проверка битвой маски "TEST AH, 0x41/JNZ do_it" заставит нас крепко задуматься или машинально потянуться к справочнику за разъяснениями (см. таблицу 16)
Команды семейства FUCOMIxx в этом смысле гораздо удобнее в обращении, т.к. возвращают результат сравнения непосредственно в регистры основного процессора, но – увы – их "понимает" только Pentium Pro, а в более ранних микропроцессорах они отсутствуют. Поэтому, вряд ли читателю доведется встретиться с ними в реальных программах, так что не имеет никакого смысла останавливаться на этом вопросе. Во всяком случае, всегда можно обратится к странице 3-112 руководства "Instruction Set Reference", где эти команды подробно описаны.
|
инструкция |
назначение |
результат |
|
FCOM |
Сравнивает вещественное значение, находящееся на вершине стека сопроцессора, с операндом, находящимся в памяти или стеке FPU |
флаги FPU |
|
FCOMP |
То же самое, что и FCOM, но с выталкиванием вещественного значения с вершины стека |
|
|
FCOMPP |
Сравнивает два вещественных значения, лежащих на вершине стека сопроцессора, затем выталкивает их из стека |
|
|
FCOMI |
Сравнивает вещественное значение, находящееся на вершине стека сопроцессора с другим вещественным значением, находящимся в стеке FPU |
флаги CPU |
|
FCOMIP |
Сравнивает вещественное значение, находящееся на вершине стека сопроцессора с другим вещественным значением, находящимся в стеке FPU, затем выталкивает верхнее значение из стека |
|
|
FUCOMI |
Неупорядоченно сравнивает вещественное значение, находящееся на вершине стека сопроцессора с другим вещественным значением, находящимся в стеке FPU |
|
|
FUCOMIP |
Неупорядоченно сравнивает вещественное значение, находящееся на вершине стека сопроцессора с другим вещественным значением, находящимся в стеке FPU, затем выталкивает верхнее значение из стека |
Таблица 18 Команды сравнения вещественных значений
|
флаги FPU |
назначение |
битовая маска |
|
|
OE |
Флаг переполнения |
Overfull Flag |
#0x0008 |
|
C0 |
Флаг переноса |
Carry Flag |
#0x0100 |
|
C1 |
--- |
#0x0200 |
|
|
C2 |
Флаг четности |
Partite Flag |
#0x0400 |
|
C3 |
Флаг нуля |
Zero Flag |
#0x4000 |
|
отношение |
состояние флагов FPU |
SAHF |
битовая маска |
|
|
a<b |
C0 == 1 |
JB |
#0x0100 == 1 |
|
|
a>b |
C0 == 0 |
C3 == 0 |
JNBE |
#0x4100 == 0 |
|
a==b |
C3 == 1 |
JZ |
#0x4000 == 1 |
|
|
a!=b |
C3 == 0 |
JNZ |
#0x4000 == 0 |
|
|
a>=b |
C0 == 0 |
JNB |
#0x0100 == 0 |
|
|
a<=b |
C0 == 1 |
C3 === 1 |
JNA |
#0x4100 == 1 |
|
компилятор |
алгоритм анализа флагов FPU |
|
Borland C++ |
копирует флаги сопроцессора в регистр флагов основного процессора |
|
Microsoft Visual C++ |
тест битовой маски |
|
WATCOM C |
копирует флаги сопроцессора в регистр флагов основного процессора |
|
Free Pascal |
копирует флаги сопроцессора в регистр флагов основного процессора |
Условные команды булевой установки. Начиная с 80386 чипа, язык микропроцессоров Intel обогатился командой условной установки байта – SETxx, устанавливающей свой единственный операнд в единицу (булево TRUE), если условие "xx" равно и, соответственно, сбрасывающую его в нуль (булево FALSE), если условие "xx" – ложно.
Команда "SETxx" широко используются оптимизирующими компиляторами для устранения ветвлений, т.е. избавления от условных переходов, т.к. последние очищают конвейер процессора, чем серьезно снижают производительность программы.
Подробнее об этом рассказывается в главе "Оптимизация ветвлений", здесь же мы не будем останавливаться на этом сложном вопросе. (см.
там же "Булевы сравнения" и "Идентификация условного оператора (условие)?do_it:continue").
|
команда |
отношение |
условие |
|||
|
SETA |
SETNBE |
a>b |
беззнаковое |
CF == 0 && ZF == 0 |
|
|
SETG |
SETNLE |
знаковое |
ZF == 0 && SF == OF |
||
|
SETAE |
SETNC |
SETNB |
a>=b |
беззнаковое |
CF == 0 |
|
SETGE |
SETNL |
знаковое |
SF == OF |
||
|
SETB |
SETC |
SETNAE |
a<b |
беззнаковое |
CF == 1 |
|
SETL |
SETNGE |
знаковое |
SF != OF |
||
|
SETBE |
SETNA |
a<=b |
беззнаковое |
CF == 1 || ZF == 1 |
|
|
SETLE |
SETNG |
знаковое |
ZF == 1 || SF != OF |
||
|
SETE |
SETZ |
a==b |
––– |
ZF == 1 |
|
|
SETNE |
SETNZ |
a!=0 |
––– |
ZF == 0 |
Прочие условные команды. Микропроцессоры серии 80x86 поддерживают множество условных команд, в общем случае не отображающихся на операции отношения, а потому и редко использующиеся компиляторами (можно даже сказать – вообще не использующиеся), но зато часто встречающиеся в ассемблерных вставках. Словом, они заслуживают хотя бы беглого упоминания.
::Команды условного перехода.
Помимо описанных в таблице 16, существует еще восемь других условных переходов – JCXZ, JECXZ, JO, JNO, JP
(он же JPE), JNP
(он же JPO), JS
и JNS. Из них только JCXZ и JECXZ имеют непосредственное отношение к операциям сравнения. Оптимизирующие компиляторы могут заменять конструкцию "CMP [E]CX, 0\JZ do_it" на более короткий эквивалент "J[E]CX do_it", однако, чаще всего они (в силу ограниченности интеллекта и лени своих разработчиков) этого не делают.
Условные переходы JO и JNS
используются в основном в математических библиотеках для обработки чисел большой разрядности (например, 1024 битых целых).
Условные переходы JS и JNS
помимо основного своего предназначения часто используются для быстрой проверки значения старшего бита.
Условные переходы JP и JNP
вообще практически не используются, ну разве что в экзотичных ассемблерных вставках.
|
команда |
переход, если… |
флаги |
|
|
JCXZ |
регистр CX равен нулю |
CX == 0 |
|
|
JECXZ |
регистр ECX равен нулю |
ECX == 0 |
|
|
JO |
переполнение |
OF == 1 |
|
|
JNO |
нет переполнения |
OF == 0 |
|
|
JP |
JPE |
число бит младшего байта результата четно |
PF == 1 |
|
JNP |
JPO |
число бит младшего байта результата нечетно |
PF == 0 |
|
JS |
знаковый бит установлен |
SF == 1 |
|
|
JNS |
знаковый бит сброшен |
SF == 0 |
::Команды условной пересылки.
Старшие процессоры семейства Pentium (Pentium Pro, Pentium II, CLERION) поддерживают команду условной пересылки CMOVxx, пересылающей значение из источника в приемник, если условие xx – истинно. Это позволяет писать намного более эффективный код, не содержащий ветвлений и укладывающийся в меньшее число инструкций.
Рассмотрим конструкцию "IF a<b THEN a=b". Сравните: как она транслируется с использованием условных переходов (1) и команды условной пересылки (2).
CMP A,B CMP A, B
JAE continue: CMOVB A, B
MOV A,B
continue:
1) 2)
Листинг 152
К сожалению, ни один из известных мне компиляторов на момент написания этих строк, никогда не использовал CMOVxx при генерации кода, однако, выигрыш от нее настолько очевиден, что появления усовершенствованных оптимизирующих компиляторов следует ожидать в самом ближайшем будущем. Вот почему эта команда включена в настоящий обзор. В таблице 24 дана ее краткое, но вполне достаточное для дизассемблирования программ, описание. За более подробными разъяснениями обращайтесь к странице 3-59 справочного руководства "Instruction Set Reference" от Intel.
|
команда |
отношение |
условие |
|||
|
CMOVA |
CMOVNBE |
a>b |
беззнаковое |
CF == 0 && ZF == 0 |
|
|
CMOVG |
CMOVNLE |
знаковое |
ZF == 0 && SF == OF |
||
|
CMOVAE |
CMOVNC |
CMOVNB |
a>=b |
беззнаковое |
CF == 0 |
|
CMOVGE |
CMOVNL |
знаковое |
SF == OF |
||
|
CMOVB |
CMOVC |
CMOVNAE |
a<b |
беззнаковое |
CF == 1 |
|
CMOVL |
CMOVNGE |
знаковое |
SF != OF |
||
|
CMOVBE |
CMOVNA |
a<=b |
беззнаковое |
CF == 1 || ZF == 1 |
|
|
CMOVLE |
CMOVNG |
знаковое |
ZF == 1 || SF != OF |
||
|
CMOVE |
CMOVZ |
a==b |
––– |
ZF == 1 |
|
|
CMOVNE |
CMOVNZ |
a!=0 |
––– |
ZF == 0 |
Таблица 24 Основные команды условной пересылки
Булевы сравнения.
Логической лжи (FALSE) соответствует значение ноль, а логической истине (TRUE) – любое ненулевое значение. Таким образом, булевы отношения сводятся к операции сравнения значения переменной с нулем. Конструкция "IF (a) THEN do_it" транслируется в "IF (a!=0) THEN do_it".
Практически все компиляторы заменяют инструкцию "CMP A, 0" более короткой командой "TEST A,A" или "OR A,A". Во всех случаях, если A==0, устанавливается флаг нуля и, соответственно, наоборот.
Поэтому, встретив к дизассемблером тексте конструкцию a la "TEST EAX, EAX\ JZ do_it" можно с уверенностью утверждать, что мы имеем дело с булевым сравнением.
Идентификация условного оператора "(условие)?do_it:continue"
Конструкция "a=(условие)?do_it:continue" языка Си в общем случае транслируется так: "IF (условие) THEN a=do_it ELSE a=continue", однако результат компиляции обоих конструкций вопреки распространенному мнению, не всегда идентичен.
В силу ряда обстоятельств оператор "?" значительно легче поддается оптимизации, чем ветвление "IF – THEN – ELSE". Покажем это на следующем примере:
main()
{
int a; // Переременная специально не иницилизирована
int b; // чтобы компилятор не заменил ее константой
a=(a>0)?1:-1; // Условный оператор
if (b>0) // Ветвление
b=1;
else
b=-1;
return a+b;
}
Листинг 153
Если пропустить эту программу сквозь компилятор Microsoft Visual C++, на выходе мы получим такой код:
push ebp
mov ebp, esp
; Открываем кадр стека
sub esp, 8
; Резервируем место для локальных переменных
; // Условный оператор ?
; Начало условного оператора ?
xor eax, eax
; Обнуляем EAX
cmp [ebp+var_a], 0
; Сравниваем переменную a с нулем
setle al
; Поместить в al значение 0x1, если var_a
<= 0
; Соответственно, поместить в al
значение 0, если var_a>0
dec eax
; Уменьшить EAX на единицу
; Теперь, если var_a
> 0, то EAX
:= -1
; если var_a <=0, то
EAX := 0
and eax, 2
; Сбросить все биты, кроме второго слева, считая от одного
; Теперь, если var_a
> 0, то EAX
:= 2
; если var_a <=0, то
EAX := 0
add eax, 0FFFFFFFFh
; Отнять от EAX 0x1
; Теперь, если var_a
> 0, то EAX
:= 1
; если var_a <=0, то
EAX := -1
mov [ebp+var_a], eax
; Записать результат в переменную var_a
; Конец оператора ?
; Обратите внимание: для трансляции условного оператора не потребовалось ни
; одного условного перехода, - компилятор сумел обойтись без ветвлений!
; // Ветвление
; Начало ветвления IF – THEN - ELSE
cmp [ebp+var_b], 0
; Сравнение переменной var_b
с нулем
jle short else
; Переход, если var_b <= 0
; Ветка "var_b > 0"
mov [ebp+var_b], 1
; Записываем в переменную var_b
значение 1
jmp short continue
; Переход
к метке continue
; Ветка "var_b > 0"
else: ; CODE XREF: _main+1Dj
mov [ebp+var_b], 0FFFFFFFFh
; Записываем в переменную var_b
значение -1
continue: ; CODE XREF: _main+26j
; Конец
ветвления IF-THEN-ELSE
; Обратите внимание – представление ветвления "IF-THEN-ELSE" намного компактнее
; условного оператора "?", однако, содержит в себе условные переходы, ощутимо
; снижающие быстродействие программы
mov eax, [ebp+var_a]
; Загружаем в EAX значение переменной var_a
add eax, [ebp+var_b]
; Складываем значение переменной var_a со значением переменной var_b
; и помещаем результат в EAX
mov esp, ebp
pop ebp
; Закрываем кадр стека
retn
Листинг 154
Таким образом, мы видим, что нельзя апории утверждать, будто бы результат трансляции условного оператора "?" всегда эквивалентен результату трансляции конструкции "IF-THEN-ELSE".
Однако тот же Microsoft Visual C++ в режиме агрессивной оптимизации в обоих случаях генерирует идентичный код. Смотрите:
_main proc near
push ecx
; Резервируем место для локальных переменных a и b
; Поскольку, они никогда не используются вместе, а только поочередно,
; компилятор помещает их в одну ячейку памяти
mov edx, [esp+0] ; команда N1 оператора ?
; Загрузка в EDX значения переменной a
xor eax, eax ; команда N2 оператора ?
; Обнуляем EAX
; Поскольку, команда setle al изменяет содержимое одного лишь al, и не трогает
; остальную часть регистра, нам приходится очищать его самостоятельно
test edx, edx ; команда N3 оператора ?
; Проверка переменной a на равенство нулю
mov edx, [esp+0] ; команда N1 ветвления IF
; Загрузка в EDX значения переменной b
setle al ; команда N4 оператора ?
; Поместить в al значение 0x1, если a <= 0
; Соответственно, поместить в al
значение 0, если a>0
dec eax ; команда N5 оператора ?
; Уменьшить EAX на единицу
; Теперь, если a > 0, то EAX := -1
; если a <=0, то EAX := 0
xor ecx, ecx ; команда N2 ветвления IF
; Обнулить ECX
and eax, 2 ; команда N6 оператора ?
; Сбросить все биты, кроме второго слева, считая от одного
; Теперь, если a > 0, то EAX := 2
; если a <=0, то EAX := 0
dec eax ; команда N7 оператора ?
; Уменьшить EAX на единицу
; Теперь, если a > 0, то EAX := 1
; если a <=0, то EAX := -1
test edx, edx ; команда N3 ветвления IF
; Проверка переменной b на равенство нулю
setle cl ; команда N4 ветвления IF
; Поместить в сl значение 0x1, если b <= 0
; Соответственно, поместить в cl
значение 0, если b>0
dec ecx ; команда N5 ветвления IF
; Уменьшить ECX на единицу
; Теперь, если b > 0, то ECX := -1
; если b <=0, то ECX := 0
and ecx, 2 ; команда N6 ветвления IF
; Сбросить все биты, кроме второго слева, считая от одного
; Теперь, если b > 0, то ECX := 2
; если b <=0, то ECX := 0
dec ecx ; команда N7 ветвления IF
; Уменьшить ECX на единицу
; Теперь, если b > 0, то ECX := -1
; если b <=0, то ECX := 0
add eax, ecx
; Сложить переменную a с переменной b
pop ecx
; Закрыть кадр стека
retn
_main endp
Листинг 155
Компилятор некоторым образом перемешал команды, относящиеся к условному оператору "?", с командами ветвления "IF-THEN-ELSE" (это было сделано для лучшего спаривания инструкций), однако, если их сравнить, то выяснится – реализации обеих конструкций абсолютно идентичны друг другу!
Однако с точки зрения языка условный оператор "?" выгодно отличается от ветвления тем, что может непосредственно использоваться в выражениях, например:
main()
{
int a;
printf("Hello, %s\n", (a>0)?"Sailor":"World!");
}
Листинг 156
Попробуйте так же компактно реализовать это с помощью ветвлений! Но на самом деле, это удобство лишь внешнее, а компилятор транслирует приведенный пример так:
main()
{
int a;
char *p;
static char s0[]="Sailor";
static char s1[]="World";
if (a>0) p=s0; else p=s1;
printf("Hello, %s\n", p);
}
Листинг 157
Откомпилируйте оба листинга и дизассемблируйте полученные файлы, - они должны быть идентичны. Таким образом, при декомпиляции Си/Си++ программ в общем случае невозможно сказать использовалось ли в них ветвление или условный оператор, однако, все же есть некоторые зацепки, помогающие восстановить истинный вид исходного текста в некоторых частных случаях.
Например, маловероятно, чтобы программист строил свой листинг, как показано в последнем примере. Зачем вводить статические переменные и сложным образом манипулировать с указателем, когда проще поступить использовать условный оператор вместо ветвления?
Таким образом, если условный оператор гладко ложиться в декомпилируемую программу, а ветвление не лезет в нее никаким боком, то, очевидно, что в исходном тексте использовался именно условный оператор, а не ветвление.
Идентификация типов. Условные команды – ключ к идентификации типов. Поскольку, анализ результата сравнения знаковых и беззнаковых переменных осуществляется различными группами инструкций, можно уверенно и однозначно отличить signed int от unsigned int.
Вообще же, идентификация типов – тема отдельного разговора, поэтому не будет отклоняться в сторону, а рассмотрим ее чуточку позже в одноименной главе.
(short) переход, адресуемый относительным знаковым смещением, отсчитываемым от начала следующий за инструкцией перехода командой (см. рис 26). Такая схема адресации ограничивает длину прыжка "вперед" (т.е. "вниз") всего 128 байтами, а "назад" (т.е. "вверх") и того меньше – 127! (Прыжок вперед короче потому, что ему требуется "пересечь" и саму команду перехода). Этих ограничений лишен ближний
(near) безусловный переход, адресуемый двумя байтами и действующий в пределах всего сегмента.
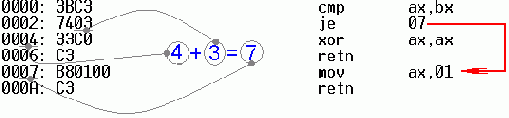
Рисунок 26 0х019 Внутреннее представление короткого (short) перехода
Короткие переходы усложняют трансляцию ветвлений – ведь не всякий целевой адрес находится в пределах 128 байт! Существует множество путей обойти это ограничение.
Наиболее популярен следующий примем: если транслятор видит, что целевой адрес выходит за пределы досягаемости условного перехода, он инвертирует условие срабатывания и совершает короткий (short) переход на метку continue, а на do_it передает управление ближним (near) переходом, действующим в пределах одного сегмента (см. рис. 27)
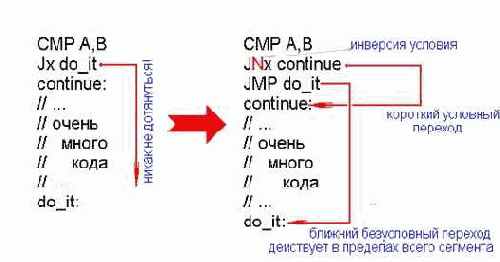
Рисунок 27 0х01A Трансляция коротких переходов
Аналогичным образом можно выкрутиться и в тех ситуациях, когда целевой адрес расположен совсем в другом сегменте – достаточно лишь заменить ближний безусловный переход на дальний. Вот, собственно, и все.
К великому счастью разработчиков компиляторов и не меньшей радости хакеров, дизассемблирующих программы, в 32-разрядном режиме условный переход "бьет" в пределах всего четырех гигабайтного адресного пространства и все эти проблемы исчезают, как бородавки после сеанса Кашпировского.
Листинги примеров. А теперь для лучшего уяснения материала, рассмотренного в этой главе, давайте рассмотрим несколько "живых" примеров, откомпилированных различными компиляторами. Начнем с исследования элементарных целочисленных отношений:
#include <stdio.h>
main()
{
int a; int b;
if (a<b) printf("a<b");
if (a>b) printf("a>b");
if (a==b) printf("a==b");
if (a!=b) printf("a!=b");
if (a>=b) printf("a>=b");
if (a<=b) printf("a<=b");
}
Листинг 158
Результат компиляции этого примера компилятором Microsoft Visual C+ должен выглядеть так:
main proc near ; CODE XREF: start+AFp
var_b = dword ptr -8
var_a = dword ptr -4
push ebp
mov ebp, esp
; Открываем кадр стека
sub esp, 8
; Резервируем память для локальных переменных var_a и var_b
mov eax, [ebp+var_a]
; Загружаем в EAX значение переменной var_a
cmp eax, [ebp+var_b]
; Сравниваем значение переменной var_a со значением переменной var_b
jge short loc_40101B
; Если var_a
>= var_b то переход на continue иначе – печать строки
; Обратите внимание, что оригинальный код выглядел так:
; if (a<b) printf("a<b");
; Т.е. условие отношения было инвентировано компилятором!
; Знаковая операция JGE говорит о том, что и сравнивыемые переменные
; var_a и var_b
– так же знаковые
; // ВЕТКА DO_IT
push offset aAB_4 ; "a<b"
call _printf
add esp, 4
; Печать строки "a<b"
; // ВЕТКА CONTINUE
loc_40101B: ; CODE XREF: main+Cj
mov ecx, [ebp+var_a]
; Загружаем в ECX значение переменной var_a
cmp ecx, [ebp+var_b]
; Сравниваем значение переменной var_a с переменной var_b
jle short loc_401030
; Переход, если var_a
<= var_b, иначе – печать строки
; Следовательно, строка печатается, когда !(var_a <= var_b), или
; var_a > var_b. Тогда исходный код программы должен выглядеть так:
; if (a>b) printf("a>b");
push offset aAB_3 ; "a>b"
call _printf
add esp, 4
;
loc_401030: ; CODE XREF: main+21j
mov edx, [ebp+var_a]
; Загружаем в EDX значение переменной var_a
cmp edx, [ebp+var_b]
; Сравниваем значение переменной var_a с переменной var_b
jnz short loc_401045
; Переход если var_a!=var_b, иначе печать строки
; Следовательно, оригинальный код программы выглядел так:
; if (a==b) printf("a==b");
push offset aAB ; "a==b"
call _printf
add esp, 4
loc_401045: ; CODE XREF: main+36j
mov eax, [ebp+var_a]
; Загружаем в EAX значение переменной var_a
cmp eax, [ebp+var_b]
; Сравниваем значение переменной var_a со значением переменной var_b
jz short loc_40105A
; Переход, если var_a==var_b, иначе – печать строки.
; Следовательно, оригинальный код программы выглядел так:
; if (a!==b) printf("a!=b");
push offset aAB_0 ; "a!=b"
call _printf
add esp, 4
loc_40105A: ; CODE XREF: main+4Bj
mov ecx, [ebp+var_a]
; Загружаем в ECX значение переменной var_a
cmp ecx, [ebp+var_b]
; Сравниваем значение переменной var_a с переменной var_b
jl short loc_40106F
; Переход, если var_a
< var_b, иначе – печать строки
; Следовательно, оригинальный код программы выглядел так:
; if (a>=b) printf("a>=b");
push offset aAB_1 ; "a>=b"
call _printf
add esp, 4
loc_40106F: ; CODE XREF: main+60j
mov edx, [ebp+var_a]
; Загружаем в EDX значение переменной var_a
cmp edx, [ebp+var_b]
; Сравниваем значение переменной var_a с переменной var_b
jg short loc_401084
; Переход если var_a>var_b, иначе печать строки
; Следовательно, оригинальный код программы выглядел так:
; if (a<=b) printf("a<=b");
push offset aAB_2 ; "a<=b"
call _printf
add esp, 4
loc_401084: ; CODE XREF: main+75j
mov esp, ebp
pop ebp
; Закрываем кадр стека
retn
main endp
Листинг 159
А теперь сравним этот, 32-разрядный код, с 16- разрядным кодом, сгенерированном компилятором Microsoft C++ 7.0 (ниже, для экономии места приведен лишь фрагмент):
mov ax, [bp+var_a]
; Загрузить в AX
значение переменной var_a
cmp [bp+var_b], ax
; Сравнить значение переменной var_a
со значением переменной var_b
jl loc_10046
; Переход на код печати строки, если var_a
< var_b
jmp loc_10050
; Безусловный переход на continue
; Смотрите! Компилятор, не будучи уверен, что "дальнобойности" короткого
; условного перехода хватит для достижения метки continue, вместо этого
; прыгнул на метку do_it, расположенную неподалеку – в гарантированной
; досягаемости, а передачу управления на continue взял на себя
; безусловный переход
; Таким образом, инверсия истинности условия сравнения имело место дважды
; первый раз при трансляции условия отношения, второй раз – при генерации
; машинного кода. А NOT
на NOT
можно сократить!
; Следовательно, оригинальный код выглядел так:
; if (a<b) printf("a<b");
loc_10046: ; CODE XREF: _main+11j
mov ax, offset aAB ; "a<b"
push ax
call _printf
add sp, 2
loc_10050: ; CODE XREF: _main+13j
; // прочий код
Листинг 160
А теперь заменим тип сравниваемых переменных с int на float и посмотрим, как это повлияет на сгенерированный код. Результат компиляции Microsoft Visual C++ должен выглядеть так (ниже приведен лишь фрагмент):
fld [ebp+var_a]
; Загрузка значения вещественной переменной var_a на вершину стека сопроцессора
fcomp [ebp+var_b]
; Сравнение значение переменной var_a с переменной var_b
; с сохранением результата сравнения во флагах сопроцессора
fnstsw ax
; Скопировать регистр флагов сопроцессора в регистр AX
test ah, 1
; Нулевой бит регистра AH установлен?
; Соответственно: восьмой бит регистра флагов сопроцессора установлен?
; А что у нас храниться в восьмом бите?
; Ага, восьмой бит содержит флаг переноса.
jz short loc_20
; Переход, если флаг переноса сброшен, т.е. это равносильно конструкции jnc
; при сравнении целочисленных значений. Смотрим по таблице 16 – синоним jnc
; команда jnb.
; Следовательно, оригинальный код выглядел так:
; if (a<b) printf("a<b");
push offset $SG339 ; "a<b"
call _printf
add esp, 4
loc_20: ; CODE XREF: _main+11j
Листинг 161
Гораздо нагляднее код, сгенерированный компилятором Borland C++ или WATCOM C. Смотрите:
fld [ebp+var_a]
; Загрузка значения вещественной переменной var_a на вершину стека сопроцессора
fcomp [ebp+var_b]
; Сравнение значение переменной var_a с переменной var_b
; с сохранением результата сравнения во флагах сопроцессора
fnstsw ax
; Скопировать регистр флагов сопроцессора в регистр AX
sahf
; Скопировать соответствующие биты регистра AH во флаги основного процессора
jnb short loc_1003C
; Переход, если !(a<b), иначе печать строки printf("a<b")
; Теперь, не копаясь ни в каких справочных таблицах, можно восстановить
; оригинальный
код:
; if (a<b) printf("a<b");
push offset unk_100B0 ; format
call _printf
pop ecx
loc_1003C: ; CODE XREF: _main+Fj
Листинг 162
Теперь, "насобачившись" на идентификации элементарных условий, перейдем к вещам по настоящему сложным. Рассмотрим следующий пример:
#include <stdio.h>
main()
{
unsigned int a; unsigned int b; int c; int d;
if (d) printf("TRUE"); else if (((a>b) && (a!=0)) || ((a==c) && (c!=0))) printf("OK\n");
if (c==d) printf("+++\n");
}
Листинг 163
Результат его компиляции должен выглядеть приблизительно так:
_main proc near
var_d = dword ptr -10h
var_C = dword ptr -0Ch
var_b = dword ptr -8
var_a = dword ptr -4
push ebp
mov ebp, esp
; Открытие кадра стека
sub esp, 10h
; Резервирование места для локальный переменных
cmp [ebp+var_d], 0
; Сравнение значение переменной var_d с нулем
jz short loc_1B
; Если переменная var_d
равна нулю, переход к метке loc_1B, иначе
; печать строки TRUE. Схематически это можно изобразить так:
; var_d == 0
; / \
; loc_1B printf("TRUE");
push offset $SG341 ; "TRUE"
call _printf
add esp, 4
jmp short loc_44
; "Ага", говорим мы голосом Пяточка, искушающего Кенгу!
; Вносим этот условный переход в наше дерево
;
; var_d == 0
; / \
; loc_1B printf("TRUE");
; |
; loc_44
loc_1B: ; CODE XREF: _main+Aj
mov eax, [ebp+var_a]
; Загружаем в EAX значение переменной var_a
cmp eax, [ebp+var_b]
; Сравниваем переменную var_a с переменной var_b
jbe short loc_29
; Если var_a
меньше или равна переменной var_b, то переход на loc_29
; Прививаем новое гнездо к нашему дереву, попутно обращая внимание не то, что
; var_a и var_b
– беззнаковые переменные!
;
; var_d == 0
; / \
; loc_1B printf("TRUE");
; | |
; var_a <= var_b loc_44
; / \
; continue loc_29
cmp [ebp+var_a], 0
; Сравниваем значение переменной var_a с нулем
jnz short loc_37
; Переход на loc_37, если var_a
не равна нулю
;
; var_d == 0
; / \
; loc_1B printf("TRUE");
; | |
; var_a <= var_b loc_44
; / \
; var_a !=0 loc_29
; / \
; continue loc_37
loc_29: ; CODE XREF: _main+21j
; Смотрите – в нашем дереве уже есть метка loc_29! Корректируем его!
;
; var_d
== 0
; / \
; loc_1B printf("TRUE");
; | |
; var_a <= var_b loc_44
; / \
; var_a !=0 loc_29
; / \ |
; | | |
; \ loc_37 |
; \ |
; \------------------+
mov ecx, [ebp+var_a]
; Загружаем в ECX значение переменной var_a
cmp ecx, [ebp+var_C]
; Сравниваем значение переменной var_a с переменной var_C
jnz short loc_44
; переход, если var_a != var_C
;
; var_d == 0
; / \
; loc_1B printf("TRUE");
; | |
; var_a <= var_b loc_44
; / \
; var_a !=0 loc_29
; / \ |
; | | |
; \ loc_37 |
; \ |
; \------------------+
; |
; var_a != var_C
; / \
; continue loc_44
cmp [ebp+var_C], 0
; Сравнение значения переменной var_C с нулем
jz short loc_44
; Переход на loc_44 если var_C
== 0
;
; var_d == 0
; / \
; loc_1B printf("TRUE");
; | |
; var_a <= var_b loc_44
; / \ |
; var_a !=0 loc_29 |
; / \ | |
; | | | |
; \ loc_37 | |
; \ | |
; \------------------+ |
; | |
; var_a != var_C |
; / \ /
; var_C == 0 | /
; / \ | /
; continue \-----------+--/
; |
; loc_44
loc_37: ; CODE XREF: _main+27j
; Смотрим – метка loc_37 уже есть в дереве! Прививаем!
;
; var_d
== 0
; / \
; loc_1B printf("TRUE");
; | |
; var_a <= var_b loc_44
; / \ |
; var_a !=0 loc_29 |
; / \ | |
; | \ | |
; \ \-----à | ß--------!
; \ | | !
; \------------------+ / !
; | / !
; var_a != var_C / !
; / \ / !
; var_C == 0 | !
; / \ | !
; ! \-----------+ !
; ! | !
; ! ! !
; \---------------------------------!------!
; ! !
; loc_44 loc_37
; |
; printf("OK");
push offset $SG346 ; "OK\n"
call _printf
add esp, 4
loc_44: ; CODE XREF: _main+19j _main+2Fj ...
; Смотрите – ветки loc_44 и loc_37 смыкаются!
;
; var_d == 0
; / \
; loc_1B printf("TRUE");
; | |
; var_a <= var_b loc_44
; / \ |
; var_a !=0 loc_29 |
; / \ | |
; | \ | |
; \ \-----à | ß--------!
; \ | | !
; \------------------+ / !
; | / !
; var_a != var_C / !
; / \ / !
; var_C == 0 \| !
; / \ | !
; ! \-----------+ !
; ! | !
; ! ! !
; \---------------------------------!------!
; ! !
; loc_44 loc_37
; | |
; | printf("OK");
; | |
; \-------+-------/
; |
; |
mov edx, [ebp+var_C]
; Загружаем в EDX значение переменной var_C
cmp edx, [ebp+var_d]
; Сравниваем значение var_C
со значением переменной var_D
jnz short loc_59
; Переход, если var_C
!= var_D
push offset $SG348 ; "+++\n"
call _printf
add esp, 4
; var_d == 0
; / \
; loc_1B printf("TRUE");
; | |
; var_a <= var_b loc_44
; / \ |
; var_a !=0 loc_29 |
; / \ | |
; | \ | |
; \ \-----à | ß--------!
; \ | | !
; \------------------+ / !
; | / !
; var_a != var_C / !
; / \ / !
; var_C == 0 | !
; / \ | !
; ! \-----------+ !
; ! | !
; ! ! !
; \---------------------------------!------!
; ! !
; loc_44 loc_37
; | |
; | printf("OK");
; | |
; \-------+-------/
; |
; |
; var_C != var_D
; / \
; printf("+++") !
; конец
loc_59: ; CODE XREF: _main+4Aj
mov esp, ebp
pop ebp
retn
_main endp
Листинг 164
В итоге вырастает огромное разлапистое дерево, в котором на первый взгляд просто невозможно разобраться. Но, как говориться, глаза страшатся, а руки делают. Первым делом, оптимизируем дерево: избавимся от "перекрученных" ветвей, инвертировав условие в гнезде, и выкинем все метки – теперь, когда скелет дерева построен, они уже не нужны. Если все сделать правильно, дерево должен выглядеть так:
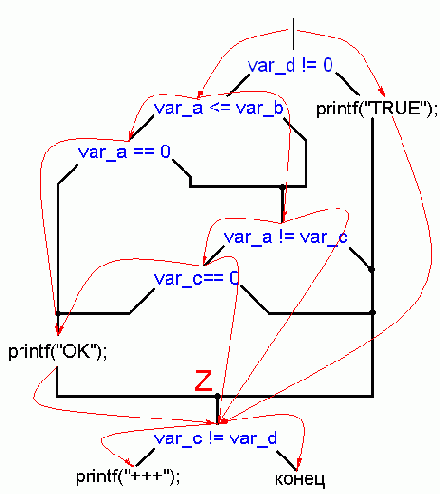
Рисунок 28 0х01В Логическое древо
Сразу же бросается в глаза, что все пути проходят точку "Z", сплетающую все ветви воедино. Это значит, что мы имеем дело с двумя
самостоятельными деревьями, представленными собственными конструкциями "IF". Замечательно! Такой поворот событий весьма упрощает анализ – раз деревья независимые, то и анализироваться они могут независимо! Итак, начинаем с верхнего из них….
От гнезда "var_d !=0" отходят две ветки – правая ведет к "printf("OK")" и далее к завершению конструкции "IF – THEN [ELSE]", а левая, прежде чем выйти к точке "Z", минует целое полчище гнезд.
В переводе на русский язык ситуация выглядит так: "если переменная var_d не равна нулю, то печатаем "OK" и сваливаем, иначе выполняем дополнительные проверки". Проще говоря: "IF (var_d !=0) THEN printf("OK") ELSE …". Т.е. левая ветка гнезда (var_d != 0) есть ветка "ELSE". Изучим ее?
От гнезда (var_a <= var_b) к узлу "printf("OK")" ведут два пути: !(var_a <= var_b) à !(var_a ==0 )
и !(var_a != var_c) à !(var_c == 0). Где есть альтернатива – там всегда есть OR. Т.е. либо первый путь, либо второй. В то же время, узлы обоих путей последовательно связаны друг с другом, - значит, они объедены операций AND. Таким, образом, эта ветка должна выглядеть так: "IF (( var_a > var_b) && (var_0 != 0)) || (var_a == var_c) && (var_c != 0)) printf("OK")", прививаем "ELSE" к первому IF и получаем. "IF (var_d !=0) THEN printf("OK") ELSE IF(( var_a > var_b) && (var_0 != 0)) || (var_a == var_c) && (var_c != 0)) printf("OK")"
Ну, а разбор второго дерева вообще тривиален: "IF (var_c==var_d) printf("+++")". Итак, исходный текст дизассемблируемой программы выглядел так:
u_int a; u_int b; ?_int c; ?_int d;
if (d) printf("TRUE");
else
if (((a>b) && (a!=0)) || ((a==c) && (c!=0))) printf("OK\n");
if (c==d) printf("+++\n");
Листинг 165
Тип переменных a и b мы определили как unsigned int, т.к. они результат сравнения анализировался беззнаковой условной командой – jnb. А вот тип переменных c и d, увы, определить так и не удалось. Однако это не умоляет значимости того факта, что мы смогли ретранслировать сложное условие, в котором без деревьев было бы немудрено и запутаться…
- Больше всего следует опасаться идей, которые переходят в дела.
Френк Херберт "Мессия дюны"
Оптимизация ветвлений: Какое коварство – под флагом оптимизации сделать каждую строчку кода головоломкой.
Тьфу-ты, тут ящика пива не хватит, чтобы с этим справиться (а с этим лучше справляться вообще без пива – на трезвую голову). Итак, предположим, встретился вам код следующего содержания. На всякий случай, чтобы избавить вас от копания по справочникам (хотя, покопаться в них лишний раз – только на пользу) отмечу, что команда SETGE устанавливает выходной операнд в 1, если флаги состояния SF и OF равны (т.е. SF==OF). Иначе выходной операнд устанавливается в ноль.
mov eax, [var_A]
xor ecx,ecx
cmp eax, 0x666
setge cl
dec ecx
and ecx, 0xFFFFFC00
add ecx, 0x300
mov [var_zzz],ecx
Листинг 166
На первый взгляд этот фрагмент заимствован из какого-то хитро-запутанного защитного механизма, но нет. Перед вами результат компиляции следующего тривиального выражения: if (a<0x666) zzz=0x200 else zzz=0x300, которое в не оптимизированном виде выглядит так:
mov eax,[var_A]
cmp eax,0x666
jge Label_1
mov ecx, 0x100
jmp lable_2
Label_1:
mov ecx, 0x300
Lable_2:
mov [var_zzz],ecx
Листинг 167
Чем же компилятору не понравился такой вариант? Между прочим, он даже короче. Короче-то, он короче, но содержит ветвления, - т.е. внеплановые изменения нормального хода выполнения программы. А ветвления отрицательно сказываются на производительности, хотя бы уже потому, что они приводят к очистке конвейера. Конвейер же в современных процессорах очень длинный и быстро его не заполнишь… Поэтому, избавление от ветвлений путем хитроумных математических вычислений вполне оправдано и горячо приветствуется. Попутно это усложняет анализ программы, защищая ее от всех посторонних личностей типа хакеров (т.е. нас с вами).
Впрочем, если хорошенько подумать…. Начнем пошагово исполнять программу, мысленно комментируя каждую строчку.
mov eax, [var_A]
; eax == var_A
xor ecx,ecx
; ecx=0;
cmp eax, 0x666
; if eax<0x666 { SF=1; OF=0} else {SF=0; OF=0}
setge cl
; if eax<0x666 (т.е. SF==1, OF ==0) cl=0 else cl=1
dec ecx
; if eax<0x666 ecx=-1 else ecx=0
and ecx, 0xFFFFFC00
; if eax<0x666 (т.е. ecx==-1) ecx=0xFFFFFC00 (-0x400) else ecx=0;
add ecx, 0x300
; if eax<0x666 (т.е. ecx=-0x400) ecx=0x100 else ecx=0x300;
mov [esp+0x66],ecx
Листинг 168
Получилось! Мы разобрались с этим алгоритмом и успешно реверсировали его! Теперь видно, что это довольно простой пример (в жизни будут нередко попадаться и более сложные). Но основная идея ясна, - если встречаются команда SETxx – держите нос по ветру: пахнет условными переходами! В вырожденных случаях SETxx может быть заменена на SBB
(вычитание с заемом). По этому поводу решим вторую задачу:
SUB EBX,EAX
SBB ECX,ECX
AND ECX,EBX
ADD EAX,ECX
Листинг 169
Что этот код делает? Какие-то сложные арифметические действия? Посмотрим…
SUB EBX,EAX
; if (EBX<EAX) SF=1 else SF=0
SBB ECX,ECX
; if (EBX<EAX) ECX=-1 else ECX=0
AND ECX,EBX
; if (EBX<EAX) ECX=EBX else ECX=0
ADD EAX,ECX
; if (EBX<EAX) EAX=EAX+(EBX-EAX) else EAX=EAX
Листинг 170
Раскрывая скобки в последнем выражении (мы ведь не забыли, что от EBX
отняли EAX?) получаем: if (EBX<EAX) EAX=EBX, - т.е. это классический алгоритм поиск минимума среди двух знаковых чисел. А вот еще один пример:
CMP EAX,1
SBB EAX,EAX
AND ECX,EAX
XOR EAX,-1
AND EAX,EBX
OR EAX,ECX
Листинг 171
Попробуйте решить его сами и только потом загляните в ответ:
CMP EAX,1
; if (EAX!=0) SF=0 else SF=1
SBB EAX,EAX
; if (EAX!=0) EAX=-1 else EAX=0
AND ECX,EAX
; if (EAX!=0) ECX=ECX else ECX=0
XOR EAX,-1
; if (EAX!=0) EAX=0 else EAX=-1
AND EAX,EBX
; if (EAX!=0) EAX=0 else EAX=EBX
OR EAX,ECX
; if (EAX!=0) EAX=ECX else EAX=EBX
Листинг 172
Да… после таких упражнений тов. Буль будет во сне сниться! Но… таковы уж издержки цивилизации. К слову сказать, подавляющее большинство компиляторов достаточно лояльно относятся к условным переходам и не стремятся к их тотальному изгнанию.Так что…. особо напрягаться при анализе оптимизированного кода не приходится (правда, к ручной оптимизации это не относится – профессиональные разработчики выкидывают переходы первую очередь).
Идентификация констант и смещений
"То, что для одного человека константа, для другого - переменная"
Алан Перлис "Афоризмы программирования"
Микропроцессоры серии 80x86 поддерживают операнды трех типов: регистр, непосредственное значение, непосредственный указатель. Тип операнда явно задается в специальном поле машинной инструкции, именуемом "mod", поэтому никаких проблем в идентификации типов операндов не возникает. Регистр – ну, все мы знаем, как выглядят регистры; указатель по общепринятому соглашению заключается в угловые скобки, а непосредственное значение записывается без них. Например:
MOV ECX, EAX; ß регистровый операнды
MOV ECX, 0x666; ß левый операнд регистровый, правый – непосредственный
MOV [0x401020], EAX ß левый операнд – указатель, правый – регистр
Кроме этого микропроцессоры серии 80x86 поддерживают два вида адресации памяти: непосредственную и косвенную. Тип адресации определяется типом указателя. Если операнд – непосредственный указатель, то и адресация непосредственна. Если же операнд-указатель – регистр, – такая адресация называется косвенной. Например:
MOV ECX,[0x401020] ß
непосредственная адресация
MOV ECX, [EAX] ß
косвенная адресация
Для инициализации регистрового указателя разработчики микропроцессора ввели специальную команду – "LEA REG, [addr]" – вычисляющую значение адресного выражения addr и присваивающую его регистру REG. Например:
LEA EAX, [0x401020] ; регистру EAX
присваивается значение указателя 0x401020
MOV ECX, [EAX] ; косвенная адресация – загрузка в ECX
двойного слова,
; расположенного по смещению 0x401020
Правый операнд команды LEA всегда представляет собой ближний (near) указатель. (Исключение составляют случаи использования LEA для сложения констант – подробнее об этом смотри в одноименном пункте). И все было бы хорошо…. да вот, оказывается, внутреннее представление ближнего указателя эквивалентно константе того же значения.
Отсюда – "LEA EAX, [0x401020]" равносильно "MOV EAX,0x401020". В силу определенных причин MOV значительно обогнал в популярности "LEA", практически вытеснив последнюю инструкцию из употребления.
Изгнание "LEA" породило фундаментальную проблему ассемблирования - "проблему OFFSETа". В общих чертах ее суть заключается в синтаксической неразличимости констант и смещений (ближних указателей). Конструкция "MOV EAX, 0x401020" может грузить в EAX и константу, равную 0x401020
(пример соответствующего Си-кода: a=0x401020), и указатель на ячейку памяти, расположенную по смещению 0x401020 (пример соответствующего Си-кода: a=&x). Согласитесь, a=0x401020 совсем не одно и тоже, что a=&x! А теперь представьте, что произойдет, если в заново ассемблированной программе переменная "x" в силу некоторых обстоятельств окажется расположена по иному смещению, а не 0x401020? Правильно, - программа рухнет, ибо указатель "a" по-прежнему указывает на ячейку памяти 0x401020, но здесь теперь "проживает" совсем другая переменная!
Почему переменная может изменить свое смещение? Основных причин тому две. Во-первых, язык ассемблера неоднозначен и допускает двоякую интерпретацию. Например, конструкции "ADD EAX, 0x66" соответствуют две машинные инструкции: "83 C0 66" и "05 66 00 00 00" длиной три и пять байт соответственно. Транслятор может выбрать любую из них и не факт, что ту же самую, которая была в исходной программе (до дизассемблирования). Неверно "угаданный" размер вызовет уплывание всех остальных инструкций, а вместе с ними и данных. Во-вторых, уплывание не замедлит вызвать модификация программы (разумеется, речь идет не о замене JZ
на JNZ, а настоящей адоптации или модернизации) и все указатели тут же "посыпаться".
Вернуть работоспособность программы помогает директива "offset". Если "MOV EAX, 0x401020" действительно
загружает в EAX
указатель, а не константу, по смещению 0x401020
следует создать метку, именуемую, скажем, "loc_401020", и "MOV EAX, 0x401020" заменить на "MOV EAX, offset loc_401020". Теперь указатель EAX связан не с фиксированным смещением, а с меткой!
А что произойдет, если предварить директивой offset
константу, ошибочно приняв ее за указатель? Программа откажет в работе или станет работать некорректно. Допустим, число 0x401020
выражало собой объем бассейна через одну трубу в который что-то втекает, а через другую – вытекает. Если заменить константу указателем, то объем бассейна станет равен… смещению метки в заново ассемблированной программе и все расчеты полетят к черту.
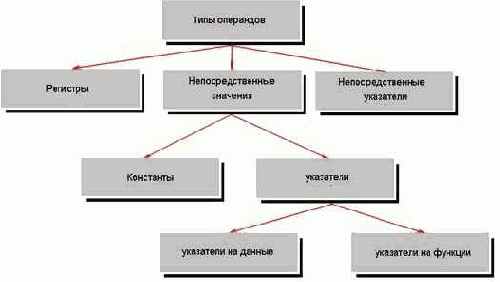
Рисунок 18 0х010 Типы операндов
Рисунок 19 0х011 Типы адресаций
Таким образом, очень важно определить типы всех непосредственных операндов, и еще важнее определить их правильно. Одна ошибка может стоить программе жизни (в смысле работоспособности), а в типичной программе тысячи и десятки тысяч операндов! Отсюда возникает два вопроса: а) как вообще определяют типы операндов? б) можно ли их определять автоматически (или на худой конец хотя бы полуавтоматически)?
Определение типа непосредственного операнда. Непосредственный операнд команды LEA
– всегда указатель (исключение составляют ассемблерные "извращения": чтобы сбить хакеров с толку в некоторых защитах LEA используется для загрузки константы).
Непосредственные операнды команд MOV и PUSH
могут быть как константами, так и указателями. Чтобы определить тип непосредственного операнда, необходимо проанализировать: как используется его значение в программе. Если для косвенной адресации памяти – это указатель, в противном случае – константа.
Например, встретили мы в тексте программы команду "MOV EAX, 0x401020" (см. рис 19), - что это такое: константа или указатель? Ответ на вопрос дает строка "MOV ECX, [EAX]", подсказывающая, что значение "0x401020" используется для косвенной адресации памяти, следовательно, непосредственный операнд – ни что иное, как указатель.
Существует два типа указателей – указатели на данные и указатели на функцию. Указатели на данные используются для извлечения значения ячейки памяти и встречаются в арифметических командах и командах пересылки (например – MOV, ADD, SUB). Указатели на функцию используются в командах косвенного вызова и, реже, в командах косвенного перехода – CALL и JMP соответственно.
Рассмотрим следующий пример:
main()
{
static int a=0x777;
int *b = &a;
int c=b[0];
}
Листинг 123 Константы и указатели
Результат его компиляции должен выглядеть приблизительно так:
main proc near
var_8 = dword ptr -8
var_4 = dword ptr -4
push ebp
mov ebp, esp
sub esp, 8
; Открываем кадр стека
mov [ebp+var_4], 410000h
; Загружаем в локальную переменную var_4 значение 0x410000
; Пока мы не можем определить его тип – константа это или указатель
mov eax, [ebp+var_4]
; Загружаем содержимое локальной переменной var_4 в регистр EAX
mov ecx, [eax]
; Загружаем в ECX содержимое ячейки памяти на которую указывает указатель EAX
; Ага! Значит, EAX все-таки указатель. Тогда локальная переменная var_4,
; откуда он был загружен, тоже указатель
; И непосредственный операнд 0x410000 – указатель, а не константа!
; Следовательно, чтобы сохранить работоспособность программы, создадим по
; смещению 0x410000 метку loc_410000, ячейку памяти, расположенную по этому
; адресу преобразует в двойное слово, и MOV
[ebp+var_4], 410000h заменим на:
; MOV [ebp+var_4], offset loc_410000
mov [ebp+var_8], ecx
; Присваиваем локальной переменной var_8 значение *var_4 ([offset loc_41000])
mov esp, ebp
pop ebp
; Закрываем кадр стека
retn
main endp
Листинг 124
Рассмотрим теперь пример с косвенным вызовом процедуры:
func(int a, int b)
{
return a+b;
};
main()
{
int (*zzz) (int a, int b) = func;
// Вызов функции происходит косвенно – по указателю zzz
zzz(0x666,0x777);
}
Листинг 125 Пример, демонстрирующий косвенный вызов процедуры
Результат компиляции должен выглядеть приблизительно так:
.text:0040100B main proc near ; CODE XREF: start+AFp
.text:0040100B
.text:0040100B var_4 dword ptr -4
.text:0040100B
.text:0040100B push ebp
.text:0040100C mov ebp, esp
.text:0040100C ; Открываем кадр стека
.text:0040100C
.text:0040100E push ecx
.text:0040100E ; Выделяем память для локальной переменной var_4
.text:0040100E
.text:0040100F mov [ebp+var_4], 401000h
.text:0040100F ; Присваиваем локальной переменной значение 0x401000
.text:0040100F ; Пока еще мы не можем сказать – константа это или смещение
.text:0040100F
.text:00401016 push 777h
.text:00401016 ; Заносим значение 0x777 в стек. Константа это или указатель?
.text:00401016 ; Пока сказать невозможно – необходимо проанализировать
.text:00401016 ; вызываемую функцию
.text:00401016
.text:0040101B push 666h
.text:0040101B ; Заносим в стек непосредственное значение 0x666
.text:0040101B
.text:00401020 call [ebp+var_4]
.text:00401020 ; Смотрите: косвенный вызов функции!
.text:00401020 ; Значит, переменная var_4 – указатель, раз так, то и
.text:00401020 ; присваиваемое ей непосредственное знаечние
.text:00401020 ; 0x401000 – тоже указатель!
.text:00401020 ; А по адресу 0x401000 расположена вызываемая функция!
.text:00401020 ; Окрестим ее каким-нибудь именем, например, MyFunc
и
.text:00401020 ; заменим mov
[ebp+var_4], 401000h на
.text:00401020 ; mov [ebp+var_4], offset MyFunc
.text:00401020 ; после чего можно будет смело модифицировать программу
.text:00401020 ; теперь-то она уже не "развалится"!
.text:00401020
.text:00401023 add esp, 8
.text:00401023
.text:00401026 mov esp, ebp
.text:00401028 pop ebp
.text:00401028 ; Закрываем кадр стека
.text:00401028
.text:00401029 retn
.text:00401029 main endp
.text:00401000 MyFunc proc near
.text:00401000 ; А вот и косвенно вызываемая функция MyFunc
.text:00401000 ; Исследуем ее, чтобы определить тип передаваемых ей
.text:00401000 ; непосредственных значений
.text:00401000
.text:00401000 arg_0 = dword ptr 8
.text:00401000 arg_4 = dword ptr 0Ch
.text:00401000 ; Ага, вот они, наши аргументы!
.text:00401000
.text:00401000 push ebp
.text:00401001 mov ebp, esp
.text:00401001 ; Открываем кадр стека
.text:00401001
.text:00401003 mov eax, [ebp+arg_0]
.text:00401003 ; Загружаем в EAX
значение аргумента arg_0
.text:00401003
.text:00401006 add eax, [ebp+arg_4]
.text:00401006 ; Складываем EAX
(arg_0) со значением аргумента arg_0
.text:00401006 ; Операция сложения намекает, что по крайней мере один из
.text:00401006 ; двух аргументов не указатель, т.к. сложение двух указателей
.text:00401006 ; бессмысленно (см. "Сложные случаи адресации")
.text:00401006
.text:00401009 pop ebp
.text:00401009 ; Закрываем кадр стека
.text:00401009
.text:0040100A retn
.text:0040100A ; Выходим, возвращая в EAX
сумму двух аргументов
.text:0040100A ; Как мы видим, ни здесь, ни в вызывающей функции,
.text:0040100A ; непосредственные значения 0x666 и 0x777 не использовались
.text:0040100A ; для адресации памяти – значит, это константы
.text:0040100A
.text:0040100A MyFunc endp
.text:0040100A
Листинг 126
Сложные случаи адресации или математические операции с указателями. Си/Си++ и некоторые языки программирования допускают выполнение над указателями различных арифметических операций, чем серьезно затрудняют идентификацию типов непосредственных операндов.
В самом деле, если бы такие операции с указателями были запрещены, то любая математическая инструкция, манипулирующая с непосредственным операндом, однозначно указывала на его константный тип.
К счастью, даже в тех языках, где это разрешено, над указателями выполняется ограниченное число математических операций. Так, совершенно бессмысленно сложение двух указателей, а уж тем более умножение или деление их друг на друга. Вычитание – дело другое. Используя тот факт, что компилятор располагает функции в памяти согласно порядку их объявления в программе, можно вычислить размер функции, отнимая ее указатель от указателя на следующую функцию (см. рис. 20). Такой трюк встречается в упаковщиках (распаковщиках) исполняемых файлов, защитах с самомодифицирующимся кодом, но в прикладных программах используется редко.
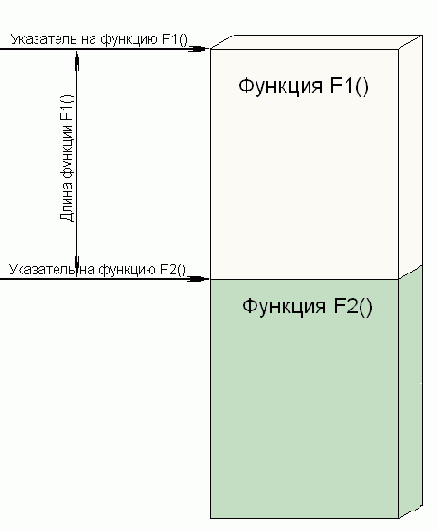
Рисунок 20 0х012 Использования вычитания указателей для вычисления размера функции [структуры данных].
Сказанное выше относилось к случаям "указатель" + "указатель", между тем указатель может сочетаться и с константой. Причем, такое сочетание настолько популярно, что микропроцессоры серии 80x86 даже поддерживают для этого специальную адресацию – базовую. Пусть, к примеру, имеется указатель на массив и индекс некоторого элемента массива. Очевидно, чтобы получить значение этого элемента, необходимо сложить указатель с индексом, умноженным на размер элемента.
Вычитание константы из указателя встречается гораздо реже, - этому не только соответствует меньший круг задач, но и сами программисты избегают вычитания, поскольку оно нередко приводит к серьезным проблемам. Среди начинающих популярен следующий примем – если им требуется массив, начинающийся с единицы, они, объявив обычный массив, получают на него указатель и… уменьшают его на единицу! Элегантно, не правда ли? Нет, не правда, - подумайте, что произойдет, если указатель на массив будет равен нулю. Правильно, - "змея укусит" свой хвост, и указатель станет оч-чень большим положительным числом.
Вообще-то, под Windows 9x\ NT массив гарантированно не может быть размещен по нулевому смещению, но не стоит привыкать к трюкам, привязанным к одной платформе, и не работающим на других.
"Нормальные" языки программирования запрещают смешение типов, и – правильно! Иначе такая чехарда получается, не чехарда даже, а еще одна фундаментальная проблема дизассемблирования – определение типов в комбинированных выражениях. Рассмотрим следующий пример:
MOV EAX,0x...
MOV EBX,0x...
ADD EAX,EBX
MOV ECX,[EAX]
Летающий Слонопотам! Сумма двух непосредственных значений используется для косвенной адресации. Ну, положим, оба они указателями быть не могут, - исходя из самых общих соображений, – никак не должны. Наверняка одно из непосредственных значений – указатель на массив (структуру данных, объект), а другое – индекс в этом массиве. Для сохранения работоспособности программы указатель необходимо заменить смещением метки, а вот индекс оставить без изменений (ведь индекс – это константа).
Как же различить: что есть что? Увы, - нет универсального ответа, а в контексте приведенного выше примера – это и вовсе невозможно!
Рассмотрим следующий пример:
MyFunc(char *a, int i)
{
a[i]='\n';
a[i+1]=0;
}
main()
{
static char buff[]="Hello,Sailor!";
MyFunc(&buff[0], 5);
}
Листинг 127 Пример, демонстрирующий определение типов в комбинированных выражениях
Результат компиляции Microsoft Visual C++ должен выглядеть так:
main proc near ; CODE XREF: start+AFp
push ebp
mov ebp, esp
; Открываем кадр стека
push 5
; Передаем функции MyFunc непосредственное значение 0x5
push 405030h
; Передаем функции MyFunc непосредственное значение 0x405030
call MyFunc
add esp, 8
; Вызываем MyFunc(0x405030, 0x5)
pop ebp
; Закрываем кадр стека
retn
main endp
MyFunc proc near ; CODE XREF: main+Ap
arg_0 = dword ptr 8
arg_4 = dword ptr 0Ch
push ebp
mov ebp, esp
; Открываем кадр стека
mov eax, [ebp+arg_0]
; Загружаем в EAX значение аргумента arg_0
; (arg_0 содержит непосредственное значение 0x405030)
add eax, [ebp+arg_4]
; Складываем EAX со значением аргумента arg_4 (он содержит значение 0x5)
; Операция сложения указывает на то, что, по крайней мере, один из них
; константа, а другой – либо константа, либо указатель
mov byte ptr [eax], 0Ah
; Ага! Сумма непосредственных значений используется для косвенной адресации
; памяти, значит, это константа и указатель. Но кто есть кто?
; Для ответа на этот вопрос нам необходимо понять смыл кода программы -
; чего же добивался программист сложением указателей?
; Предположим, что значение 0x5 – указатель. Логично?
; Да, вот не очень-то логично, - если это указатель, то указатель на что?
; Первые 64 килобайта адресного пространства Windows NT
заблокированы для
; "отлавливания" нулевых и неинициализированных указателей
; Ясно, что равным пяти указатель быть никак не может. Разве что программки
; использовал какой ни будь очень извращенный трюк.
; А если указатель – 0x401000? Выглядит правдоподобным легальным смещением...
; Кстати, что там у нас расположено? Секундочку...
; 00401000 db 'Hello,Sailor!',0
;
; Теперь все сходится – функции передан указатель на строку "Hello, Sailor!"
; (значение 0x401000) и индекс символа этой строки (значение 0x5),
; функция сложила указатель со строкой и записала в полученную ячейку символ \n
mov ecx, [ebp+arg_0]
; В ECX заносится значение аргумента arg_0
; (как мы уже установили это – указатель)
add ecx, [ebp+arg_4]
; Складываем arg_0 с arg_4 (как мы установили arg_4 – индекс)
mov byte ptr [ecx+1], 0
; Сумма ECX используется для косвенной адресации памяти, точнее ковенно-базовой
; т.к. к сумме указателя и индекса прибавляется еще и единица и в эту ячейку
; памяти заносится ноль
; Наши выводы подтверждаются – функции передается указатель на строку и
; индекс первого "отсекаемого" символа строки
; Следовательно для сохранения работоспособности программы по смещению 0x401000
; необходимо создать метку "loc_s0", а PUSH 0x401000 в вызывающей функции
; заменить
на PUSH offset loc_s0
pop ebp
retn
MyFunc endp
Листинг 128
А теперь откомпилируем тот же самый пример компилятором Borland C++ 5.0 и сравним, чем он отличается от Microsoft Visual C++ (ниже для экономии места приведен код одной лишь функции MyFunc, функция main – практически идентична предыдущему примеру):
MyFunc proc near ; CODE XREF: _main+Dp
push ebp
; Отрываем пустой кадр стека – нет локальных переменных
mov byte ptr [eax+edx], 0Ah
; Ага, Borland C++ сразу сложил указатель с константой непосредственно в
; адресном выражении!
; Как определить какой из регистров константа, а какой указатель?
; Как и в предыдущем случае необходимо проанализировать их значение.
mov byte ptr [eax+edx+1], 0
mov ebp, esp
pop ebp
; Закрытие кадра стека
retn
MyFunc endp
Листинг 129
Порядок индексов и указателей. Открою маленький секрет – при сложении указателя с константой большинство компиляторов на первое место помещают указатель, а на второе – константу, каким бы ни было их расположение в исходной программе.
То есть, выражения "a[i]", "(a+i)[0]", "*(a+i)" и "*(i+a)" компилируются в один и тот же код! Даже если извратиться и написать так: "(0)[i+a]", компилятор все равно выдвинет 'a' на первое место. Что это – ослиная упрямость, игра случая или фича? Ответ до смешного прост – сложение указателя с константой дает указатель! Поэтому – результат вычислений всегда записывается в переменную типа "указатель".
Вернемся к последнему рассмотренному примеру, применив для анализа наше новое правило:
mov eax, [ebp+arg_0]
; Загружаем в EAX значение аргумента arg_0
; (arg_0 содержит непосредственное значение 0x405030)
add eax, [ebp+arg_4]
; Складываем EAX со значением аргумента arg_4 (он содержит значение 0x5)
; Операция сложения указывает на то, что, по крайней мере, один из них
; константа, а другой – либо константа, либо указатель
mov byte ptr [eax], 0Ah
; Ага! Сумма непосредственных значений используется для косвенной адресации
; памяти, значит, это константа и указатель. Но кто из них кто?
; С большой степенью вероятности EAX – указатель, т.к. он стоит на первом
; месте, а var_4 – индекс, т.к. он стоит на втором
Листинг 130
Использование LEA для сложения констант. Инструкция LEA
широко используется компиляторами не только для инициализации указателей, но и сложения констант. Поскольку, внутренне представление констант и указателей идентично, результат сложения двух указателей идентичен сумме тождественных им констант. Т.е. "LEA EBX, [EBX+0x666] == ADD EBX, 0x666", однако по своим функциональным возможностям LEA значительно обгоняет ADD. Вот, например, "LEA ESI, [EAX*4+EBP-0x20]", - попробуйте то же самое "скормить" инструкции ADD!
Встретив в тексте программы команду LEA, не торопитесь навешивать на возвращенное ею значение ярлык "указатель", - с не меньшим успехом он может оказаться и константой! Если "подозреваемый" ни разу не используется в выражении косвенной адресации – никакой это не указатель, а самая настоящая константа!
"Визуальная" идентификация констант и указателей. Вот несколько приемов, помогающих отличить указатели от констант.
1) В 32-разрядных Windows программах указатели могут принимать ограниченный диапазон значений. Доступный процессорам регион адресного пространства начинается со смещения 0x1.00.00
и простирается до смещения 0х80.00.00.00, а Windows 9x/Me и того меньше – от 0x40.00.00
до 0х80.00.00.00. Поэтому, все непосредственные значения, меньшие 0x1.00.00
и больше 0x80.00.00
представляют собой константы, а не указатели. Исключение составляет число ноль, обозначающее нулевой указатель. {>>> сноска некоторые защитные механизмы непосредственно обращаются к коду операционной системы, расположенному выше адреса 0x80.00.00}.
2) Если непосредственное значение смахивает на указатель – посмотрите, на что он указывает. Если по данному смещению находится пролог функции или осмысленная текстовая строка – скорее всего мы имеем дело с указателем, хотя может быть, это – всего лишь совпадение.
3) Загляните в таблицу перемещаемых элементов (см. "Шаг четвертый Знакомство с отладчиком :: Способ 0 Бряк на оригинальный пароль"). Если адрес "подследственного" непосредственного значения есть в таблице – это, несомненно, указатель. Беда в том, что большинство исполняемых файлов – неперемещаемы, и такой прием актуален лишь для исследования DLL (а DLL перемещаемы по определению).
К слову сказать, дизассемблер IDA Pro использует все три описанных способа для автоматического опознавания указателей. Подробнее об этом рассказывается в моей книге "Образ мышления – дизассемблер IDA" (глава "Настройки", стр. 408).
___Идентификация нулевых указателей. Нулевой указатель – это указатель, который ни на что не указывает. Чаще…. В языке Си/Си++ нулевые указатели выражаются константой 0, а в Паскале – ключевым словом nil, однако, внутреннее представление нулевого указателя не обязательно должно быть нулевым.
___Индекс – тоже указатель! Рассмотри
___16-разярднй код.
__не должно быть нераспознанных непосредсенных типов
Идентификация конструктора и деструктора
"то, что не существует в одном тексте (одном возможном мире), может существовать в других текстах (возможных мирах)"
тезис семантики возможных миров
Конструктор, в силу своего автоматического вызова при создании нового экземпляра объекта, – первая по счету вызываемая функция объекта. Так какие сложности в его идентификации? Камень преткновения в том, что конструктор факультативен, т.е. может присутствовать в объекте, а может и не присутствовать. Поэтому, совсем не факт, что первая вызываемая функция – конструктор!
Заглянув в описание языка Си++, можно обнаружить, что конструктор не возвращает никакого значения, что нехарактерно для обычных функций, однако, все же не настолько редко встречается, чтобы однозначно идентифицировать конструктор. Как же тогда быть?
Выручает то обстоятельство, что по стандарту конструктор не должен автоматически вызывать исключения, даже если отвести память под объект не удалось. Реализовать это требование можно множеством различных способов, но все, виденные мной компиляторы, просто помещают перед вызовом конструктора проверку на нулевой указатель, передавая ему управление только при удачном выделении памяти для объекта. Напротив, все остальные функции объекта вызываются всегда – даже при неуспешном выделении памяти. Вернее, пытаются вызываться, но нулевой указатель (возращенный при ошибке отведения памяти) при первой же попытке обращения вызывает исключение, передавая "бразды правления" обработчику соответствующей исключительной ситуации.
Таким образом, функция, "окольцованная" проверкой нулевого указателя, и есть конструктор, а ни что иное. Теоретически, впрочем, подобная проверка может присутствовать и при вызове других функций, конструктором не являющихся, но… во всяком случае мне на практике с каким еще не приходилось встречаться.
Деструктор, как и конструктор факультативен, т.е. последняя вызываемая функция объекта не факт, что деструктор. Тем не менее, отличить деструктор от любой другой функции очень просто – он вызывается только при результативном создании объекта (т.е.
успешном выделении памяти) и игнорируется в противном случае. Это – документированное свойство языка, следовательно, обязательное к реализации всеми компиляторами. Таким образом, в код помещается такое же "кольцо", как и у конструктора, но никакой путаницы не возникает, т.к. конструктор вызывается всегда первым (если он есть), а деструктор – последним.
Особый случай представляет объект, целиком состоящий из одного конструктора (или деструктора) – попробуй, разберись, с чем мы имеем дело. И разобраться можно! За вызовом конструктора практически всегда присутствует код, обнуляющий this в случае неудалого выделения памяти, - а у деструктора этого нет! Далее – деструктор обычно вызывается не непосредственно из материнской процедуры, а из функции-обертки, вызывающей помимо деструктора и оператор delete, освобождающий занятую объектом память. Так, что отличить конструктор от деструктора вполне можно!
Давайте, для лучшего уяснения сказанного рассмотрим следующий пример:
#include <stdio.h>
class MyClass{
public:
MyClass(void);
void demo(void);
~MyClass(void);
};
MyClass::MyClass()
{
printf("Constructor\n");
}
MyClass::~MyClass()
{
printf("Destructor\n");
}
void MyClass::demo(void)
{
printf("MyClass\n");
}
main()
{
MyClass *zzz = new MyClass;
zzz->demo();
delete zzz;
}
Листинг 38 Демонстрация конструктора и деструктора
Результат его компиляции в общем случае должен выглядеть так:
Constructor proc near ; CODE XREF: main+11p
; функция конструктора. То, что это именно конструктор можно понять из реализации
; его вызова (см. main)
push esi
mov esi, ecx
push offset aConstructor ; "Constructor\n"
call printf
add esp, 4
mov eax, esi
pop esi
retn
Constructor endp
Destructor proc near ; CODE XREF: __destructor+6p
; функция деструктора. То, что это именно деструктор, можно понять из реализации
; его вызова (см. main)
push offset aDestructor ; "Destructor\n"
call printf
pop ecx
retn
Destructor endp
demo proc near ; CODE XREF: main+1Ep
; обычная
функия demo
push offset aMyclass ; "MyClass\n"
call printf
pop ecx
retn
demo endp
main proc near ; CODE XREF: start+AFp
push esi
push 1
call ??2@YAPAXI@Z ; operator new(uint)
add esp, 4
; выделяем память для нового объекта
; точнее, пытаемся это сделать
test eax, eax
jz short loc_0_40105A
; Проверка успешности выделения памяти для объекта.
; Обратите внимание: куда направлен jump.
; Он направлен на инструкцию XOR ESI,ESI, обнуляющую указатель на объект –
; при попытке использования нулевого указателя возникнет исключение,
; но конструктор не должен вызывать исключение даже если память под объект
; отвести не удалось.
; Поэтому, конструктор получает управление только при успешном отводе памяти!
; Следовательно, функция, находящаяся до XOR ESI,ESI, и есть конструктор!!!
; И мы сумели надежно идентифицировать ее.
mov ecx, eax
; готовим указатель this
call Constructor
; эта функция – конструктор, т.к. вызывается только при удачном отводе памяти
mov esi, eax
jmp short loc_0_40105C
loc_0_40105A: ; CODE XREF: main+Dj
xor esi, esi
; обнуляем указатель на объект, чтобы вызвать исключение при попытке его
; использования
; Внимание: конструктор никогда не вызывает исключения, поэтому,
; нижележащая функция гарантированно не является конструктором
loc_0_40105C: ; CODE XREF: main+18j
mov ecx, esi
; готовим указатель this
call demo
; вызываем обычную функцию объекта
test esi, esi
jz short loc_0_401070
; проверка указателя this на NULL. Деструктор вызываться только в том случае
; если память под объект была отведена (если же она не была отведена
; освобождать особо нечего)
; таким образом, следующая функция – именно деструктор, а не что-нибудь еще
push 1
; количество байт для освобождения (необходимо для delete)
mov ecx, esi
; готовим указатель this
call __destructor
; вызываем деструктор
loc_0_401070: ; CODE XREF: main+25j
pop esi
retn
main endp
__destructor proc near ; CODE XREF: main+2Bp
; функция деструктора. Обратите внимание, что деструктор обычно вызывается
; из той же функции, что и delete (хотя так бывает и не всегда, но очень часто)
arg_0 = byte ptr 8
push ebp
mov ebp, esp
push esi
mov esi, ecx
call Destructor
; вызываем функцию деструктора, определенную пользователем
test [ebp+arg_0], 1
jz short loc_0_40109A
push esi
call ??3@YAXPAX@Z ; operator delete(void *)
add esp, 4
; освобождаем память, ранее выделенную объекту
loc_0_40109A: ; CODE XREF: __destructor+Fj
mov eax, esi
pop esi
pop ebp
retn 4
__destructor endp
Листинг 39
::объекты в автоматической памяти или когда конструктор/деструктор идентифицировать невозможно. Если объект размещается в стеке (автоматической памяти), то никаких проверок успешности ее выделения не выполняется и вызов конструктора становится неотличим от вызова остальных функций. Аналогичная ситуация и с деструктором – стековая память автоматически освобождается по завершению функции, а вместе с ней умирает и сам объект безо всякого вызова delete (delete применяется только для удаления объектов из кучи).
Чтобы убедиться в этом, модифицируем функцию main нашего предыдущего примера следующим образом:
main()
{
MyClass zzz;
zzz.demo();
}
Листинг 40
Результат компиляции в общем случае должен выглядеть так:
main proc near ; CODE XREF: start+AFp
var_4 = byte ptr -4
; локальная переменная zzz – экземпляр объекта MyClass
push ebp
mov ebp, esp
push ecx
lea ecx, [ebp+var_4]
; подготавливаем указатель this
call constructor
; вызываем конструктор, как и обычную функцию!
; долгаться, что это конструктор можно разве что по его содержимому
; (обычно конструктор инициализирует объект), да и то неуверенно
lea ecx, [ebp+var_4]
call demo
; вызываем функцию demo, - обратите внимание, ее вызов ничем не отличается
; от вызова конструктора!
lea ecx, [ebp+var_4]
call destructor
; вызываем деструктор – его вызов, как мы уже поняли, ничем
; характерным не отмечен
mov esp, ebp
pop ebp
retn
main endp
Листинг 41
::идентификация конструктора/деструктора в глобальных объектах. Глобальные объекты (так же называемые статическими объектами) размешаются в сегменте данных еще на стадии компиляции. Стало быть, ошибки выделения памяти в принципе невозможны и, выходит, что по аналогии со стековыми объектами, надежно идентифицировать конструктор/деструктор и здесь нельзя? А вот и нет!
Глобальный объект, в силу свой глобальности, доступен из многих мест программы, но его конструктор должен вызываться лишь однажды. Как можно это обеспечить? Конечно, возможны самые различные варианты реализации, но большинство компиляторов идут по простейшему пути, используя для этой цели глобальную переменную-флаг, изначально равную нулю, а перед первым вызовом конструктора увеличивающуюся на единицу (в более общем случае устанавливающуюся в TRUE). При повторных итерациях остается проверить – равен ли флаг нулю, и если нет – пропустить вызов конструктора. Таким образом, конструктор вновь "окольцовывается" условным переходом, что позволяет его безошибочно отличить ото всех остальных функций.
С деструктором еще проще – раз объект глобальный, то он уничтожается только при завершении программы. А кто это может отследить кроме поддержки времени исполнения? Специальная функция, такая как _atexit, принимает на вход указатель на конструктор, запоминает его и затем вызывает при возникновении в этом необходимости.
Интересный момент - _atexit (или что там используется в вашем конкретном случае) должна быть вызвана лишь однократно (надеюсь, понятно почему?). И, чтобы не вводить еще один флаг, она вызывается сразу же после вызова конструктора! На первый взгляд объект может показаться состоящим из одних конструктора/деструктора, но это не так! Не забывайте, что _atexit не передает немедленно управление на код деструктора, а только запоминает его указатель для дальнейшего использования!
Таким образом, конструктор/деструктор глобального объекта очень просто идентифицировать, что и доказывает следующий пример:
main()
{
static MyClass zzz;
zzz.demo();
}
Листинг 42
Результат его компиляции в общем случае должен выглядеть так:
main proc near ; CODE XREF: start+AFp
mov cl, byte_0_4078E0 ; флаг инициализации экземпляра объекта
mov al, 1
test al, cl
; объект инициализирован?
jnz short loc_0_40106D
; --> да, инициализирован, - не вызываем конструктор
mov dl, cl
mov ecx, offset unk_0_4078E1 ; экземляр объекта
; готовим указатель this
or dl, al
; устанавливаем флаг инициализации в TRUE
; и вызываем конструктор
mov byte_0_4078E0, dl ; флаг инициализации экземпляра объекта
call constructor
; Вызов конструктора.
; Обратите внимание, что если экземпляр объекта уже инициализирован
; (см. проверку выше) конструктор не вызывается.
; Таким образом, его очень легко отождествить!
push offset thunk_destructo
call _atexit
add esp, 4
; Передаем функции _atexit указатель на деструктор,
; который она должна вызвать по завершении программы
loc_0_40106D: ; CODE XREF: main+Aj
mov ecx, offset unk_0_4078E1 ; экземпляр
объекта
; готовим указатель this
jmp demo
; вызываем demo
main endp
thunk_destructo: ; DATA XREF: main+20o
; переходник к функции-деструктору
mov ecx, offset unk_0_4078E1 ; экземпляр объекта
jmp destructor
byte_0_4078E0 db 0 ; DATA XREF: mainr main+15w
; флаг инициализации экземпляра объекта
unk_0_4078E1 db 0 ; ; DATA XREF: main+Eo main+2Do ...
; экземпляр объекта
Листинг 43
Аналогичный код генерирует и Borland C++. Единственное отличие – более хитрый вызов деструктора. Вызовы всех деструкторов помещены в специальную процедуру, которая выдает себя тем, что обычно располагается перед библиотечными функциями (или в непосредственной близости от них), так что идентифицировать ее очень легко. Смотрите сами:
_main proc near ; DATA XREF: DATA:00407044o
push ebp
mov ebp, esp
cmp ds:byte_0_407074, 0 ; флаг инициализации объекта
jnz short loc_0_4010EC
; Если объект уже инициализирован – конструктор не вызывается
mov eax, offset unk_0_4080B4 ; Экземпляр объекта
call constructor
inc ds:byte_0_407074 ; флаг инициализации объекта
; Увеличиваем флаг на единицу, возводя его в TRUE
loc_0_4010EC: ; CODE XREF: _main+Aj
mov eax, offset unk_0_4080B4 ; Экземляр
объекта
call demo
; Вызов
функции demo
xor eax, eax
pop ebp
retn
_main endp
call_destruct proc near ; DATA XREF: DATA:004080A4o
; Эта функция содержит в себе вызовы всех деструкторов глобальных объектов,
; поскольку, вызов каждого деструктора "окольцован" проверкой флага инициализации,
; эту функцию легко идентифицировать – только она содержит подобный "калечный код"
; (вызовы конструкторов обычно разбросаны по всей программе)
push ebp
mov ebp, esp
cmp ds:byte_0_407074, 0 ; флаг инициализации объекта
jz short loc_0_401117
; объект был инициализирован?
mov eax, offset unk_0_4080B4 ; Экземпляр объекта
; готовим указатель this
mov edx, 2
call destructor
; вызываем деструктор
loc_0_401117: ; CODE XREF: call_destruct+Aj
pop ebp
retn
call_destruct endp
Листинг 44
:: виртуальный деструктор. Деструктор тоже может быть виртуальным! А почему бы и нет? Это бывает полезно, когда экземпляр производного класса удаляется через указатель на базовый объект. Поскольку, виртуальные функции связаны с классом объекта, а не с классом указателя, то вызывается виртуальный деструктор, связанный с типом объекта, а не с типом указателя. Впрочем, эти тонкости относятся к непосредственному программированию, а исследователей в первую очередь интересует: как идентифицировать виртуальный деструктор. О, это просто – виртуальный деструктор совмещает в себе свойства обычного деструктора и виртуальной функции (см. "Идентификация виртуальных функций").
::виртуальный конструктор. Виртуальный конструктор?! А что, разве есть такой? Ничего подобного стандартный Си++ не поддерживает. Непосредственно не поддерживает. И, когда виртуальный конструктор позарез требуется программистом (впрочем, бывает это лишь в весьма экзотических случаях), они прибегают к ручной эмуляции некоторого его подобия. В специально выделенную для этих целей виртуальную функцию (не конструктор!) помещается приблизительно следующий код: "return new имя класса (*this)" или "return new имя класса (*this)". Этот трюк кривее, чем бумеранг, но… он работает. Разумеется, существуют и другие решения.
Подробное их обсуждение далеко выходит за рамки данной книги и требует глубоко знания Си++ (гораздо более глубокого, чем у рядового разработчика), к тому же это заняло бы слишком много места… но едва ли оказалось интересно рядовому читателю.
Итак, идентификация виртуального конструктора в силу отсутствия самого понятия – в принципе невозможна. Его эмуляция насчитывает десятки решений (если не больше), – попробуй-ка, перечисли их все! Впрочем, этого и не нужно делать – в большинстве случаев виртуальные конструкторы представляют собой виртуальные функции, принимающие в качестве аргумента указатель this и возвращающие указатель на новый объект.
Не слишком- то надежно для идентификации, но все же лучше, чем ничего.
::конструктор раз, конструктор два… Количество конструкторов объекта может быть и более одного (и очень часто не только может, но и бывает). Однако это никак не влияет на анализ. Сколько бы конструкторов ни присутствовало, – для каждого экземпляра объекта всегда вызывается только один, выбранный компилятором в зависимости от формы объявления объекта. Единственная деталь – различные экземпляры объекта могут вызывать различные конструкторы – будьте внимательны!
::а зачем козе баян или внимание: пустой конструктор. Некоторые ограничения конструктора (в частности, отсутствие возвращаемого значения) привели к появлению стиля программирования "пустой конструктор". Конструктор умышленно оставляется пустым, а весь код инициализации помещается в специальную функцию-член, как правило, называемую Init. Обсуждение сильных и слабых сторон такого стиля – предмет отдельного разговора, никаким боком не относящегося к данной книге. Исследователям достаточно знать – такой стиль есть и активно используется не только отдельными индивидуальными программистами, но и крупнейшими компаниями-гигантами (например, той же Microsoft). Поэтому, встретив вызов пустого конструктора, – не удивляйтесь, - это нормально, и ищите функцию инициализации среди обычных членов.